
AnythingLLM是简单易用的一体化AI应用程序,可以无需编码或基础架构问题就实现检索增强生成(RAG)、AI智能体(AI Agents)等多种功能。

AnythingLLM由Mintplex Labs, Inc开发,由Timothy Carambat创立,并在2022年夏季参与了YCombinator孵化器项目。
为什么使用AnythingLLM?
一个零设置(zero-setup)、私有(private)且一体化的AI应用程序,可以在一个地方使用本地LLMs、RAG和AI智能体,而无需痛苦的开发人员设置。
一、安装AnythingLLM
AnythingLLM是一个“single-player”应用程序,可以安装在任何Mac、Windows或Linux操作系统上,实现本地LLMs、RAG和代理(Agents),几乎不需要配置,同时保持完全的隐私。
可以将AnythingLLM安装为桌面应用程序,或者使用Docker在本地自托管,也可以使用Docker在云端托管。
在官网下载.dmg文件后,需要双击打开生成的安装文件。

一旦dmg文件打开,可以将AnythingLLM的标志拖入Applications文件夹。
安装完成后,将在“应用程序”文件夹中找到AnythingLLM,也可以使用cmd + 空格键并输入AnythingLLM来运行。
二、简单配置AnythingLLM
下载AnythingLLM之后开始进入启动的配置阶段,开始之前请确保 ollama serve 运行,或者终端执行 ollama run xxx(任何一个模型)。
% curl http://localhost:11434
Ollama is running%
本地大模型:选择 Ollama,如图所示:
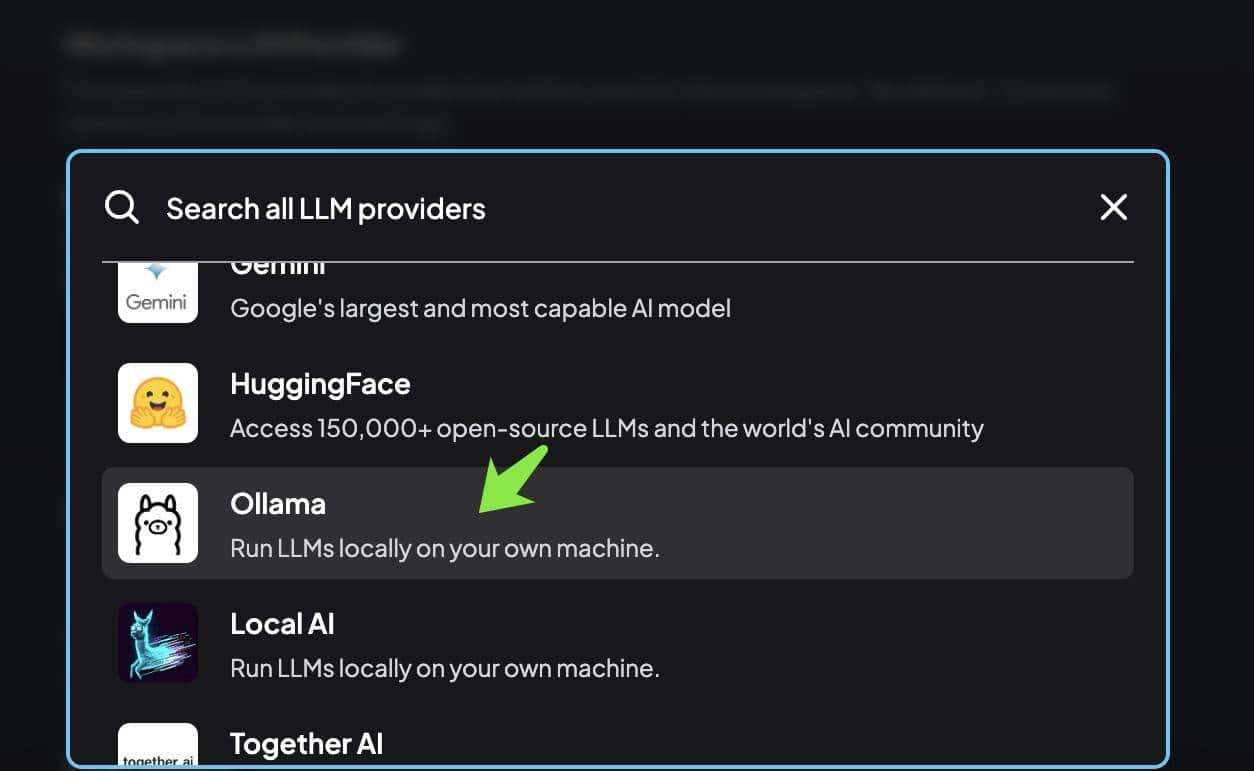
填入 Ollama 的 http://127.0.0.1:11434 端口,然后选择已经下载的模型。
当然也可以使用 OpenAI,使用更强劲的云端模型,提供基础模型支持。但这样的话,就不是完全本地化的私有部署了。
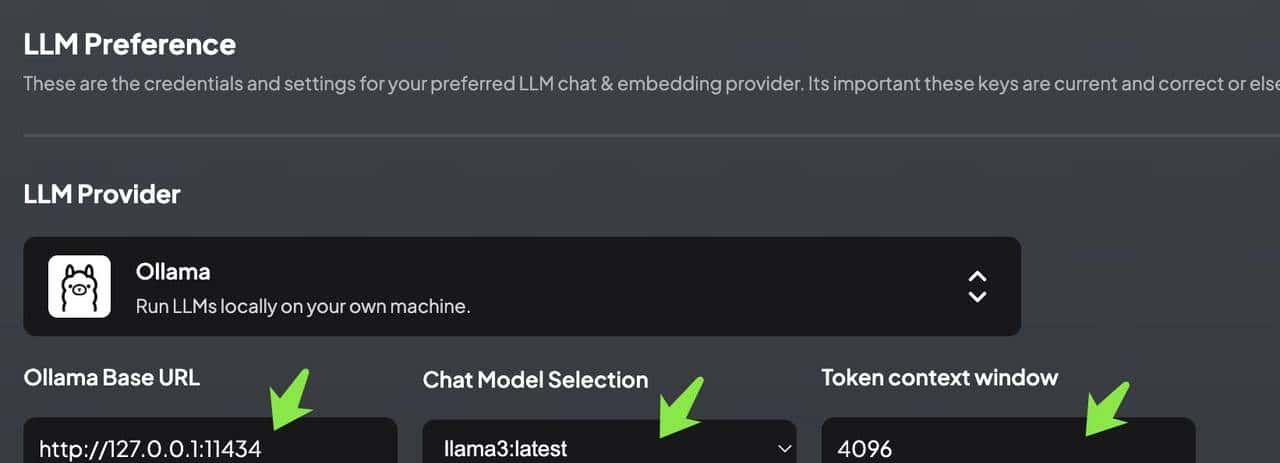
如图所示,设置Chat model 为之前已经下载的 llama3 模型,Token context window 设置为 4096。
Embedding 配置:嵌入模型也可以参考下图进行设置。
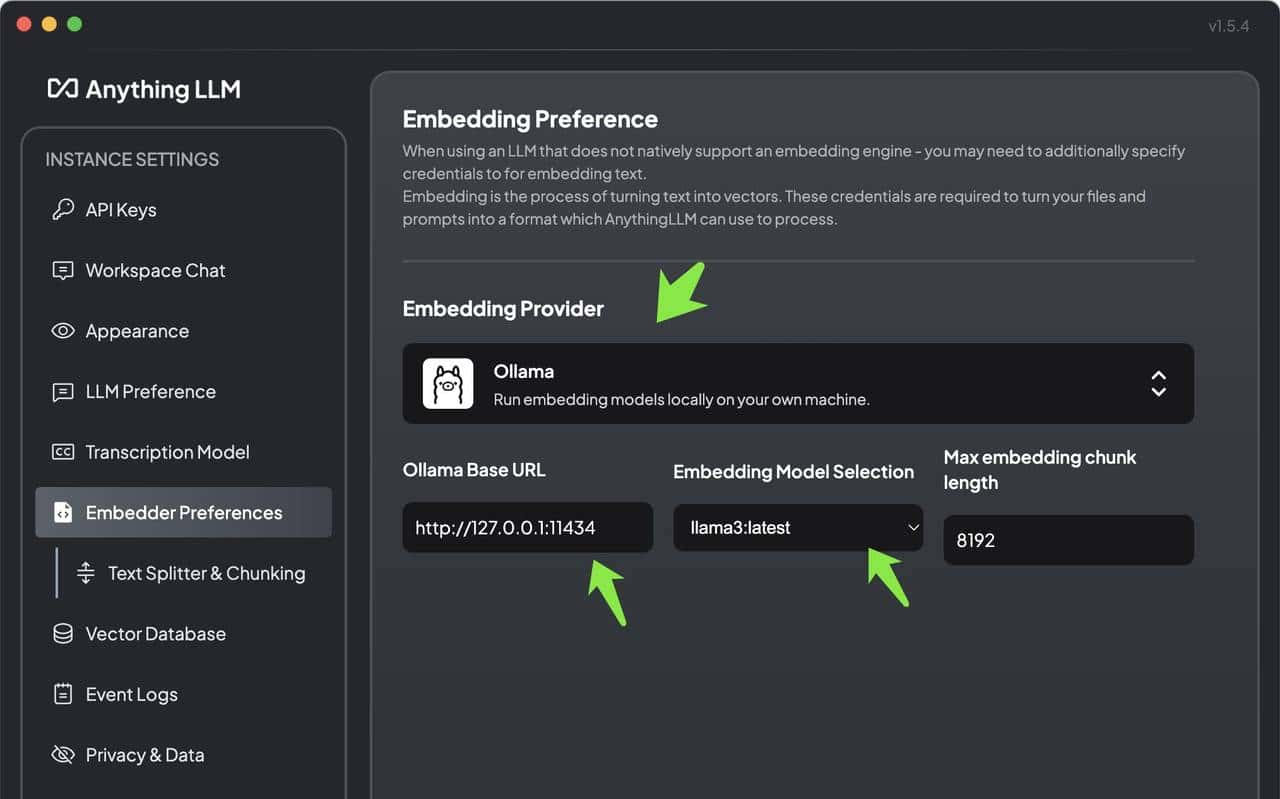
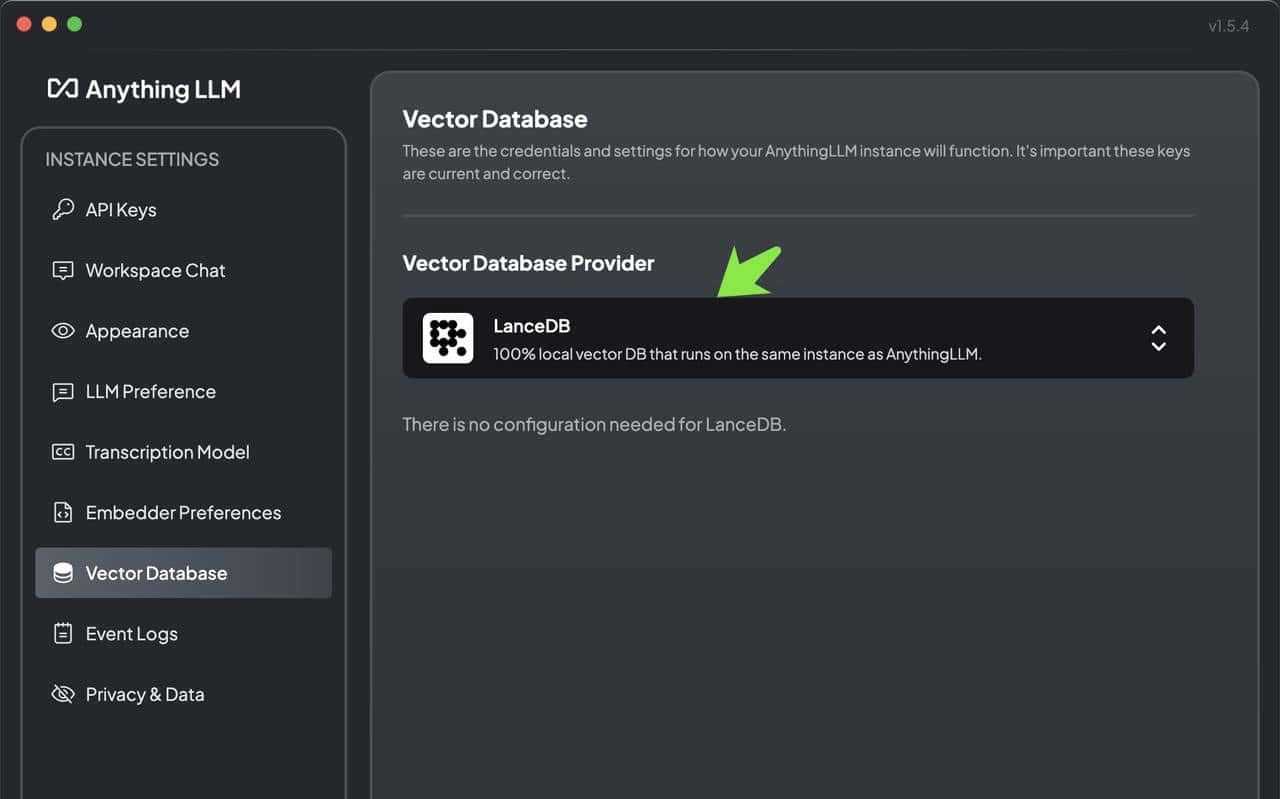
向量数据库配置:AnythingLLM 默认使用内置的向量数据库 LanceDB。这是一款无服务器向量数据库,可嵌入到应用程序中,支持向量搜索、全文搜索和 SQL。我们也可以选择 Chroma、Milvus、Pinecone 等向量数据库。

三、导入外部 Documents
AnythingLLM 可以支持 PDF、TXT、DOCX 等文档,可以提取文档中的文本信息,经过嵌入模型(Embedding Models),保存在向量数据库中,并通过一个简单的 UI 界面管理这些文档。
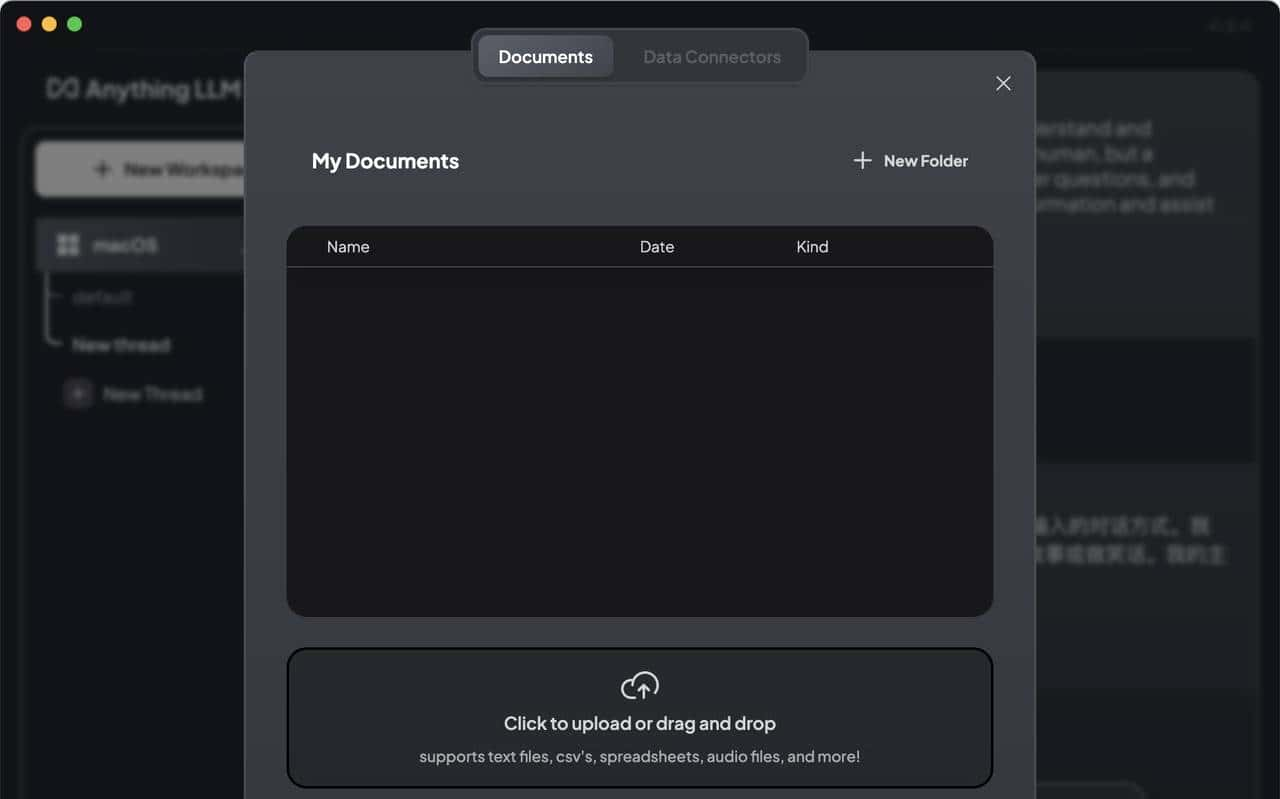
AnythingLLM 既可以上传文档,也可以抓取网页信息。
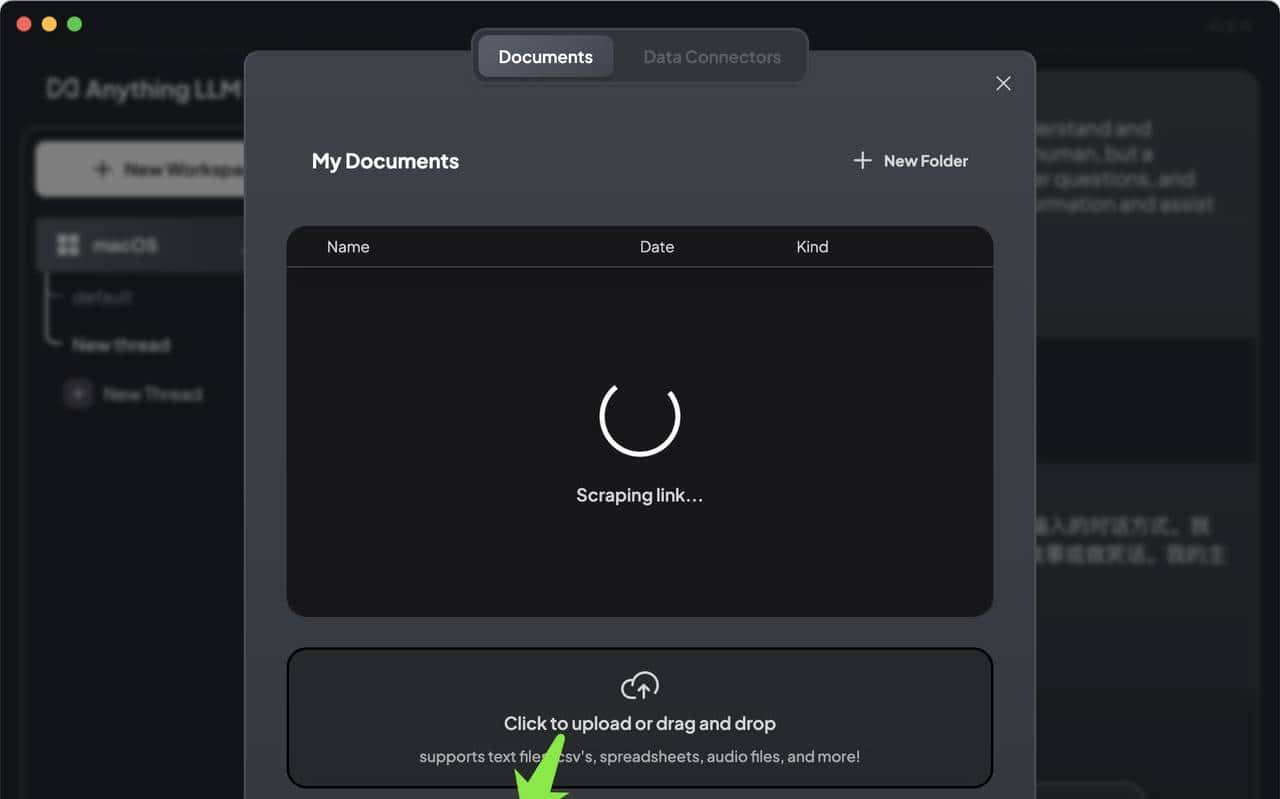
下面试试抓取一个github 网页,如图所示:
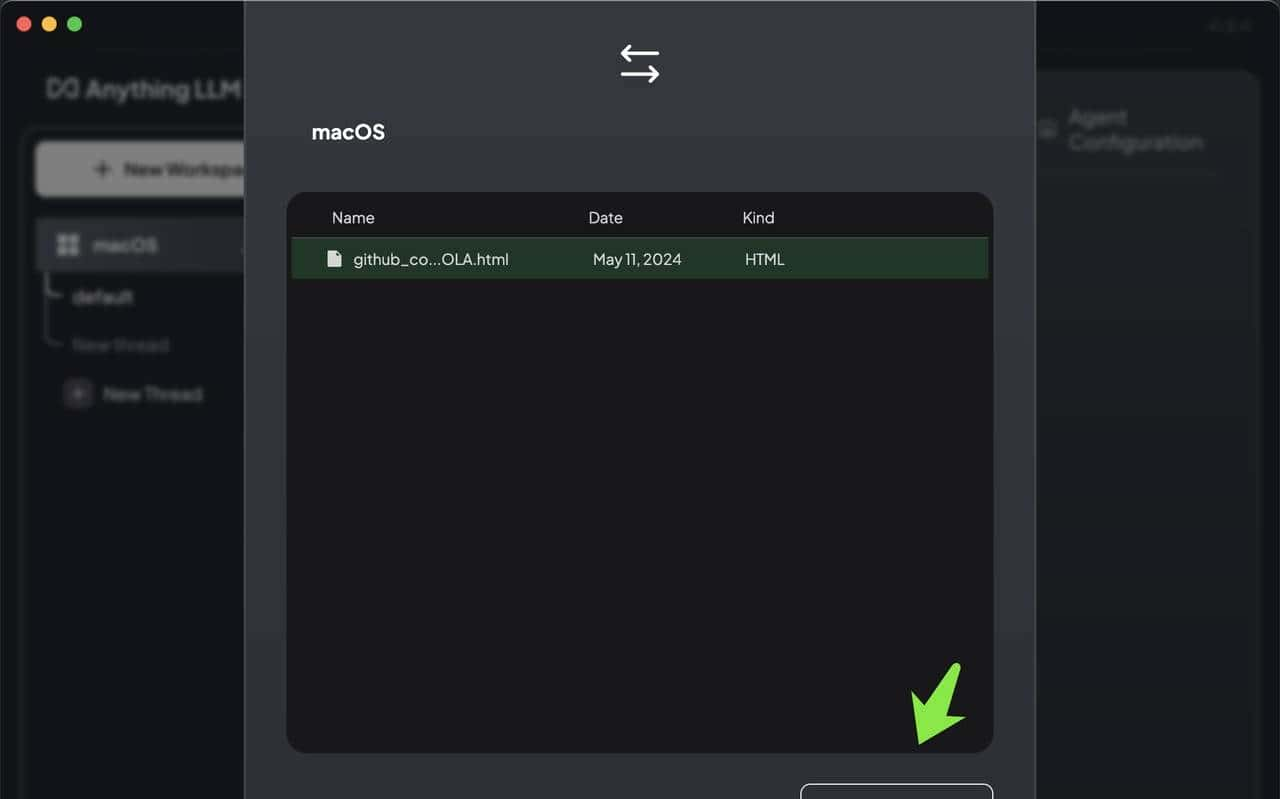
抓取完成后,点击Move to Workspace 按钮,移动到工作区,如图所示:

在指定的工作区中,点击Save and Embed 按钮,保存到向量数据,这里需要一点时间。
另外,还可以 pin 文档到提示窗口中。
当在AnythingLLM中固定(pin)一个文档时,我们将把整个文档内容注入到提示窗口中,以便LLM能够充分理解。
这在处理大上下文模型或对其知识库至关重大的小文件时效果最好。
如果无法从AnythingLLM的默认设置中获得所需的答案,那么固定文档是获取更高质量答案的绝佳方法。

四、开始聊天
简单开启一个会话,如图所示:
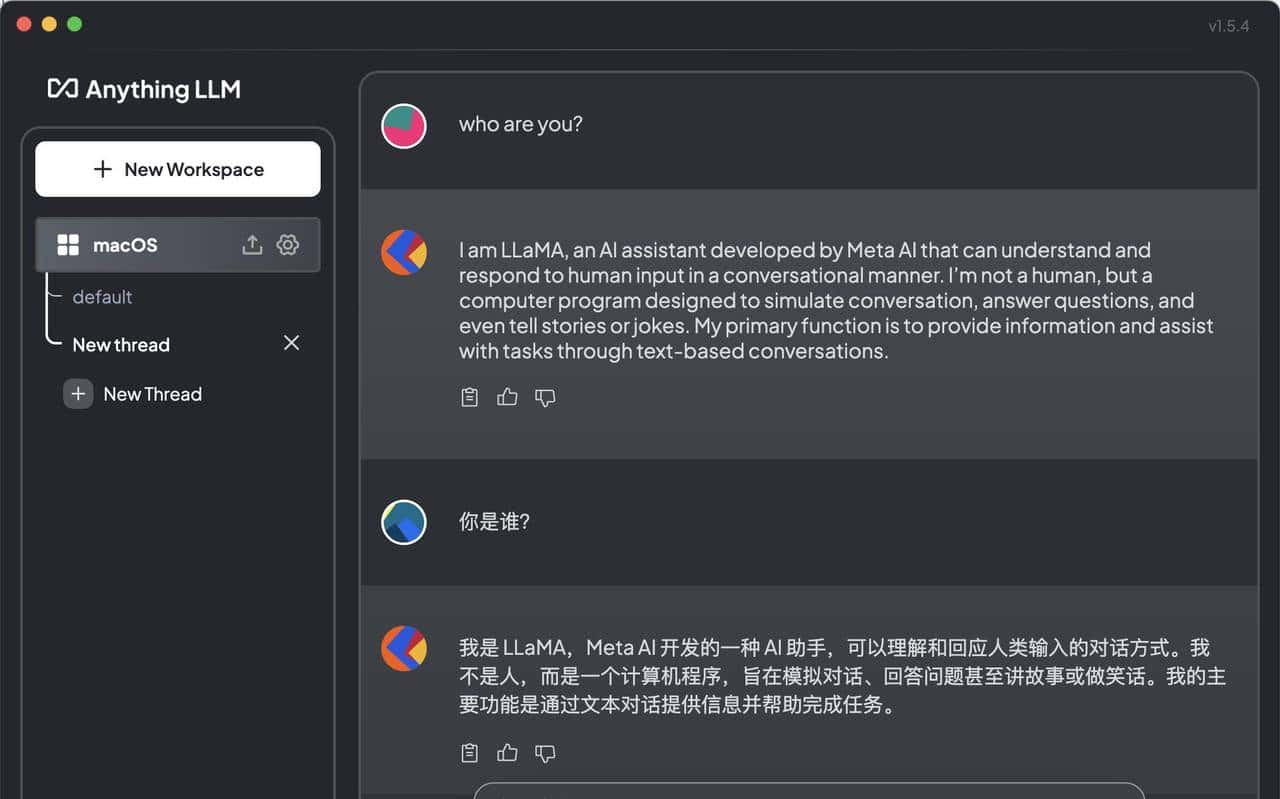
输入针对 documents 相关的话题,看看模型的输出结果,如图所示:
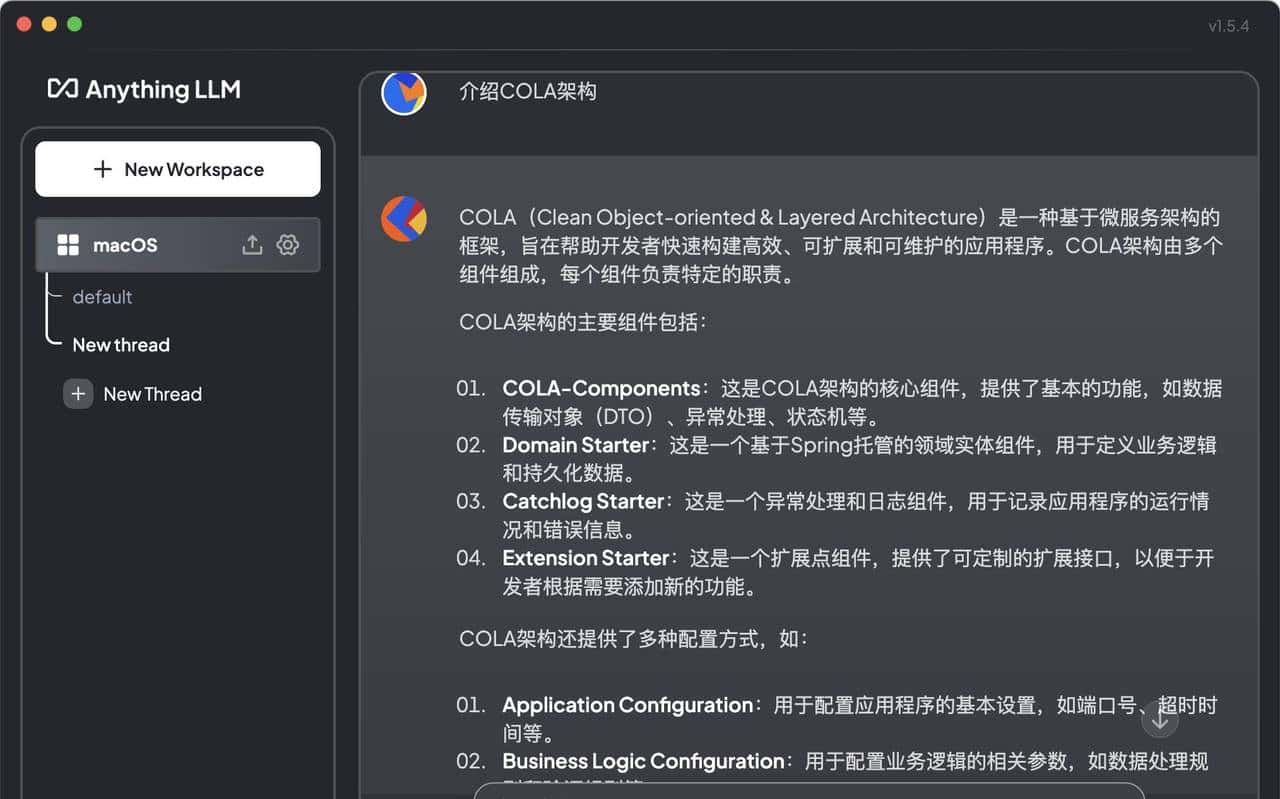
也可以将 llama3模型替换为阿里的qwen 模型,重新配置整个workspace,进行对话聊天。

#头条创作挑战赛#
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

您必须登录才能参与评论!
立即登录







你的机子太差。不是保存慢
文件上传沒了
不好用,经常没反应
厉害了
保存好慢
为什么知识库调用不全
保存文档慢的要命
anything llm
收藏学习了
优秀💪
好思路💪
受益匪浅👏
这个厉害了👏
收藏了,感谢分享