
QwQ-32B是阿里通义千问团队在3月6日发布的开源大模型,这款仅有320亿参数的模型,在数学、代码、通用能力等核心场景里,几乎跟满血版DeepSeek-R1(6710亿参数)不相上下。可以说实现了开源领域的降维打击。
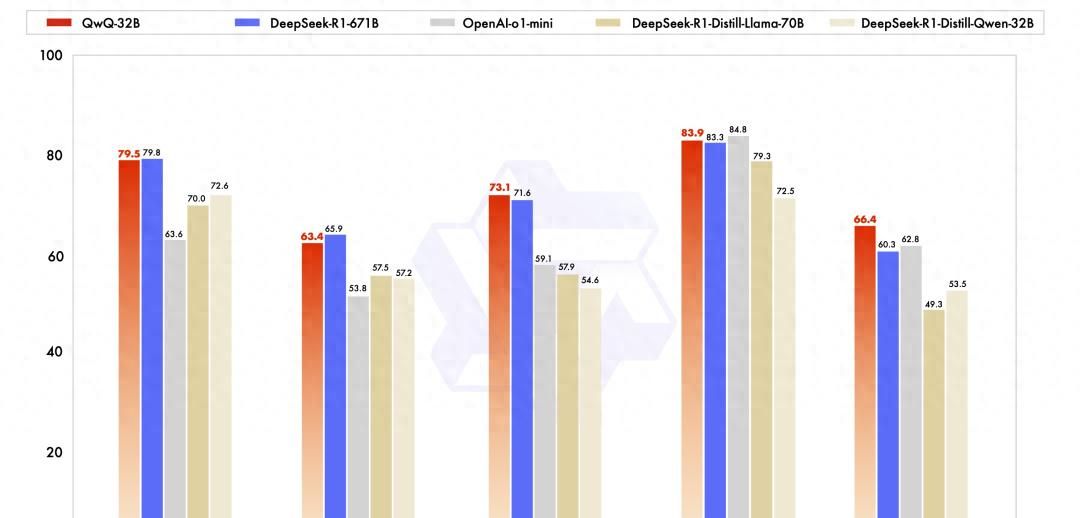
参数规模与性能对标:
QwQ-32B仅拥有320亿参数,但在多项基准测试中性能媲美DeepSeek-R1(6710亿参数,激活370亿),甚至在数学推理(AIME24评分79.5 vs. DeepSeek-R1的79.8)、编程能力(LiveCodeBench评分63.4 vs. 65.9)等任务中表现接近或略优48。其性能远超OpenAI的o1-mini及同尺寸蒸馏模型。
轻量化部署优势:
该模型支持消费级GPU单卡(如RTX 3090 Ti)或Mac设备本地部署,量化后最低仅需13GB显存(Q4量化版本约20GB),显著降低了运行门槛。例如,苹果M4 Max笔记本可流畅运行,输出速度达30+ token/s。
强化学习驱动:
通过多阶段强化学习(RL)技术优化:
- 第一阶段:基于数学准确性验证器和代码执行测试反馈,提升数学与编程能力;
- 第二阶段:引入通用奖励模型增强指令遵循、智能体协作等通用能力,同时保持数学/编程性能稳定。
接下来就为大家奉上详细的 QwQ-32B 一键使用和本地部署两种教程,手把手教你如何将模型部署到你的项目中,轻松享受高性能AI带来的便利。
一键使用
本镜像带开机自启动功能,直接开机开放端口,然后访问网址即可。
程序一键启动、停止、重启的方法以及手动启动 Web 页面的方法见文档最后。
注意:
此模型需要66G存储空间,拉取镜像时需要扩容20G,具体操作看下文介绍
显卡推荐:
两张4090及以上
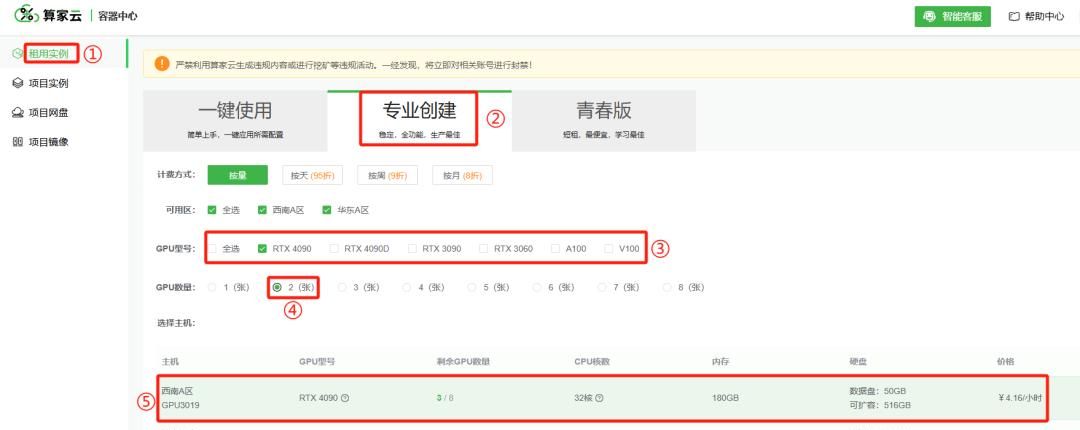
(1)根据需求选择主机和镜像,进行专业创建
在“应用社区”搜索并选择 QWQ-32B-fp16 大模型

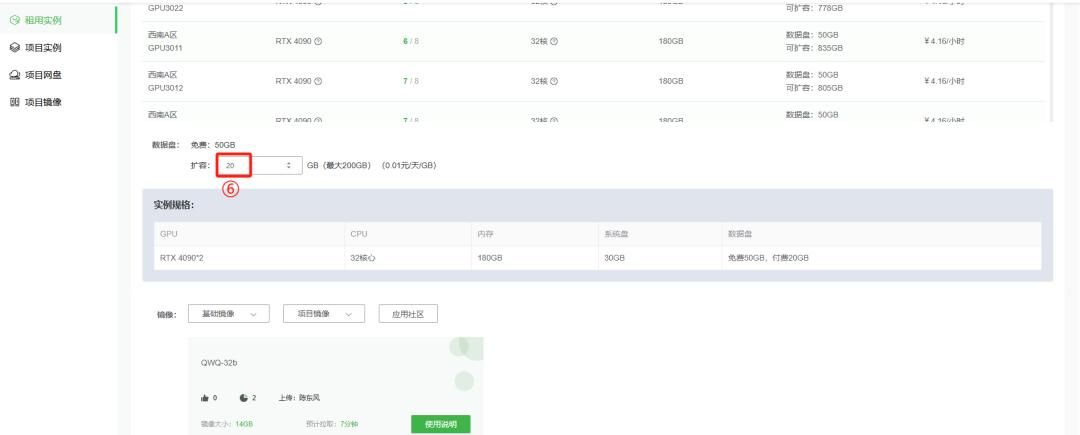
在“专业创建”模式下选择2张4090;下滑页面,数据盘扩容量选择20G,即可创建实例
(2)获取端口号
第一次使用需要进行实名认证(通过实名认证可跳过此步骤)
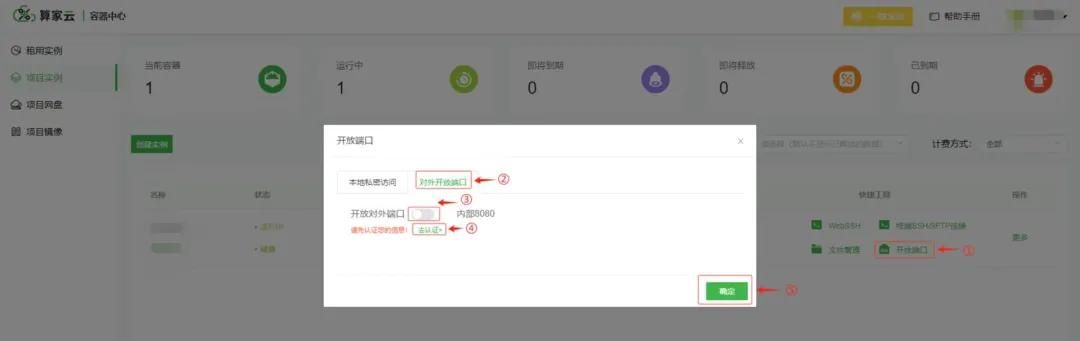
实名认证之后进行开放对外端口
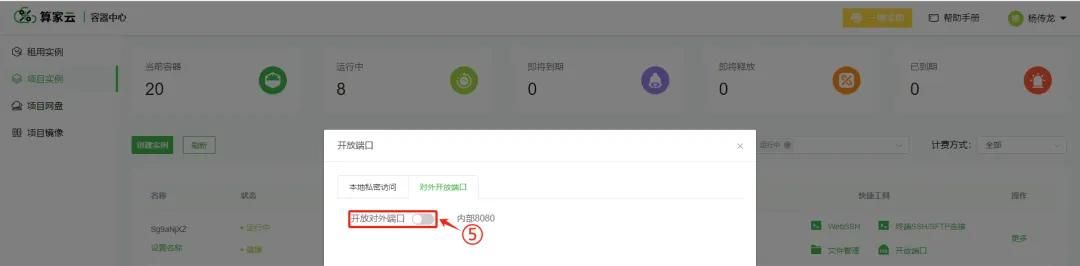
获取访问地址
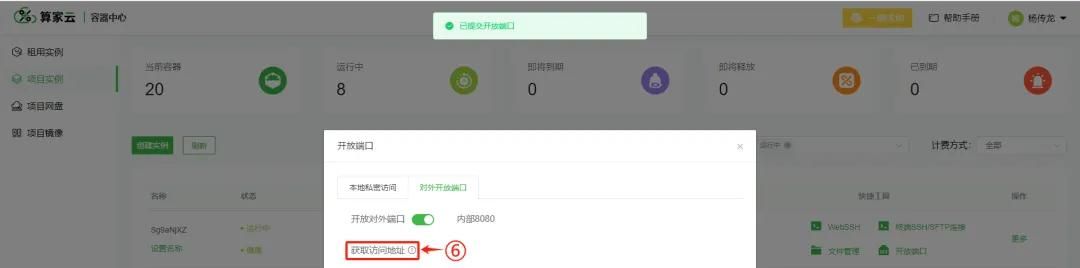
(3) 进入 web 页面
将获取到的链接复制到本地浏览器:
# 列如当前获取的地址如下:
http://xn-a.suanjiayun.com:50337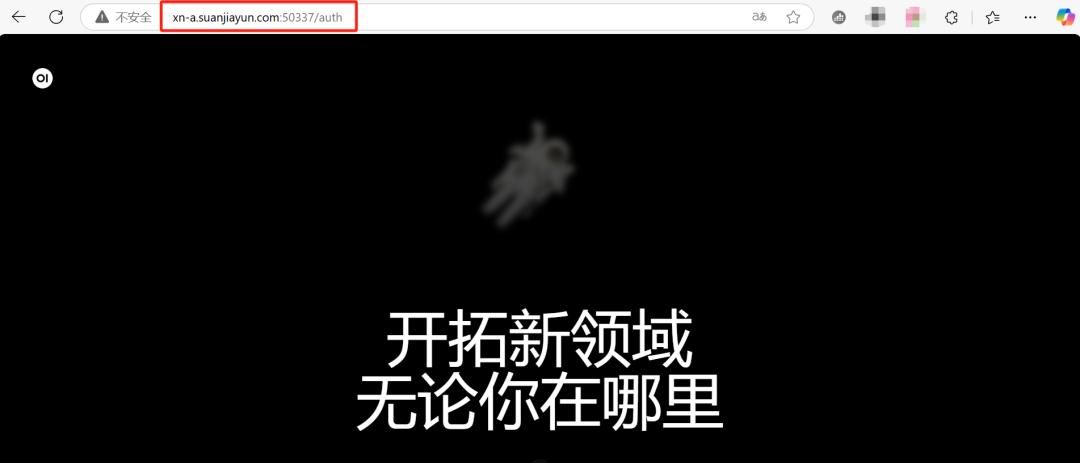
(4) 程序一键启动、停止、重启的方法
在项目实例页面,点击 WebSSH
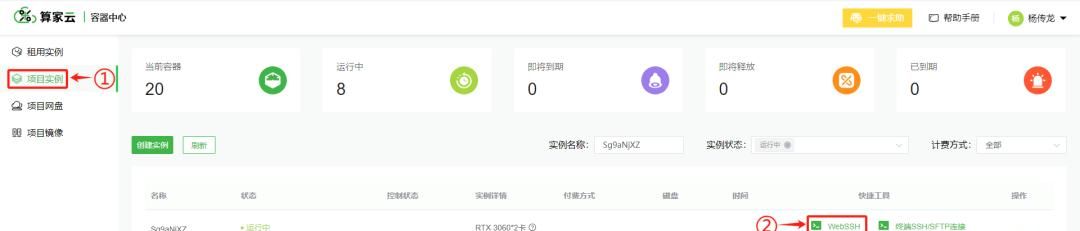
进入 WebSSH 页面,运行后续的功能代码

使用./sj-run.sh -h 可以查看程序的启动、停止和重启参数;(注意:代码块的右上角有一键复制代码的功能)
./sj-run.sh -h使用./sj-run.sh -s 可以启动程序,如果8080端口已有程序在运行,可以选择是否继续启动其他端口。(注意:代码块的右上角有一键复制代码的功能)
./sj-run.sh -s使用./sj-run.sh -t 可以停止程序;(注意:代码块的右上角有一键复制代码的功能)
./sj-run.sh -t使用./sj-run.sh -r 可以重启程序;(注意:代码块的右上角有一键复制代码的功能)
./sj-run.sh -r(5)手动启动 web 页面的方法(注意:代码块的右上角有一键复制代码的功能)
先使用./sj-run.sh -t 可以停止程序:(注意:代码块的右上角有一键复制代码的功能)
./sj-run.sh -t再使用命令启动 web 页面:(注意:代码块的右上角有一键复制代码的功能)
# 运行Ollama
nohup ollama serve > ollama.log 2>&1 &
# 运行open-webui界面
open-webui serve然后就能看到运行代码了,此时只需访问开放链接即可,其它具体使用方法见“使用说明”:
以上就是在算家云平台的一键使用教程,如果有小伙伴需要本地部署,那下面就是详细的本地部署教程,一起看看吧~
本地部署
(1)安装 ollama
运行命令进行安装:
curl -fsSL https://ollama.com/install.sh | sh设置模型下载地址、开放 ip 及端口:
如有模型地址更改需求,可用下命令:
export OLLAMA_MODELS=/root/sj-tmp/ollama/models设置 ip 地址及端口:
export OLLAMA_HOST=0.0.0.0:8080(2)运行 ollama
直接运行:
ollama serve等待运行成功后,可以在另一个终端通过 api 访问:
curl http://127.0.0.1:8080/api/tags持久运行(后台模式)
如果你需要 ollama 在后台运行,可以使用:
nohup ollama serve > ollama.log 2>&1 &或者使用 tmux / screen 来保持会话。
(3)下载并启动 QWQ 模型
ollama run qwq:32b-fp16等待下载完成后,可以直接进行对话:

如何 api 调用?
可以使用 PowerShell 或 Python 访问它。
✅ PowerShell
如果你想在 PowerShell 里 调用 ollama run qwq:32b-fp16 进行推理 :
Invoke-RestMethod -Uri "http://192.168.1.100:8080/api/generate" -Method Post -Body (@{model="ollama run qwq:32b-fp16"; prompt="你好,介绍一下自己"} | ConvertTo-Json -Depth 10) -ContentType "application/json"✅ Python
如果你想在 Python 里调用 :
import requests
import json
url = "http://127.0.0.1:8080/api/generate"
data = {
"model": "qwq:32b-fp16",
"prompt": "在数学中,3.11 和 3.8 谁大?请给出详细分析。",
}
response = requests.post(url, json=data)
# 存储最终的文本结果
text_output = ""
# 逐行解析 JSON
for line in response.text.strip().split("
"):
try:
json_data = json.loads(line) # 解析每一行 JSON
if "response" in json_data:
text_output += json_data["response"] # 拼接文本
if json_data.get("done", False): # 检查是否完成
break
except json.JSONDecodeError as e:
print("JSON 解析错误:", e)
print("最终结果:", text_output)(4)下载 open webui 界面
通过 Python pip 安装
Open WebUI 可以使用 Python 包安装程序 pip 进行安装。在继续之前,请确保您使用的是 Python 3.11 以避免兼容性问题。
安装 Open WebUI: 打开终端并运行以下命令以安装 Open WebUI:
pip install open-webui运行 Open WebUI: 安装后,您可以通过执行以下命令来启动 Open WebUI:
open-webui serve等待服务启动之后,可以看到出现 0.0.0.0:8080 的地址,这时我们只需在平台开放端口即可进行访问 open webui 界面

第一次使用需要进行注册账号:

首次登录需要等待一会儿,进入后来界面如下:
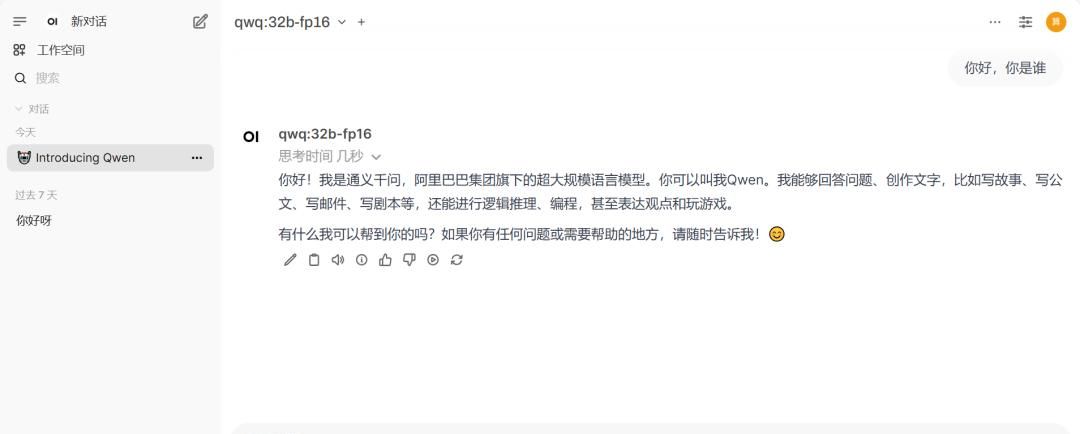
注:如果忘记账号密码导致无法登入界面,可以删除账号信息,选择重新注册:
- 点击文件管理,输入 /root/miniconda3/lib/python3.11/site-packages/open_webui/data/ 的路径并进入
- 删除下面 webui.db 这个文件,然后重新启动即可

(5)管理 Ollama 实例
正常情况下,进入 open webui 界面中就能自动获取模型,如果没有可以按照下面操作进行:
要在 Open WebUI 中管理您的 Ollama 实例,请执行以下步骤:
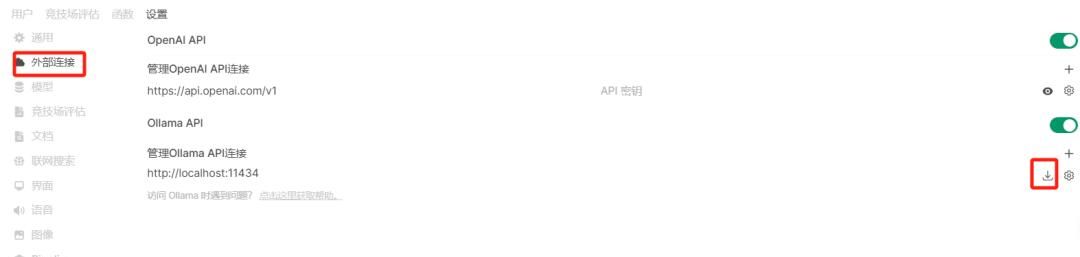
- 转到 Open WebUI 中的 管理员设置
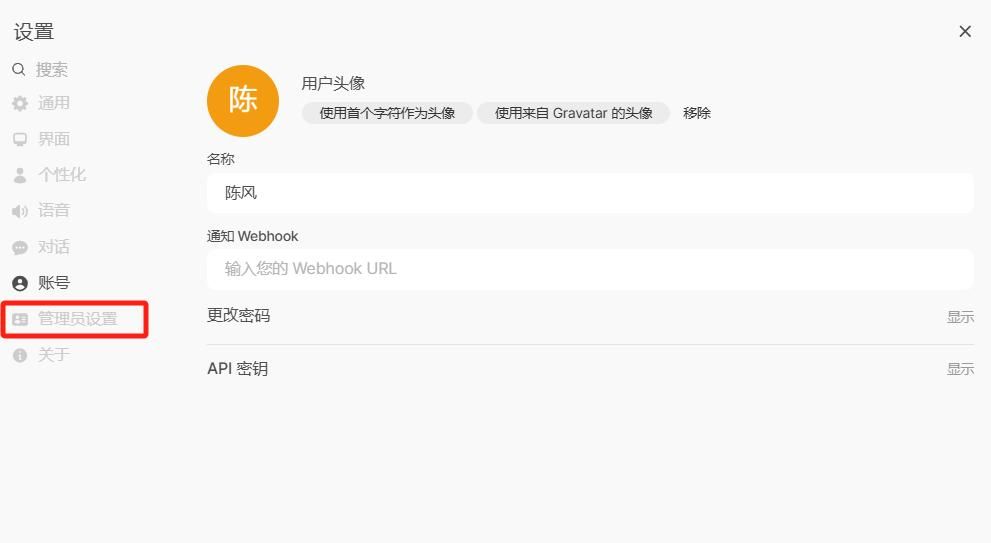
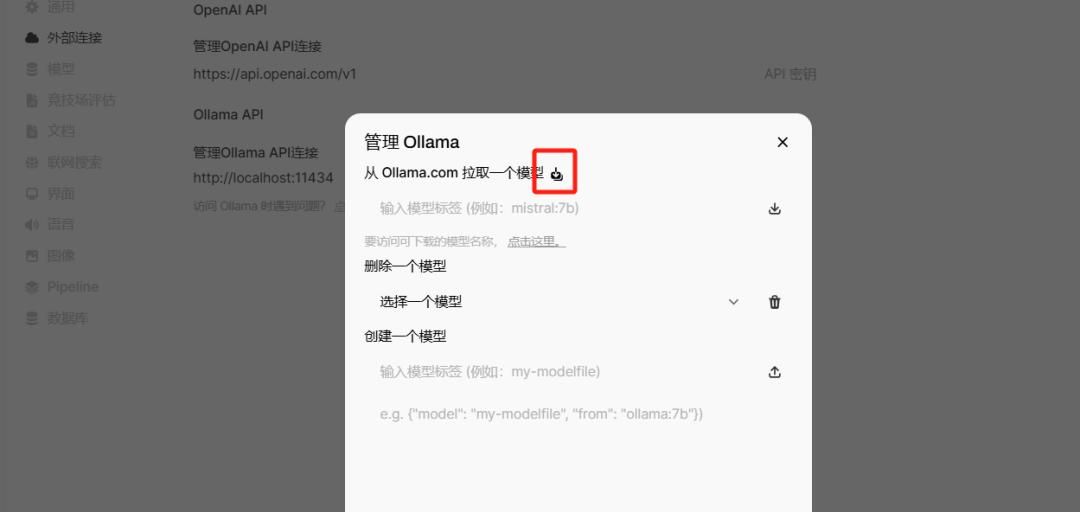
导航到 Connections > Ollama > Manage (单击下载图标)。
在这里,您可以下载模型、配置设置并管理与 Ollama 的连接。
管理屏幕如下所示:
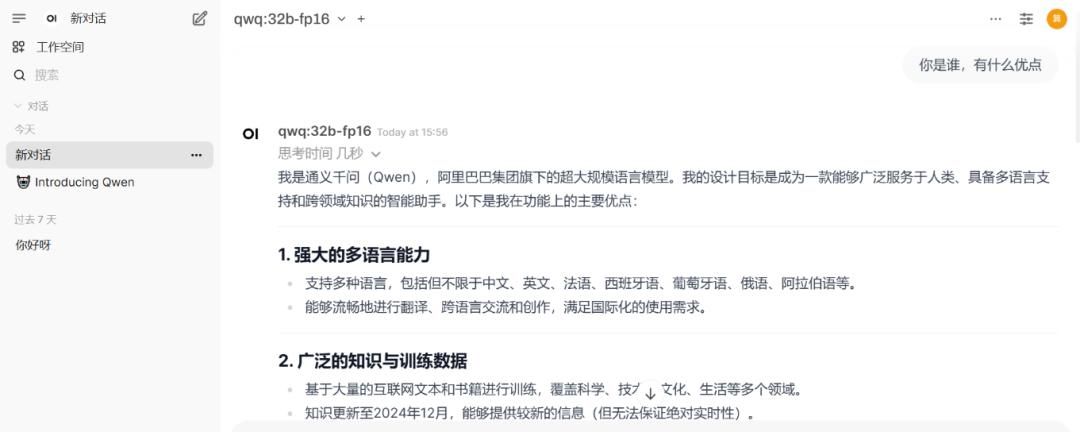
然后返回对话界面即可进行对话:
还有快速有效的模型下载方式:
可以直接从 Model Selector 下载模型。只需输入想要的模型的名称,如果它还不可用,Open WebUI 将提示从 Ollama 下载它。
下面是一个工作原理示例:
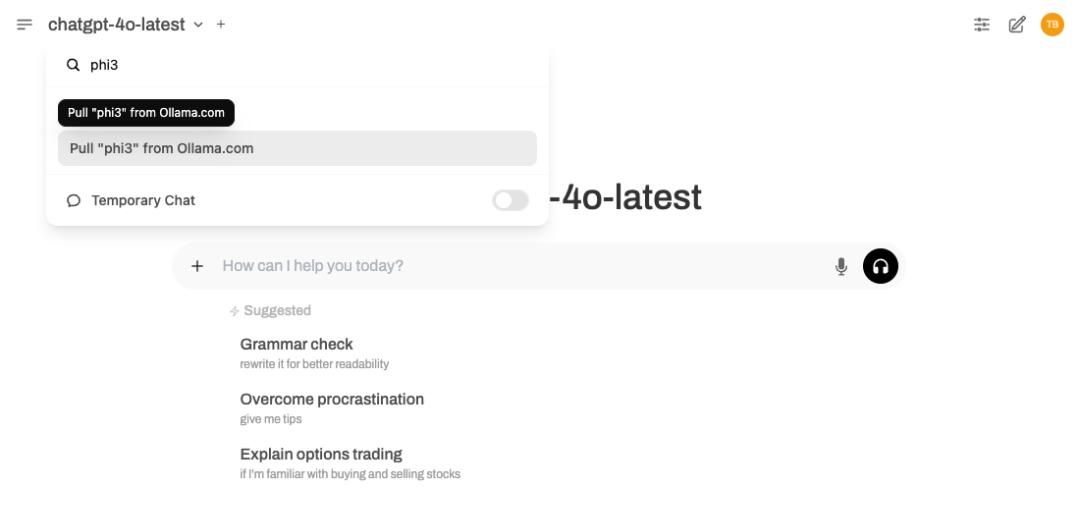
如果想跳过 Admin Settings 菜单的导航,直接使用模型,则此方法超级理想。
以上就是 QwQ-32B 的两种使用教程。希望能够协助到大家,欢迎在评论区交流提问哦~
附上模型链接,点击下方网址即可立即使用~
QWQ-32B-fp16-镜像社区 算家云
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...





