在我很小的时候,总能听到一些“神童”的传说:某某父母把孩子关在家里“揠苗助长”,小孩哥2年学完小学的书、3年学完高中的书、10岁就考上了某某大学云云。他机智得像个小百科:问他历史,他能从秦始皇讲到二战;问他科学,他能背出元素周期表。但到了大学,往往就“露馅”了:孩子连衣服都不会洗,人际交往更是一塌糊涂。然后大家又笑他是“书呆子”——不懂得怎么动手、怎么按人的心意办事。
这小孩就像预训练的大模型,满脑子知识,却不懂得怎么应用、怎么按人的心意产出动作。微调和对齐的技术,就是帮这个“书呆子”成长的过程,让他从只会背书变成能听懂话、办实事的“社会人”。这里,预训练就像让一个天赋异禀的孩子读完世界上所有的书,微调就像让这个“天才学者”去参与专业的职业培训,对齐就像对这个“专业人才”进行职业道德和情商培训。
第一课:严师出高徒——RLHF的奖励与惩罚
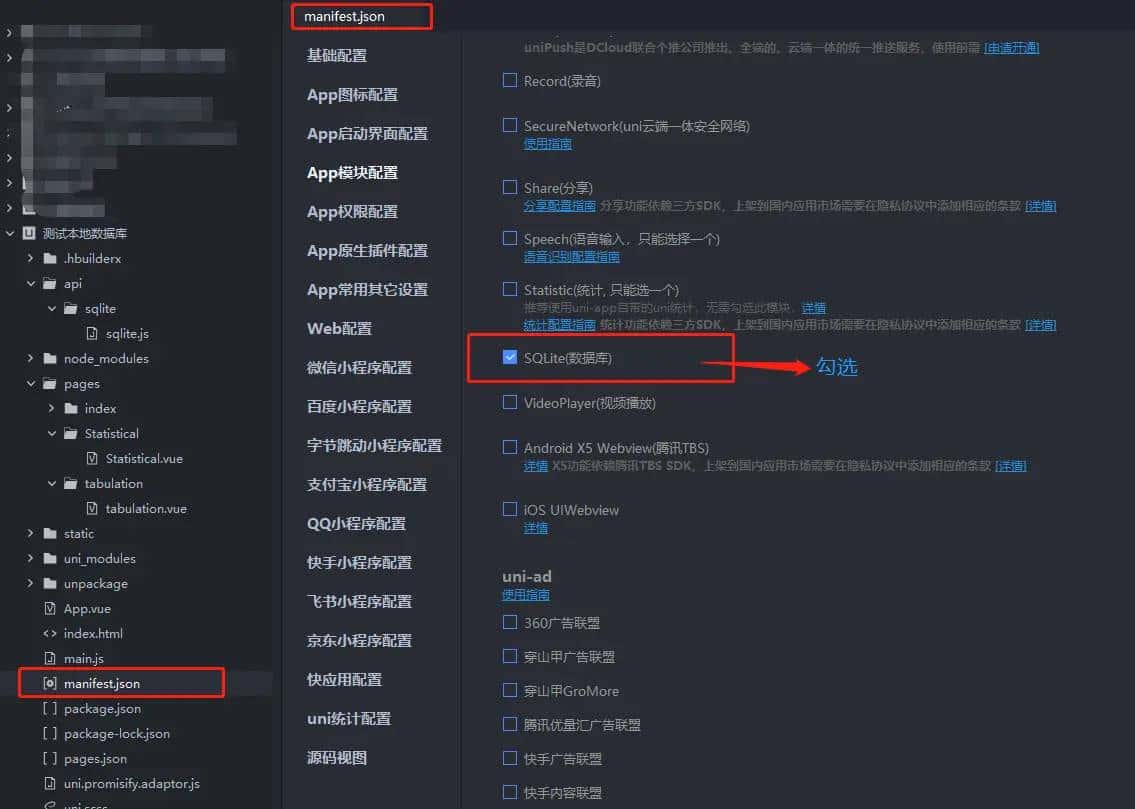
小孩刚进大学,遇到位严肃的老先生,手握厚厚的教案。这老师不爱空讲,他先示范:看我怎么倒水,你照做(监督微调,SFT)。小孩模仿,学会了基本动作。但光抄不够,老先生拿出两份答案:一个对,一个错,让小孩选。选对了,给颗糖(奖励模型打了高分);选错了,敲下手心(低分)。慢慢地,小孩摸透了老师的心思。这就是RLHF(人类反馈强化学习)[1]:用人类偏好训练奖励模型,再用强化学习(PPO)反复练习,让小孩不只模仿,还能根据反馈调整。
列如遇到了该选“金斧头”还是“银斧头”的问题时,小孩试着回答“我丢的是铁斧头”,老先生说“这个好,由于诚实”,小孩就记住这感觉。下次遇到类似题,他自然选诚实的路。实验里,这样的训练让小孩在真实对话中胜出大他百倍的“老大哥”,有害有偏见的回答降低,甚至能处理没学过的语言任务。在这个过程中,奖励不是死板的规则,而是柔性的引导——小孩学会了“讨喜”,而不是死记硬背。
但这种教学也有苦头:收集反馈太累,像老先生每天得批改成堆作业,成本高;练习时小孩偶尔犯迷糊,简单任务反而出错(对齐税:对齐可能带来能力分布变化(trade-off))。
这一课,小孩心里嘀咕:得找个更轻松的法子。
RLHF三阶段流程示意图 (来源:论文[1] Figure 2)
第二课:偷懒的艺术——DPO和它的伙伴们
小孩长大点,换了位年轻老师。这老师懒得建复杂奖励系统,他说:“何必费劲打分?直接告知我哪个答案家长更喜爱,我就教小孩偏向好的,远离坏的。”他用数学魔法把偏好数据变成简单公式[2]: LDPO(πθ;πref)=−E(x,yw,yl)∼D[logσ(βlogπθ(yw|x)πref(yw|x)−βlogπθ(yl|x)πref(yl|x))] 。小孩生成好坏答案,通过公式直接优化(β控制偏离程度),让他自然亲近“好”。小孩练起来轻松多了,不用反复试错。实验中,在指令跟随/摘要等任务上相较 PPO 表现可比或更优,还对温度变化也没那么敏感了。
但年轻老师发现,小孩在需要规划的游戏里弱:列如下棋,他只看一步。另一位老师补上[14]:“别光比答案,走成功的路!”他教小孩模拟整条路径,像规划一次旅行。小孩顿悟:规划不是猜,而是步步都要计算。
接着,理论家老师质疑评分传统[14]:“为什么非得用复杂模型?只要知道哪个答案排前面就行。”他用分类器替换,鼓励小孩跨题比较:“这答案为啥比那好?”实验证明,这法子对错误反馈很稳,数据多时性能飞跃,由于对齐靠的是顺序,不是绝对分数。就像高考的录取线,本质上是排名,而不是绝对的分数。
还有位爱创意的老师[9],见小孩答得太单调,说:“太呆板了!”她松开学习守则约束(拆分KL正则化,管多样性和稳定性),让小孩在数学题上试多条路,在长链推理等任务上通过多样化偏好与正则解耦获得显著增益。像让他在作业本边角涂鸦,灵感迸发后再来挑选。
这一课,老师帮小孩减负:从重赏罚到轻巧引导,让他学得更自在。

左:DPO在所有KL值下都最高的预期奖励。右:DP对采样温度的变化更鲁棒 (来源:论文[2] Figure 2)
第三课:自省的力量——无需外人的自学成才
小孩渐入佳境,这时一位老师走进来,递给他一面镜子:“别总等着别人打分,自己看看,答得怎么样?”小孩学会了生成答案后自评[4]:用镜子(LLM-as-a-Judge)问自己:“这个答案值几分?哪里能更好?”他试着回答问题,评完再改,迭代三轮,胜率从9%飙到20%,甚至超过了大名鼎鼎的前辈。由于他不再依赖外人,而是靠自己琢磨,找到对的路(大模型进化打破了人类策略的局限)。
另一位 AI 导师更进一步(RLAIF)[5]:他让小孩用“虚拟老师”给自己反馈。不是人类评分,而是 AI 模拟人类思考,用逻辑推理(思维链)打出更准的分。结果,小孩的回答在多项安全与偏好基准上,达到了与老师教育可比的水平(RLAIF vs RLHF),由于他学会了自问自答:“为什么这个答案好?由于它诚实。为什么诚实就好?由于诚实没有伤害。”他越练越顺,证明成长可以靠自己(大模型的对齐是可以内化的)。
就在小孩自省渐深时,一位导师带来了“组队”新玩法[15]:别一个人闷头想,生成一组答案,像召集几个“分身”一起比拼(组相对策略优化,GRPO)。小孩试着:出一道数学题,他脑中冒出几条解法,算相对奖励(组内标准化分数),挑最优的的强化。这里的巧妙之处在于,不用额外价值模型,直接用组内排名避开绝对分数的麻烦。实验里,这种方法在长链推理——如数学问题上——准确率上升,基于它的DeepSeek R1也在今年初大放光彩。这种做法就像和“分身”比拼:这条路快?那条路稳?比着比着,答案越来越精。
正当小孩得意于组队比拼,又一位策略大师出现了[3]。他拿来一盘棋,告知小孩:“光比答案还不够,生活里有些事得步步算计,像下棋或团队合作。”他教小孩模拟对战(自博弈):假想自己是个商人,谈判时每步都要想“对方会怎么出招?我该怎么应对?”通过反复对战,小孩学会了分解问题、实时调整策略。这叫 EPO(显式策略优化),它不靠评分好坏,而是直接在成功路径上练。每轮对战,小孩用“过程奖励”评估:这一步走得妙不妙?EPO 在社交对话与网页导航任务上达到 SOTA 或显著提升。他像个小军师,学会了看全局、定策略,游刃有余地应对复杂局面。
这一课,小孩清楚了:成长不靠外力,自己还能做对战和规划。

自奖励迭代训练流程:指令创建+指令遵循 (来源:论文[4] Figure 1)
第四课:面对世界的考验——安全、多语和价值的平衡
目前,小孩步入现实世界,挑战不再是答对题,而是应对复杂局面。
第一关:防止“坏人哄骗”。一位安全老师[6]模拟多轮对话:坏人层层设套,小孩练抵抗(多轮红队演练)。通过反复训练(对抗优化),在 BeaverTails、CoSafe 等基准上显著提升安全指标,还能保持聊天时的友善。在测试中,他像个机灵少年,拒绝糖衣炮弹却不失礼貌,安全与乐趣两不误。秘诀在于动态优化:每步评估未来风险,确保不被牵着鼻子走。
第二关:语言障碍。小孩母语流利,但在外语上结巴。一位桥梁大师走来[7],递给他一本翻译秘籍:“别死记单词,找语言间的共通旋律。”她教他融合英文和外语的思考方式(跨语言连接,自适应决策器),像把一首歌的调子唱成多国语言。在22种语言的测试(XNLI)中,他准确率从31%跃至38%,用少量数据胜过堆积翻译的老法子。仿佛他学会了用中文讲笑话的精髓,再用西班牙语、印地语重现,抓住笑点的灵魂。
第三关:价值冲突。每个人想要的不一样——有人爱幽默,有人求严肃。一位调和大师拿来调色盘[8]:“像画家调色,混合大家的需求。”她教小孩平衡风趣与无害(多人类价值对齐,约束优化),让他讲笑话时逗乐全场又不伤人。测试中,他通过可解释的约束在幽默、无害、协助度间实现可控权衡,像个机智的说书人,故事既有趣又得体。背后的数学(线性权衡)确保他公平对待每个声音,不偏不倚。
在这一课里,这些挑战像风雨雷电,小孩却学会了在复杂世界中优雅前行。

多价值奖励水平权衡,无害(左)与幽默(右),箭头为从原始到对齐模型的转变路径 (来源:论文[8] Figure 1)
第五课:窥见内心——思维与效率的秘密
最后,小孩开始反观自己,想知道“我是怎么学的?”一位侦探老师递给他放大镜[10]:“来,拆解你的思路。”她像解剖一幅画,分析他学习时的每笔每划(学习动态),发现他有时会抓错重点,列如重复无用短语,或者把好答案“挤”进狭窄模式。她教他扩展练习题(extend方法),像清理杂乱书桌,帮他专注关键。结果,他胜率从60%升到69%,如拨云见日,清楚成长不是瞎练,而是精选路径。
一位效率大师接着说:“别事事从头想,用巧劲!”她给他一把精巧工具(HiRA)[11],像把大车间浓缩成便携工具箱。他在多项推理与常识任务上展示稳定或明显优势,远超笨重方法。仿佛用几味调料烹出满汉全席,他学会以小博大,效率翻倍。
一位概率贤者带来骰子[12]:“你的选择像掷骰,藏着风险。”她让他模拟多次(蒙特卡罗采样),看出哪里可能出错,列如不小心泄露秘密。她调整他的方法(熵优化损失),以概率风险/不确定性度量指导对齐与遗忘,让答案稳如磐石,降低不期望输出的波动。测试中,他像走钢丝的艺人,步伐从不摇晃,学会了在不确定中保持清醒。
最后,一位团队大师教他与众人协作[13]:“分享智慧,但守住隐私。”她让他把知识分成公共和独有部分(FedCDD,解耦共识与分歧),像在小组作业中贡献创意,却把日记锁好。在群体测试(MT-Bench)中,优于若干联邦/聚焦式微调基线,如同村里最亮的少年,协作中仍保个性。
最后这课上完了,小孩终于从“书呆子”变成了“社会人”:懂己心,知世故,效率高,团队强。

微调学习动态分解曲线,前三个为SFT,第四个为SFT后进行DPO (来源:论文[10] Figure 3)
结语:成长未完待续
小孩的故事像大模型的蜕变:从“书呆子”到“社会人”,从严师RLHF到巧妙DPO,从自省突破到世事历练,再到内心洞悉。每步都藏智慧——对齐不是人工的填鸭式教学,而是唤醒内在。
小孩的冒险还将继续:混合群体智慧与个性,实时调整策略;统一方法,连接多语言多价值;用可视化预测误区,自训更强。他将如万能刀,随场景变招。
我们通过这个小孩的成长故事,看到了大模型是怎么从懵懂到成熟的,中间的弯路和顿悟,又是怎么让他真正懂事的。或许大模型的微调和对齐,对我们人类的教育也有借鉴意义。
参考文献
[1] Training language models to follow instructions with human feedback: 开创RLHF框架,通过人类反馈强化模型指令跟随能力。
[2] Direct Preference Optimization: Your Language Model is Secretly a Reward Model: 提出DPO简化RLHF为直接损失优化,提升训练效率。
[3] EPO: Explicit Policy Optimization for Strategic Reasoning in LLMs via Reinforcement Learning: 针对战略推理任务的明确策略优化方法。
[4] Self-Rewarding Language Models: 引入自奖励机制,实现模型迭代自对齐。
[5] RLAIF vs. RLHF: Scaling Reinforcement Learning from Human Feedback with AI Feedback: 证明AI反馈可媲美人类反馈,并引入直接RLAIF变体。
[6] MTSA: Multi-turn Safety Alignment for LLMs through Multi-round Red-teaming: 通过多轮红队演练提升LLM安全对齐。
[7] CC-Tuning: A Cross-Lingual Connection Mechanism for Improving Joint Multilingual Supervised Fine-Tuning: 潜在级跨语言连接机制,提升多语言微调性能。
[8] MAP: Multi-Human-Value Alignment Palette: 约束优化框架实现多人类价值对齐。
[9] Diverse Preference Learning for Capabilities and Alignment: 解耦KL正则化,提升对齐多样性和校准。
[10] Learning Dynamics of LLM Finetuning: 分析微调学习动态,揭示挤压效应。
[11] HiRA: Parameter-Efficient Hadamard High-Rank Adaptation for Large Language Models: 哈达玛积高秩PEFT方法,提升适应性。
[12] A Probabilistic Perspective on Unlearning and Alignment for Large Language Models: 概率框架增强遗忘与对齐评估。
[13] Efficiently Decoupling Consensus And Divergence For Federated Fine-Tuning Of Large Language Models: 联邦学习解耦框架,提升LLM微调泛化。
[14] Rethinking Reward Modeling in Preference-based Large Language Model Alignment: 重新审视奖励建模,提出顺序一致性替代BT模型。
[15] Group Relative Policy Optimization for Efficient Math Reasoning Alignment: 提出GRPO用于高效数学推理对齐,通过组相对优化提升长链任务性能。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











