
注:该文用于个人学习记录和知识交流,如有不足,欢迎指点。
一、DMA是什么?
DMA 是直接内存访问技术,网卡接收的数据先存网卡缓冲区,再通过 DMA 写入主机内存,以 “帧” 为单位存储在环形缓冲区中。
1. DMA(直接内存访问)是什么
是一种无需 CPU 干预,让外设(如网卡)直接与主机内存交换数据的技术。核心作用是解放 CPU,避免 CPU 在 “外设 – 内存” 数据拷贝中浪费资源,提升传输效率。网络场景中,网卡接收 / 发送数据时,通过 DMA 直接读写主机内存,CPU 仅需初始化和收尾通知。
2. DMA与Driver的关系
DMA 本身是硬件层面的功能(由网卡、DMA 控制器等硬件组件实现),但驱动(软件)负责配置、初始化和管理 DMA 的工作流程,二者是 “硬件能力 + 软件控制” 的协同关系。
1. DMA 的硬件本质
DMA(直接内存访问)是硬件级别的功能,由网卡内置的 DMA 控制器或系统总线的 DMA 控制器实现。它能独立于 CPU,直接在内存和外设(如网卡)之间传输数据,无需 CPU 逐字节搬运。
2. 驱动的控制作用
无论是传统内核驱动还是 DPDK 的 PMD 驱动,都需要软件层面配置 DMA 的工作参数:
传统内核驱动:在初始化阶段,驱动会设置 DMA 的源地址(网卡缓冲区)、目的地址(内存中 sk_buff 的数据区)、传输长度等,并启动 DMA 传输。传输完成后,驱动会处理硬件中断,回收资源。DPDK PMD 驱动:同样需要配置 DMA 映射(如通过 VFIO 让网卡直接访问大页内存中的 rte_mbuf),并通过轮询方式监控 DMA 传输状态,触发数据处理逻辑。
总结:DMA 是硬件功能,但驱动(软件)是其 “指挥官”—— 负责初始化、配置和管理 DMA 的数据传输过程,两者缺一不可。
3. 网卡接收数据的存储位置与形式
存储位置:分两步走
第一步:网卡内部缓冲区(临时存储)。网卡物理层接收信号并转换为数字数据后,先存入自身的片上缓冲区,避免数据丢失(应对瞬时高流量)。第二步:主机内存的环形缓冲区(核心存储)。通过 DMA 将数据从网卡缓冲区写入主机内存的 “接收环形缓冲区(RX Ring Buffer)”,该缓冲区由网卡驱动初始化分配,地址提前告知网卡。
存储形式:数据帧 + 缓冲区结构体
数据本身:以 “以太网帧” 为单位存储,包含 MAC 头部、IP 头部、TCP/UDP 头部、应用层数据(如微信消息)、FCS 校验字段,完整保留网络传输的原始格式。管理载体:每个数据帧会封装在
(DPDK 场景)或
rte_mbuf(传统内核协议栈场景)结构体中。结构体不仅包含帧数据的内存地址、长度,还记录帧的元信息(如接收端口、时间戳、协议类型),方便后续协议栈或应用程序快速处理。
sk_buff
4. 接收流程(数据从网卡到应用)
1. 传统内核协议栈(
sk_buff
sk_buff
步骤 1:网卡接收信号网卡物理层接收电 / 光信号,转换为数字数据,先存入网卡内部缓冲区(临时缓存,避免溢出)。步骤 2:DMA 写入内存网卡通过 DMA,将数据从内部缓冲区写入主机内存中预分配的
数据区(
sk_buff是内核管理数据包的结构体,包含数据指针、长度、协议类型等元信息)。步骤 3:更新接收环形缓冲区(RX Ring)网卡驱动初始化的 RX Ring(硬件环形缓冲区)中存储描述符(记录
sk_buff的内存地址、数据长度、状态等)。数据写入完成后,网卡更新描述符状态(如 “已就绪”)。步骤 4:内核处理网卡触发中断或内核轮询(NAPI)发现 RX Ring 中有就绪描述符,通过描述符找到对应的
sk_buff,交由协议栈逐层解封装(数据链路层→网络层→传输层→应用层),最终通过系统调用传递给应用程序。
sk_buff
2. DPDK(
rte_mbuf
rte_ring
rte_mbuf
rte_ring
步骤 1:网卡接收信号同传统流程,网卡接收信号并转换为数字数据,存入内部缓冲区。步骤 2:DMA 写入大页内存DPDK 提前在大页内存中分配
池(
rte_mbuf),
rte_mempool包含数据缓冲区和元信息(如端口号、时间戳)。网卡通过 DMA 直接将数据写入
rte_mbuf的数据区。步骤 3:放入接收环形队列(RX
rte_mbuf)网卡驱动(PMD,轮询模式)检测到数据就绪后,将
rte_ring的指针放入 RX
rte_mbuf(用户态无锁环形队列)。步骤 4:应用程序处理应用程序从 RX
rte_ring中取出
rte_ring指针,直接在用户态解析数据(无需内核干预),处理完成后释放
rte_mbuf回内存池。
rte_mbuf
5. 发送流程(数据从应用到网卡)
1. 传统内核协议栈(
sk_buff
sk_buff
步骤 1:应用发送数据应用程序通过系统调用(如
)将数据传入内核,内核为其分配
send(),并逐层封装协议头部(传输层→网络层→数据链路层)。步骤 2:加入发送环形缓冲区(TX Ring)内核将封装好的
sk_buff描述符(含内存地址、长度)加入 TX Ring(硬件环形缓冲区),并通知网卡。步骤 3:DMA 读取并发送网卡检测到 TX Ring 中有新描述符,通过 DMA 从
sk_buff的内存地址读取完整帧数据,经物理层转换为电 / 光信号发送到网络。步骤 4:释放资源发送完成后,网卡更新描述符状态,内核回收
sk_buff。
sk_buff
2. DPDK(
rte_mbuf
rte_ring
rte_mbuf
rte_ring
步骤 1:应用封装数据应用程序从
中申请
rte_mempool,在用户态直接封装各层协议头部(自定义或标准协议),填充数据。步骤 2:放入发送环形队列(TX
rte_mbuf)应用程序将
rte_ring指针放入 TX
rte_mbuf,通知网卡驱动(PMD)。步骤 3:DMA 读取并发送PMD 轮询 TX
rte_ring,获取
rte_ring指针,告知网卡其内存地址,网卡通过 DMA 读取数据,转换为信号发送。步骤 4:释放资源发送完成后,PMD 将
rte_mbuf释放回内存池,供下次复用。
rte_mbuf
6. sk_buff和rte_mbuf对比
| 场景 | 传统内核( |
DPDK( |
|---|---|---|
| 环形缓冲区 | 硬件级 RX/TX Ring(存储描述符) | 用户态 |
| 内存管理 | 内核统一分配 / 回收 |
用户态内存池( |
| CPU 干预 | 依赖中断 / 内核轮询,上下文切换多 | 轮询模式(PMD),用户态直接处理,无切换 |
| 性能特点 | 通用但高负载下延迟高、吞吐量有限 | 低延迟、高吞吐量,适合性能密集场景 |
简单说,两者都是通过 “环形缓冲区” 实现数据包的高效流转,但 DPDK 通过用户态接管和无锁设计,彻底规避了传统内核的性能瓶颈。
7. ringbuffer
我们常说的ringbuffer指的就是环形缓冲区这种数据结构。
在 DPDK(Data Plane Development Kit)中,“ringbuffer” 通常指的是
dpdk.readthedocs.io。它是 DPDK 提供的一种高性能无锁环形队列,用于在不同核心或模块间传递数据,比如传递
rte_ring指针,以实现数据包的高效流转。
rte_mbuf具有 FIFO(先进先出)、最大大小固定、支持多生产者多消费者等特性,通过 CAS(Compare-And-Swap)操作实现无锁出入队,能适应批量入队 / 出队操作dpdk.readthedocs.io。在传统的网卡驱动和内核协议栈中,“ringbuffer” 指的是网卡硬件的环形缓冲区,包括接收环形缓冲区(RX Ring Buffer)和发送环形缓冲区(TX Ring Buffer)。网卡驱动会初始化这些硬件环形缓冲区,用于暂存数据包的描述符。例如,网卡接收数据时,通过 DMA 将数据写入
rte_ring管理的内存区域,然后更新 RX Ring 中的描述符,内核再从 RX Ring 中读取描述符,找到对应的
sk_buff进行处理。
sk_buff
二、dpdk的工作原理
DPDK 的核心是绕过传统内核协议栈,在用户态直接高效处理网络数据包,通过一系列技术优化实现高性能数据平面处理,
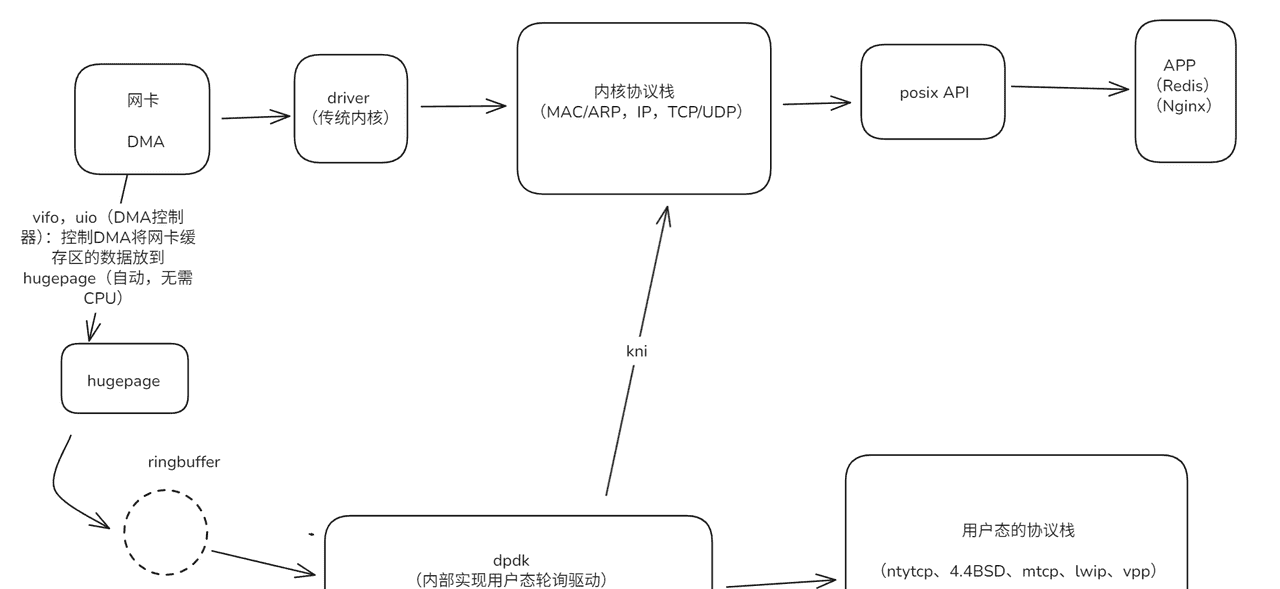
接受示意图:
(发送图箭头反过来即可,需要注意的是接收和发送都有单独的hugepage和ringbuffer。)
1. 核心机制:
1. 用户态驱动与硬件直连
摒弃内核态网卡驱动,采用用户态轮询模式驱动(PMD)直接操作网卡硬件,避免用户态与内核态的上下文切换开销。
2. 高效内存管理
使用大页内存(HugePages) 减少内存页表切换和 TLB( Translation Lookaside Buffer)失效,提升内存访问效率。通过内存池(
)预分配数据包载体(
rte_mempool),避免动态内存分配的性能损耗。
rte_mbuf3. 轮询替代中断
以主动轮询(Polling)代替传统中断模式,避免高流量下的 “中断风暴”(频繁中断导致 CPU 资源浪费),降低延迟。
4. 无锁化与并行处理
提供无锁环形队列(rte_ring)实现多核 / 多线程间的数据传递,减少锁竞争。
利用网卡多队列(Multi-Queue)和 RSS(接收端缩放)技术,将数据包分发到不同 CPU 核心,实现负载均衡。5. 协议栈旁路
跳过内核 TCP/IP 协议栈的复杂逻辑,用户态程序可直接解析、转发或修改数据包,按需实现轻量化协议处理。
2. DPDK 的PMD驱动模式
2.1 特点
用户态直接操作硬件:DPDK 的 PMD 运行在用户空间,直接通过内存映射(如 UIO、VFIO)访问网卡硬件寄存器,绕过了内核协议栈,避免了内核态与用户态的上下文切换开销。轮询替代中断:传统内核驱动依赖中断通知 CPU 处理数据包,而 DPDK 的 PMD 采用主动轮询(Polling) 方式,持续检查网卡是否有新数据,彻底消除了 “中断风暴”(高流量下频繁中断导致的 CPU 资源浪费)。专为高性能设计:PMD 针对数据包的批量收发、多核负载均衡(如 RSS 多队列)进行了深度优化,能充分发挥现代网卡和多核 CPU 的性能。
2.2 与内核驱动的对比
DPDK 的驱动是用户态的轮询模式驱动(Poll Mode Driver,PMD),与传统内核态驱动有本质区别:
| 对比维度 | DPDK 内置 PMD 驱动 | 传统内核驱动 |
|---|---|---|
| 运行空间 | 用户态(User Space) | 内核态(Kernel Space) |
| 触发机制 | 轮询(Polling)主动检查网卡数据 | 中断(Interrupt)被动响应网卡通知 |
| 内存管理 | 大页内存(HugePages)+ 内存池(rte_mempool)预分配 | 内核标准内存分配(slab、buddy 系统) |
| API 与开发 | 提供用户态专用 API(如 rte_eth_* 系列),需基于 DPDK 框架开发 | 基于内核驱动 API(如 net_device 接口),需遵循内核开发规范 |
| 性能特点 | 无上下文切换、无锁竞争,吞吐量高(100Gbps+)、延迟低(微秒级) | 存在上下文切换、中断开销,高负载下吞吐量和延迟表现一般 |
| 功能侧重 | 专注数据包高速转发、协议旁路处理,功能相对单一 | 支持复杂协议栈、系统级管理(如多协议兼容、电源管理),功能通用但性能妥协 |
| 硬件依赖 | 需网卡支持多队列、RSS 等高级特性,适配范围较窄 | 兼容绝大多数网卡,适配范围广 |
2.3 适配范围:主流网卡全覆盖
DPDK 已为 Intel、Mellanox(NVIDIA)、Broadcom 等主流厂商的网卡,预实现了对应的 PMD 驱动。用户使用时无需额外开发驱动,只需加载 DPDK 库即可调用。
2.4 依赖基础:硬件访问技术
PMD 驱动需借助 VFIO/UIO 等内核辅助技术,实现对网卡硬件寄存器的直接访问,但数据收发、队列管理、轮询等核心驱动逻辑,均由 DPDK 内部自行实现,不依赖操作系统的内核驱动。
3.dpdk是如何控制DMA的?
DPDK 可以通过VFIO/UIO等技术复用部分内核驱动的硬件资源配置(如网卡的 PCIe 资源分配),但数据处理的核心逻辑完全由用户态的 PMD 接管。这种设计既保证了硬件访问的高效性,又无需完全重写底层硬件驱动,降低了适配成本。
三、 VFIO、UIO
1. 定义
VFIO 和 UIO 是LInux内核提供的用户态 I/O 框架,用于让用户态程序(如 DPDK)直接访问硬件资源。VFIO 和 UIO 的核心作用之一,就是让用户态程序(比如 DPDK)能直接控制硬件的 DMA 功能(比如配置 DMA 传输的内存地址、启动 / 监控传输过程),而不用依赖内核驱动来中转。它们相当于 “权限中介”,把内核手里的 DMA 控制权,安全地开放给用户态程序,是用户态“绕过内核,直接操作硬件 DMA” 的关键工具。
| 对比维度 | VFIO | UIO |
|---|---|---|
| 安全性 | 高(依赖 IOMMU,实现硬件隔离,防止非法访问) | 低(无 IOMMU 隔离,依赖内核信任) |
| 功能完整性 | 支持 PCIe 设备全功能访问(含中断、DMA、多队列等) | 仅支持基础 I/O 内存映射,中断处理简陋 |
| 内核依赖模块 | |
|
| 适用场景 | 现代高性能场景(如 DPDK、NFV、高性能虚拟交换机) | 早期用户态硬件访问需求(如简单外设控制),逐渐被 VFIO 替代 |
| 性能表现 | 高(适配 DMA 直接访问、多核并行,无锁竞争) | 一般(中断处理和内存管理开销较大) |
| 生态支持 | 主流,是 DPDK 等高性能框架的推荐选择 | 逐渐边缘化,仅遗留场景使用 |
2. 注意:传统内核驱动不依赖 VFIO/UIO
传统内核驱动不依赖 VFIO/UIO,而 DPDK 作为用户态框架,依赖 VFIO(或 UIO)来实现硬件直接访问。
传统内核驱动:运行于内核态,直接通过内核原生 API(如
接口)操作硬件,无需 VFIO/UIO 中转。内核本身拥有硬件的完全控制权,包括 DMA 配置、中断处理等。DPDK:运行于用户态,需通过 VFIO(推荐)或 UIO 来获得硬件访问权限(如网卡的 DMA 缓冲区、寄存器空间)。VFIO 提供了安全的用户态硬件访问机制(基于 IOMMU 隔离),是 DPDK 实现 “绕过内核、用户态直连硬件” 的核心依赖。
net_device
四、 DMA、VFIO/UIO、driver三者关系
| 组件 | 角色与作用 |
|---|---|
| DMA 硬件 | 负责实际的数据传输(在网卡缓冲区与内存之间搬运数据),是功能的执行者。 |
| VFIO/UIO |
是 Linux 内核提供的用户态硬件访问框架, 负责: – 将网卡的 DMA 可访问区域(如寄存器、缓冲区)映射到用户态地址空间; – 提供安全的硬件权限管理(如 IOMMU 隔离),让用户态程序(如 DPDK)能直接控制硬件。 |
| 驱动程序 |
(如 DPDK 的 PMD 驱动)负责配置 DMA 的传输参数: – 指定数据传输的源 / 目的地址(如 HugePage 中的 – 配置传输长度、触发方式(如轮询模式下的 DMA 启动逻辑); – 监控 DMA 传输状态,完成数据收发后的资源管理。 |
总结:VFIO/UIO 是 “用户态访问硬件的通道”,驱动程序是 “DMA 传输的配置者”,两者共同支撑用户态程序(如 DPDK)对 DMA 的控制,而 DMA 硬件是实际的执行者。
五、DPDK多队列网卡的机理
核心结论:DPDK 多队列网卡,是指网卡硬件支持多个独立的接收队列(RX Queue)和发送队列(TX Queue),配合 DPDK 的 PMD 驱动与多核调度逻辑,实现数据包的并行分发、处理,是 DPDK 突破性能瓶颈的核心硬件基础。
1、核心本质
传统单队列网卡:所有数据包都通过同一个 RX/TX 队列收发,只能由单个 CPU 核心处理,容易出现 “队列拥堵” 和 “单核心瓶颈”。DPDK 多队列网卡:在硬件层面划分多个独立队列(比如 8 个 RX 队列 + 8 个 TX 队列),每个队列可绑定到不同的 CPU 核心,让多个核心并行处理不同队列的数据包,最大化利用多核算力。
2、关键作用(与 DPDK 协同优化)
负载均衡(基于 RSS 技术)网卡通过 RSS(接收端缩放)算法,根据数据包的源 IP、目的 IP、端口等信息,将不同数据流均匀分发到不同 RX 队列。DPDK 再将每个 RX 队列绑定到独立 CPU 核心,避免单核心过载,提升整体吞吐量。
无锁并行处理每个队列对应专属 CPU 核心,核心仅处理自己绑定队列的数据包,无需锁机制协调,彻底消除多核间的锁竞争开销,降低延迟。
业务隔离可将不同业务的数据包分配到不同队列(比如语音业务用队列 0、视频业务用队列 1),实现业务流量的物理隔离,避免相互干扰。
3、与 DPDK 的配合逻辑
DPDK 的 PMD 驱动会直接配置网卡的队列参数(如队列数量、队列大小、绑定的 CPU 核心)。接收时:网卡通过 RSS 分发数据包到各 RX 队列,DPDK 核心轮询自己绑定的队列,通过 DMA 读取 HugePage 中的
。发送时:DPDK 核心将处理后的
rte_mbuf放入自己绑定的 TX 队列,网卡通过 DMA 读取队列数据并发送。
rte_mbuf
六、优缺点
| 优点 | 缺点 |
|---|---|
|
1. 高性能:吞吐量可达 100Gbps+,延迟低至微秒级(传统内核通常为毫秒级)。 2. 灵活性:用户态开发无需依赖内核接口,可自定义协议处理逻辑。 3. 并行高效:无锁设计和多核调度适配高并发场景。 |
1. 学习成本高:需掌握 DPDK 特有的 API、内存模型和硬件交互逻辑。 2. 硬件依赖:部分高级特性(如 RSS、多队列)需网卡支持。 3. 系统配置复杂:需配置大页内存、CPU 亲和性等,对运维要求高。 4. 功能局限性:不适合通用网络场景(如依赖内核协议栈的复杂 TCP 连接管理)。 |
七、dpdk的作用和应用场景
dpdk的核心作用:处理大报
我们可以在dpdk的架构上实现自己的用户态协议栈
市面上好用的用户态协议栈:ntytcp、4.4BSD、mtcp、lwip、vpp
问题:
1. dpdk能不能提升Redis qps(每秒响应的请求数)?
答:不那么明显。
2. dpdk能不能减少Nginx延迟(发包到收包的时间)
答:不那么明显
3. dpdk能不能提升吞吐量 (每秒的数据处理量,比如文件的下载)
答:可以,效果显著
应用场景:
1. 不同服务器间备份大量数据的场景(底层:dpdk、应用层:rbma)
2. 防火墙、路由器、网关
DPDK 适合高带宽、低延迟、高并发的网络数据平面处理场景,典型包括:
网络功能虚拟化(NFV)如虚拟防火墙、负载均衡器、VPN 网关等,替代传统专用硬件,降低成本并提升灵活性。
高性能虚拟交换机如 Open vSwitch-DPDK(OVS-DPDK),为云数据中心的虚拟机(VM)间通信提供高速转发能力。
骨干网设备高性能路由器、交换机的数据平面,处理大规模路由转发和流量调度。
高流量服务器CDN 节点(内容分发)、DDoS 防护节点(快速过滤攻击流量)、高频交易系统(低延迟数据传输)等。
边缘计算在边缘节点处理物联网设备的海量实时数据,满足低延迟响应需求。
总结:DPDK 是 “为高性能网络而生” 的工具包,通过 “用户态直连硬件 + 极致优化” 突破传统内核瓶颈,但代价是通用性降低,适合特定场景的深度性能优化。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











