日前,在2025开放原子园区行暨小米开源峰会上,小米基础技术部AI引擎团队负责人 刘绍辉 分享了小米在大模型训练与推理Infra领域的探索和实践。刘绍辉以小米集团统一AI技术平台的构建为核心展开论述,该平台搭建了四层架构体系,覆盖硬件基础、调度存储、训练推理及应用落地全环节。

小米基础技术部AI引擎团队负责人 刘绍辉
一、开篇:战略驱动,构建小米集团统一AI技术平台
2024年,为支撑公司整体AI战略落地,小米AI引擎团队基于过往在Infra领域的技术积累,结合开源生态与自主研发,打造了集团统一的AI技术平台。该平台全面覆盖训练、推理及AI应用等核心环节,为公司内部大语言模型、多模态模型、自动驾驶感知规控模型及各类生成式模型的研发提供了坚实支撑。

小米拥有深厚的开源文化积淀,自2012年起便积极投身开源项目建设,从早期的HBase相关项目到如今的大模型推理领域开源贡献,始终秉持“基于开源、回馈开源、引领开源”的核心理念。在刘绍辉看来,企业内部开展开源工作,既需要公司层面的文化支持,更要以业务需求为根本落脚点。只有业务持续增长并提出更高要求,才能实现业务、平台与开源社区的正向循环互动,形成良性发展生态。
二、底层基石:GPU算力调度的优化与标准化交付
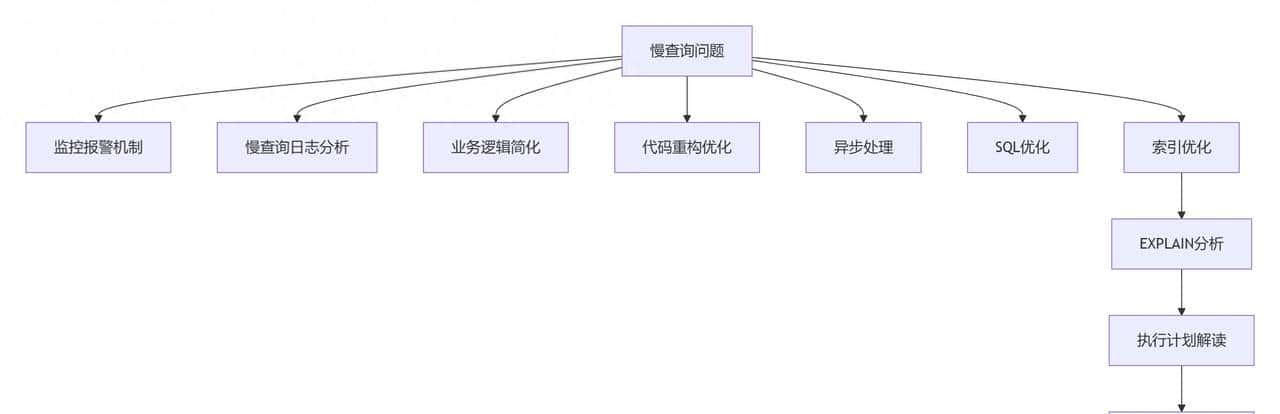
AI大模型训练对算力和高性能网络有着极高要求,尤其是大语言模型训练过程中,算力分配与网络通信效率直接影响训练进度。小米AI引擎团队在K8s原生调度器基础上进行增强,重点打造了网络拓扑感知调度能力。通过自动构建集群网络拓扑,将同一训练任务或通讯组优先调度至同一ToR设备下,确保网络通信仅需一跳即可实现高速传输,大幅提升训练效率。同时,平台还支持Gang/Binpack调度及基于优先级的任务抢占功能,有效提高GPU资源利用率。
大模型训练属于全同步系统,要求所有节点保持高度协同,任何节点性能滞后都会拖慢整体训练进程,这对GPU服务器的同构性和交付质量提出了严苛要求。
为此,小米构建了GPU平台化、自动化交付体系,通过平台完成GPU装机,并校验60+项系统参数,彻底解决机器标准化问题。装机环节全面覆盖GPU、高性能网络、容器运行时、K8s资源与监控上报等核心组件,确保软硬件配置完全一致。
同时,平台具备自动烤机功能,机器加入集群或故障维修后重新接入前,会自动开展基础环境检查、浮点运行性能测试、点对点带宽测试、NCCL测试、GPU Burn烤机测试等一系列验收流程,从源头保障交付质量,为全同步训练系统的高效运行奠定基础。
三、韧性保障:GPU故障自愈系统的全流程自动化
随着训练规模扩大至千卡、万卡级别,GPU设备因高负载运行导致的故障率显著上升。为应对这一挑战,小米设计了一套全流程自动化的GPU故障自愈系统,实现故障检测、处理、替换、维修的闭环管理。该系统与AIE深度联动,可覆盖100+种故障类型,故障检测准确率与召回率均达到99%以上。
在故障响应效率上,系统实现分钟级热备机替换,从故障检测到热备机完成替换的全链路延迟不超过2分钟。针对Job级故障,系统支持自动重试功能,当节点故障时可自动重新拉起任务,预训练任务能够从上一个检查点继续执行,4千卡规模Job的平均故障恢复时间为4分钟,用户感知故障时间不足1分钟,故障自愈成功率超99%,基本无需人工干预,极大降低了故障对训练任务的影响。
四、数据支撑:高性能存储平台的分层构建与开源回馈
AI训练过程中,数据的读取、模型文件的存储与评测分析均依赖高性能存储系统。小米基于开源技术构建了自建高性能文件存储平台,通过分层设计满足不同场景需求。
平台接入层基于JuiceFS构建统一客户端,提供POSIX/HDFS/S3等多种语义支持;
元数据层采用CubeFS multi-raft架构,可支撑百亿级文件存储规模;
高性能基座则依托Ceph Rados存储与NVMe机型,打造全闪存高性能底座。
为进一步提升性能并控制成本,团队自研基于NVMe + RDMA的分布式高性能缓存层,并构建了完善的数据管理服务,实现数据分层存储、生命周期管理、自动沉降与预热等核心能力。
平台针对不同业务场景提供三类存储服务:
原始数据:容量型存储支持千亿文件规模与EB级容量,满足10万核CPU并发处理需求;
训练数据:性能型存储实现TB/s级吞吐与亚毫秒级延迟,可支撑万卡GPU训练;
模型数据:缓存型存储利用GPU节点空闲资源部署,读性能较性能型提升30%且无额外成本。
五、通信优化:高性能网络的适配升级与问题诊断
高性能网络是大模型训练的关键支撑,尤其是MoE模型训练对网络性能提出了更高要求。小米在自建万卡集群中,针对MoE训练场景开展了硬件层与通信库层的专项优化,显著提升网络传输效率。为快速定位网络问题,团队基于开源技术进行自研创新,实现端侧与网络侧指标的深度融合,构建亚秒级网络监控体系,并通过NCCL日志监控与自动分析功能,精准识别通信瓶颈。
同时,团队以云原生资源管理思想抽象高网资源,明确各环节资源交付规范,构建起覆盖基础设施、资源管理、业务平台的全链路高性能网络体系,为大规模模型训练提供稳定的通信保障。
六、上层赋能:训练与推理框架的适配优化及应用落地
在训练框架层面,小米AI平台全面覆盖大模型训练全周期需求。预训练阶段基于NVIDIA Megatron-LM框架,构建完善的系统可观测性能力,支持hang检测与快速故障分析;
监督微调阶段采用LLaMA-Factory框架,打造内部统一的微调工作流;
强化学习后训练阶段则基于Verl框架,与小爱团队合作共建,支持UI-Agent后训练任务,全方位满足不同训练阶段的技术需求。
推理框架方面,团队重点聚焦vLLM与SGLang两大主流框架进行适配优化。
在vLLM框架上,成功实现DeepSeek R1 PP=2多机部署,通过优化离线数据打标流程使性能提升180%以上,并自研动态Profile、NCCL PD分离的KV Cache数据传输策略及多维度监控指标。
在SGLang框架上,针对DeepSeek R1模型打造PD分离+大EP部署方案,经多轮优化达到社区最优性能,同时向社区贡献了10+个PR,包括支持动态Profile、细粒度监控指标、实时专家热力图及EPLB优化等功能。
在应用落地层面,小米基于Dify社区构建了内部AI应用开发平台Mify,已集成100+种国内外主流大模型,用户无需额外配置即可直接使用。
平台具备完善的AI应用开发能力,提供流程控制、工具支持、模型评测、推理网关等核心功能,可与其他业务系统无缝集成,并支持MCP协议、iframe嵌入及API接口调用。团队积极向Dify社区回馈技术成果,向社区贡献了100+个commits,推动开源生态共同发展。
七、总结:以技术创新为核,践行开源与业务协同发展
小米AI引擎团队通过构建四层架构的统一AI技术平台,在算力调度、硬件交付、故障自愈、存储优化、网络通信及框架适配等关键领域实现技术突破,为公司AI业务发展提供了全方位支撑。
同时,团队始终坚守开源理念,在支持内部业务的基础上积极回馈社区,形成“业务需求驱动技术创新,技术创新反哺开源生态”的良性循环。
未来,随着小米AI业务的持续拓展,AI平台将面临更多更高的技术挑战,团队也将继续深耕核心技术研发,深化开源社区参与度,在推动自身技术升级的同时,为全球AI开源生态的发展贡献更多实践经验与技术成果。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...