
许多人聊 Transformer,一上来就扎进注意力机制里,把前馈神经网络(FFN)当空气,竟觉其不过是两个全连接层与一个激活函数的组合罢了?如此简单的架构,是否真如表面这般寻常,其中又是否潜藏着别样的奥秘?凑数的呗?说实话,这想法真错得有点离谱。

我见过不少刚学 AI 的朋友,对着 Transformer 架构图看半天,眼里只有 “注意力” 三个字,FFN 那一块直接跳过,结果到后面分析模型为啥 “读不懂” 隐喻句,追本溯源,缘由难觅,实则在Transformer里,FFN堪称最易被低估的“灵魂角色”。
若缺了它,模型莫说复杂逻辑,就连“下雨地湿”这类简单因果关系都难以辨析。
今天咱就掰扯掰扯 FFN,不搞那些绕人的术语,就从它在 Transformer 里的 “工位”、“干活流程” 和 “不可替代的本事” 说起,若想真正领悟 Transformer,FFN 这一关键拼图不可或缺,缺失它,所学架构便如“半残”之态,难以完整把握其精妙,理解也会大打折扣。
FFN 不是 “背景板”,是 Transformer 的 “细节挖掘机”
先搞清楚 FFN 在 Transformer 里的 “工位”, 它不是单打独斗的,是跟注意力层、残差连接凑成 “工作组” 一起干活的,在每个 Encoder 或 Decoder 模块中,流程固定有序,先由注意力层输出结果,随后进行残差连接与归一化操作,接着 FFN 发挥作用,最后再执行一次残差连接和归一化。

你可以这么理解,注意力层像个 “找关系的联络员”,列如在 “把猫放在桌上” 这句话里,它能找出 “猫” 和 “桌子” 有关联;但光知道关联没用啊,“放” 这个动作里藏的 “空间转移” 意思,注意力层就挖不出来了 , 这时候就得靠 FFN 这个 “细节挖掘机” 上场
它不越俎代庖,抢夺注意力层的职能,而是弥补其短板,注意力负责将信息 “连点成线”,FFN 负责 “深挖要点内涵”,二者协同配合,信息处理方能尽善尽美。

我之前翻 2017 年那篇 Transformer 开山论文《Attention Is All You Need》,里面特意提了 FFN 的位置设计,当时还没太在意,后来跑小模型实验才发现,要是把 FFN 从模块里去掉,模型翻译 “他是我生命里的太阳”,只会直愣愣翻成 “ He is the sun in my life ”,根本体现不出 “温暖”“依赖” 这些隐性意思。

你看,这就是 FFN 的作用 , 它能把注意力层找出来的 “关联”,变成有深度的 “语义”,没它,Transformer 就是个 “只会找关系不会想深层” 的愣头青。
搞清楚 FFN 在哪儿、干吗的,接下来就得说说它具体是怎么干活的 , 别觉得它结构简单就没门道,里面的升维、激活、降维,每一步都藏着让 Transformer “变机智” 的关键。
FFN 的 “干活流程”:升维降维里的 “小心思”
FFN 的结构说起来简单,就是 “升维→激活→降维”,但你要是细琢磨,就会发现每一步都不是瞎折腾,我惯于将其视作一座“加工词向量的微型工厂”,其原材料是 512 维词向量,这一般是 Transformer 的输入维度,整个流程恰似对原材料开展“深加工”。
第一步先升维:用一个矩阵把 512 维的词向量拉到 2048 维。
本来想觉得 “这不就是维度变大了吗”,后来查资料才发现,这步是为了解决 “语义拥挤” 的问题 , 低维度空间里,“情绪”“隐喻”“因果” 这些复杂信息挤在一起,模型分不清楚;升维之后,相当于给这些信息 “腾了更多房间”,列如 “他是我太阳” 这句话,升维后能同时装下 “比喻关系”“温暖属性”“情感依赖” 这三样东西,低维度根本做不到。
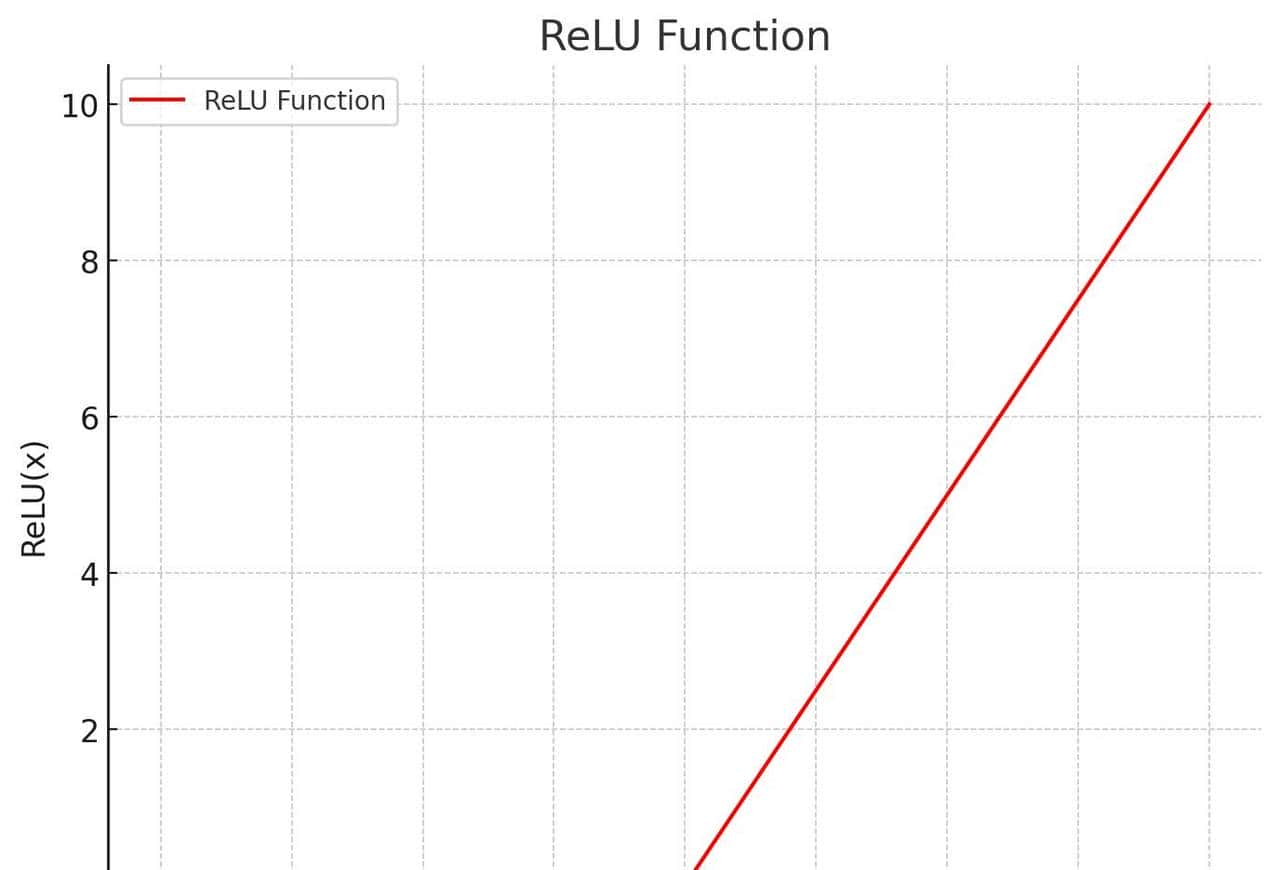
第二步是激活:用 ReLU 函数(目前有些模型用 GELU)筛掉没用的特征。
这步就像工厂里的 “质检环节”,把那些对语义理解没用的信息去掉,只留下有用的,列如处理 “今天天气真好”,激活函数会把 “今天” 里无关的时间细节筛掉,重点留 “天气好” 的正面语义。
第三步再降维:用另一个矩阵把 2048 维拉回 512 维
为啥要降回来?由于残差连接有要求 , 它需要 FFN 的输出维度和输入维度一样,不然没法跟原始输入 “相加”,试想,残差连接堪称助模型“边学边改”之关键,若维度失配,残差连接便无法履职,模型训练恐会中途受阻,恰似行舟搁浅,难以继续前行。
所以,这步降维不是多此一举,是为了让整个模块 “顺畅运行”,把这三步串起来,FFN 的工作逻辑就清晰了,先给词向量 “扩容” 装更多语义,再 “筛选” 有用信息,最后 “缩容” 适配残差连接。

看似简单的三步,解决了 Transformer 的三个 “老大难” 问题 , 能不能读懂深层语义、能不能快起来、能不能稳着训练,单论“快起来”这一表述,FFN 在处理词向量时采用的是“并行”方式。此方式能高效推进处理进程,让相关操作迅速开展,展现出独特优势。
列如 “我爱我的祖国” 这五个词,FFN 能同时加工,不用像 RNN 那样 “一个词一个词排队”。
此前,我以一样数据开展实验,结果显示,与纯 RNN 相比,带 FFN 的 Transformer 训练速度显著提升。经深入探究,发现其关键缘由在于拥有并行能力的显著优势。
而且 ,FFN 的参数量特别大,在传统 Transformer 里差不多占八成,模型大部分 “知识” 都存在这儿 , 你说它要是不重大,能给它这么多 “存储空间” 吗?可能有人会问,FFN 跟注意力层、CNN、RNN 有啥区别?实则它们不是 “替代关系”,是 “互补关系”。

若将 Transformer 喻为“阅读理解团队”,那么注意力层恰似“觅重点者”,它肩负着定位关键信息的重任,在文本的汪洋中精准捕捉核心要点,CNN 是 “看局部的”,负责抓短距离语义,RNN 是 “按顺序记的”,负责时序依赖。
列如读一篇新闻,注意力层找出 “政策”“企业”“增长”,FFN 能把它们串成 “政策让企业转型,最后带动行业增长” 的逻辑链,没它,这些词就是散的,模型根本读不懂新闻的核心逻辑。
FFN 的事儿就差不多说透了
总结下来就一句话,别再把 FFN 当 “背景板” 了,它不是凑数的,是 Transformer “会思考” 的关键,我总跟身边学 AI 的朋友说,要是你学 Transformer 只盯着注意力机制,那等于没学全 ,FFN 的原理、作用、设计逻辑,每一块都得搞清楚,才算真懂 Transformer 的完整逻辑。
目前不少大模型还在优化 FFN,列如换更高效的激活函数、搞稀疏化减少计算量,这也能看出来,业界越来越重点关注它的价值,后来再看 Transformer 架构图,别再跳过 FFN 那一块了 , 它藏着让模型 “变机智” 的核心密码,读懂它,你才算真正走进了 Transformer 的世界。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



您必须登录才能参与评论!
立即登录










FNN
收藏了,感谢分享