文献编号:1
文献著作信息:
CLIPTER: Looking at the Bigger Picture in Scene Text Recognition
原文 2301.07464.pdf (arxiv.org)
https://github.com/baudm/parseq
GitHub – amazon-science/semimtr-text-recognition: Multimodal Semi-Supervised Learning for Text Recognition (SemiMTR)
研究主题:
Scene Text Recognition【STR】
拓展阅读:
文字识别方法整理(2015~2019) – 知乎 (zhihu.com)
OCR论文综述(含文字识别、文本检测、端到端和数据集合)_poppyty的博客-CSDN博客_srn east
研究问题:
更大图片下的场景文本识别、目标识别、文本检测
研究缘由:
想要理解文本,场景也能提供上下文信息,不过现有的STR操作是从场景剪下,失去了原有的场景语义信息
研究设计:
1、用基于裁剪的识别器去识别场景,类似CLIP,提供图片的背景信息
2、利用门机制,这个门机制可以逐渐转向上下文丰富的特征,微调文本识别器
研究发现:
提供了模型无关的算法
研究结论:
作者提出了CLIPTER框架,这个框架通过视觉语言模型,用场景信息来辅助丰富文本识别器的信息,这种文本识别器是基于裁剪的
CLIPTER提供了模型无关的算法
场景文本识别器高度受益于场景上下文,尤其是在不好的图片质量下,或者要是别的词是词汇之外的词
带问题看论文:
1模型无关是指?
2门机制是什么?
是结合场景信息和识别信息,融合特征,把文本识别器转化为上下文感知特征的工具
注:CLIP只提供给交叉注意力池化后的图片特征
启发:
门控交叉注意力机制可以用在任何有两个特征输入的网络中吗?
细读论文:
论文图片

PARSeq是裁剪的文本识别器,无法识别场景下的困难信息,而CLIPTER可以,由于场景场下文信息可以辅助阅读真实世界场景

CLIPTER用了CLIP,是通过对比学习得到的,使得图片和文本有对应关系的超级大的模型,用预训练的CLIP,也可以用别的视觉-语言模型替代。作者这里用了CLIP来获得整个场景丰富的信息,与裁剪后的文本识别器的特征融合。结合这两个信息,作者提出了“门控-交叉注意力机制”,这个机制可以把预训练的文本识别器转化为上下文感知特征。


CUTE80 Benchmark (Scene Text Recognition) | Papers With Code

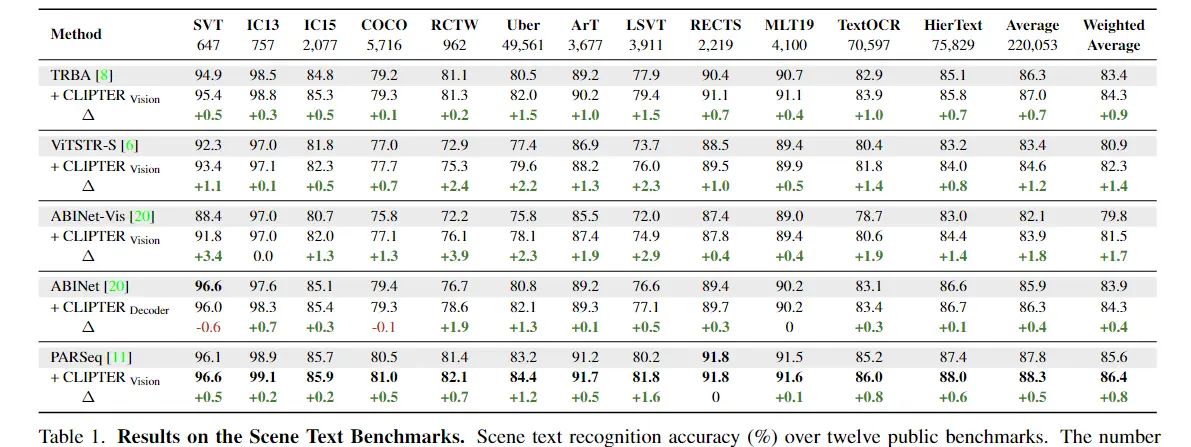
进一步阐述了增加上下文信息后得到的提升(是模态维度上的,并非是网络能力上的)
作者也客观展示了自己模型的不足,和PARSeq和CLIPER同样的不足

CLIPER使用的训练数据和PARSeq一样的情况下,错误率要显著低于后者
数据集介绍
Scene Text Recognition | Papers With Code
SVT

Scene Text Recognition on SVT
349张高分辨率图片,平均尺寸1260*860像素,来源于谷歌街景,训练集100张,测试机249张,单词级边框提供了不区分大小写的标签,有许多单词未注释,有许多噪音,大部分文本都于商店招牌相关,有各式各样的字体和图片样式,数据聚焦的每幅图片还提供了50个单词词典SVT-50
SVT Benchmark (Scene Text Recognition) | Papers With Code

ICDAR
分为


国际文件分析与识别会议引入的标准数据集,都是场景文本的数据集,包含高分辨率图片,平均值为940*770像素,包含数量可变的文本,摄像机在城市的不同地区拍摄的,带有不同程度的注释,许多图片在不同年份的ICDAR数据集之间共享,包括跨训练和测试分割,因此在一年的训练数据集上进行训练时必须小心
IC03包含181训练和251张测尝试片,有单词级边界框,区分大小写的转录
IC03 Full表明IC03数据聚焦的563个测试单词的所有图像共享一个词库,当用于评估时,词典约束数据集(IC03-50或IC03 Full),将识别问题简化为从词典定义的短名单中选择正确的基准单词,而在没有词典(如IC03)的情况下,则没有短名单可供选择
ICDAR 2005(IC05) 包含1001张训练图像和489张测尝试像,单词和字符级别的边界框,区分大小写的标签
ICDAR 2011 (IC11)包含229张训练图像和255张测尝试像,单词和字符级别的边界框,区分大小写的标签
ICDAR 2013 (IC13)BAOHAN 229张训练和233张测尝试像,单词和字符级别的边界框,区分大小写的标签
ICDAR 2013 数据集给每张图片提供了单词的边界框标注,每张图片都有属于自己的txt文件:
标注文件每一行代表一个文本目标,前4个数字为坐标信息(x1,y1,x2,y2),两组(x,y)分别代表文本框的左上和右下,目标框为举行,最后一列是文本内容,如果字体模糊则用###表明
Detection examples of the proposed method on the ICDAR 2013 dataset [17]. (figshare.com)

ICDAR2013 Benchmark (Scene Text Recognition) | Papers With Code
ICDAR 2015 和ICDAR 2013 数据集类似,知识文本框的格式由矩形变为四边形,所以写有txt文本的前四个数字变为八个数字,代表文本框的四个点,其他规则一样。包含大量偶然的场景文本图像,从数据聚焦裁剪2077个文本图像块用于文本识别任务,其中大量裁剪的场景文本由透视和曲率失真
ICDAR2015数据集_月半小丸子的博客-CSDN博客_icdar2015
COCO

coco数据库有八十个类别
一般是物体检测居多,文本识别有专门的coco-text
COCO – Common Objects in Context (cocodataset.org)
coco-text

COCO-Text论文地址
COCO-Text数据集下载地址
RCTW-17

自然场景下的中文阅读
RCTW-17论文地址
RCTW-17数据集下载地址
ICDAR2017 Competition on Reading Chinese Text in the Wild (RCTW-17) | Papers With Code
Uber
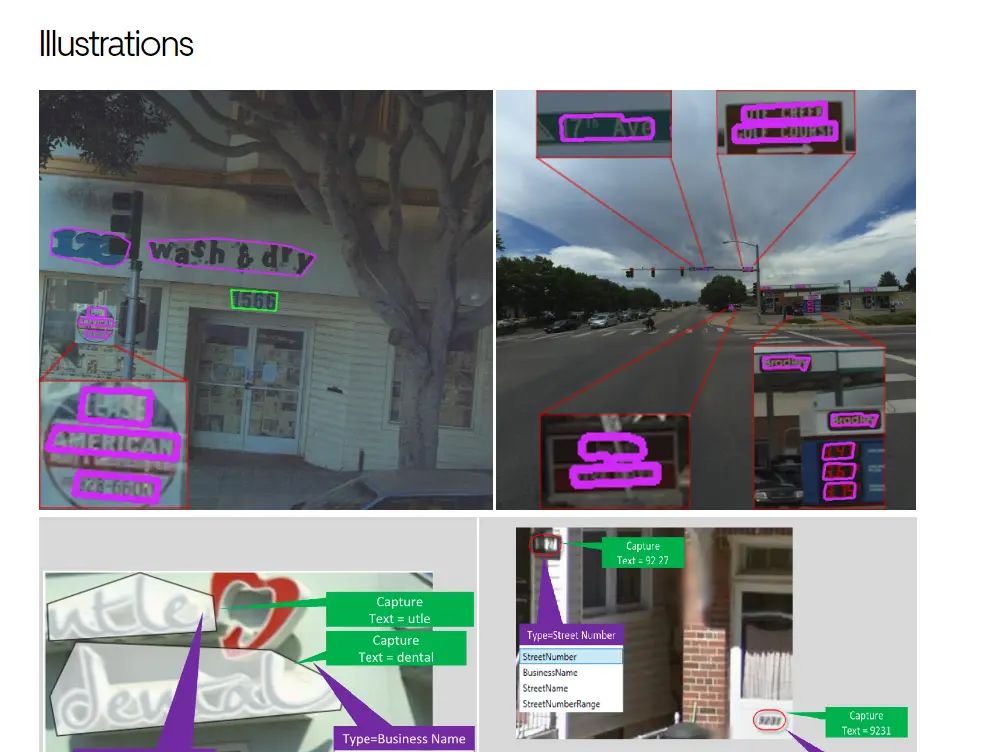
Uber-Text: A Large-Scale Dataset for Optical Character Recognition from Street-Level Imagery | Uber Blog
Uber-Text论文
数据集下载
ArT
ArT论文地址
论文表格
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...