
编辑/小象
开源大模型圈出了个狠角色,DeepSeek-V3.2这新家伙,推理能力直接干到了新高度。
有测试说它都能跟GPT-5-High掰手腕了,这在以前想都不敢想。
要知道开源模型向来被闭源大佬压着打,这次DeepSeek咋突然逆袭了?核心就俩字:技术。
它不是靠堆算力硬刚,而是玩了波巧劲。
DSA稀疏注意力机制效率革命的核心引擎
传统大模型处理长文本就像堵车,字越多越卡。

为啥?Transformer的注意力机制太实在,每个字都要跟其他字打招呼,复杂度噌噌往上涨。
DeepSeek偏不信邪,搞出个DSA稀疏注意力机制。
你猜怎么着?它不搞”雨露均沾”了,专门挑关键token下手。
就像老师批改作业,先抓重点题看,次要的扫一眼就行。
具体来说,它会选2048个最关键的token重点关注,其他的该放就放。
这操作直接把复杂度从平方级降到线性,效率一下子提上来了。
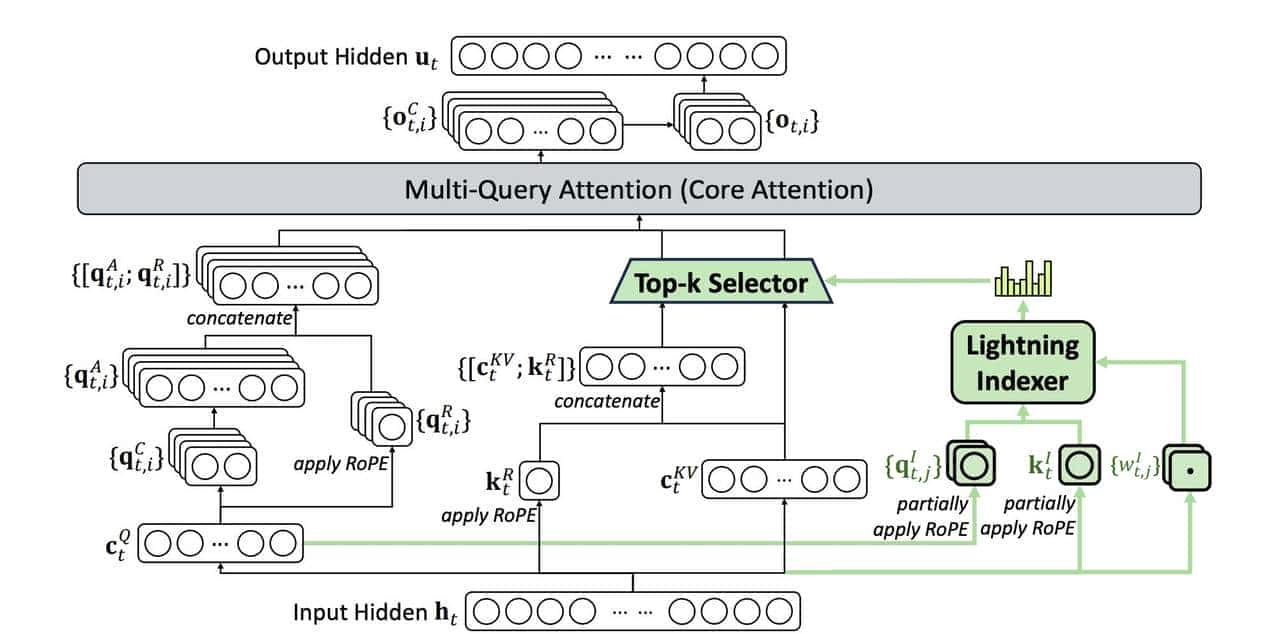
实现这招分两步走。
先是LightningIndexer出马,快速定位哪些token重大,再让
Fine-grainedTokenSelection精细筛选,确保选出来的都是”硬菜”。
这套组合拳下来,模型看长文本就像开了倍速,又快又准。
训练过程也挺讲究,不是一股脑瞎练。
先拿小数据搞DenseWarm-up,冻结主模型光练LightningIndexer,1000步、2.1Btokens练下来,让它知道咋挑重点。
然后再上SparseTraining,全参数上阵,拿943.7Btokens大数据打磨,适应稀疏模式。
这种先慢后快、先精后广的练法,跟咱们上学时先做例题再刷真题一个道理,效果能不好吗?
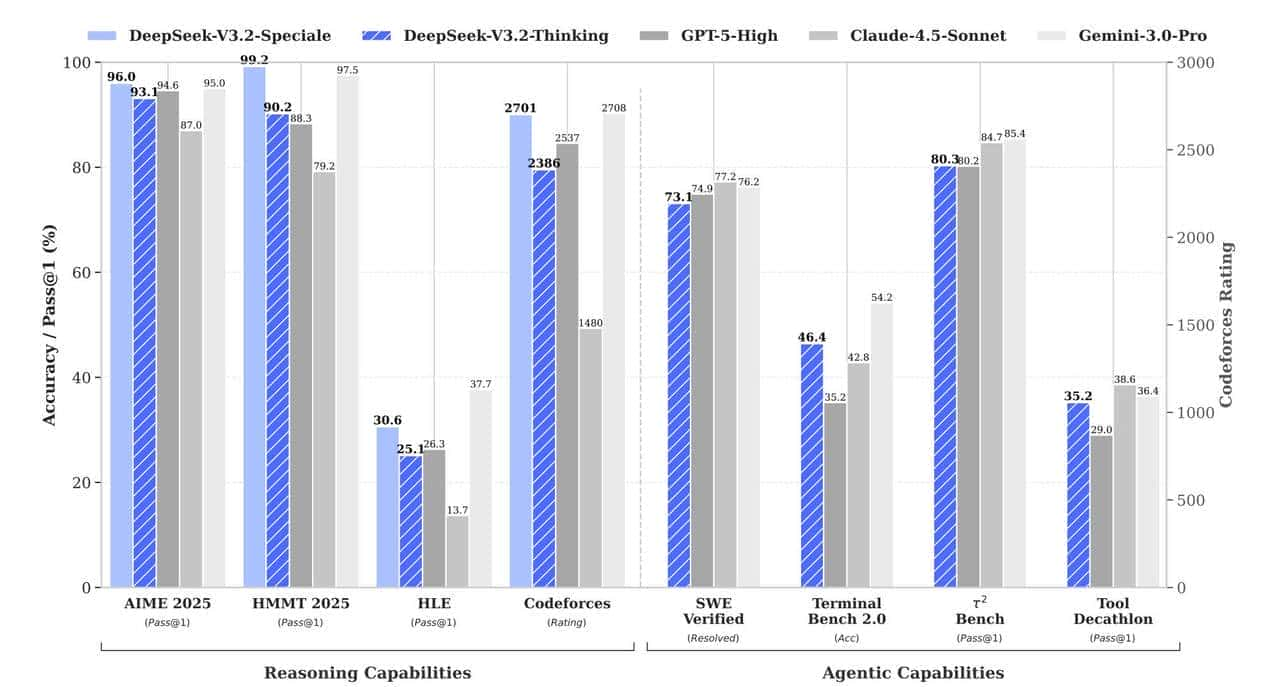
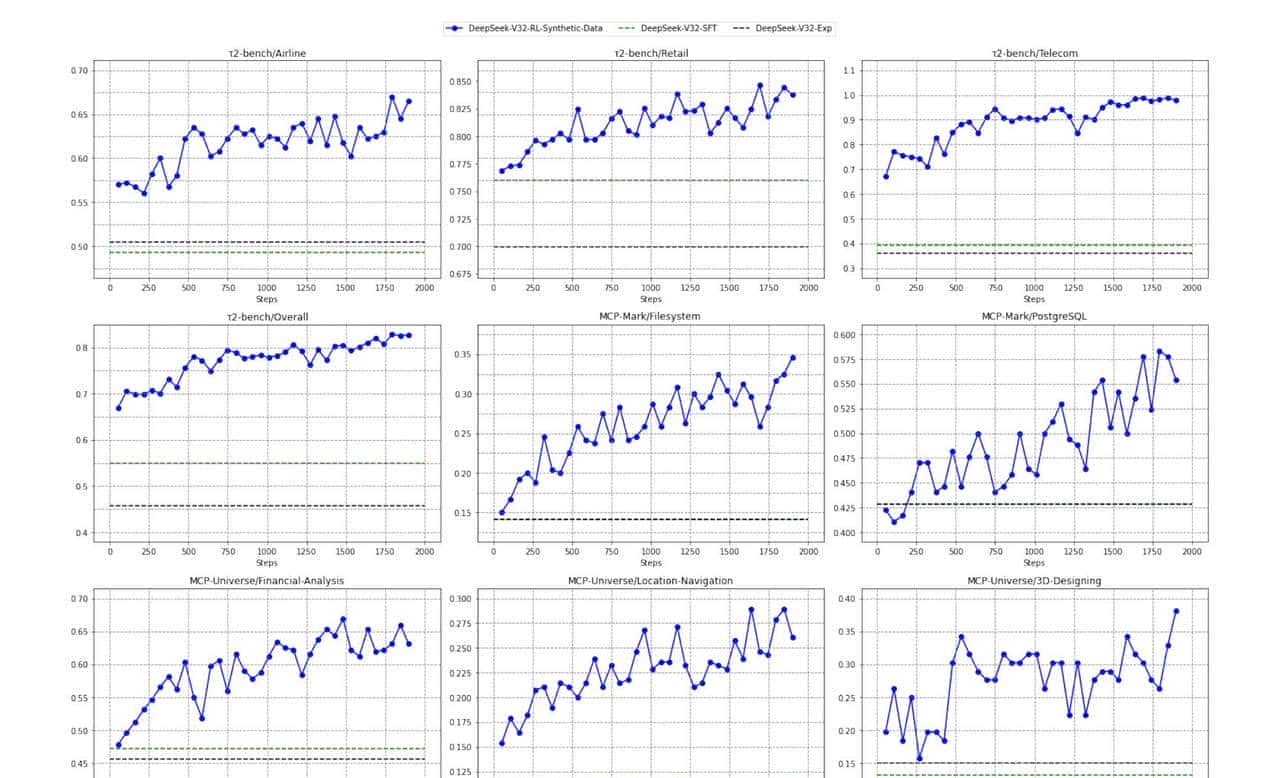
效果的确 肉眼可见。
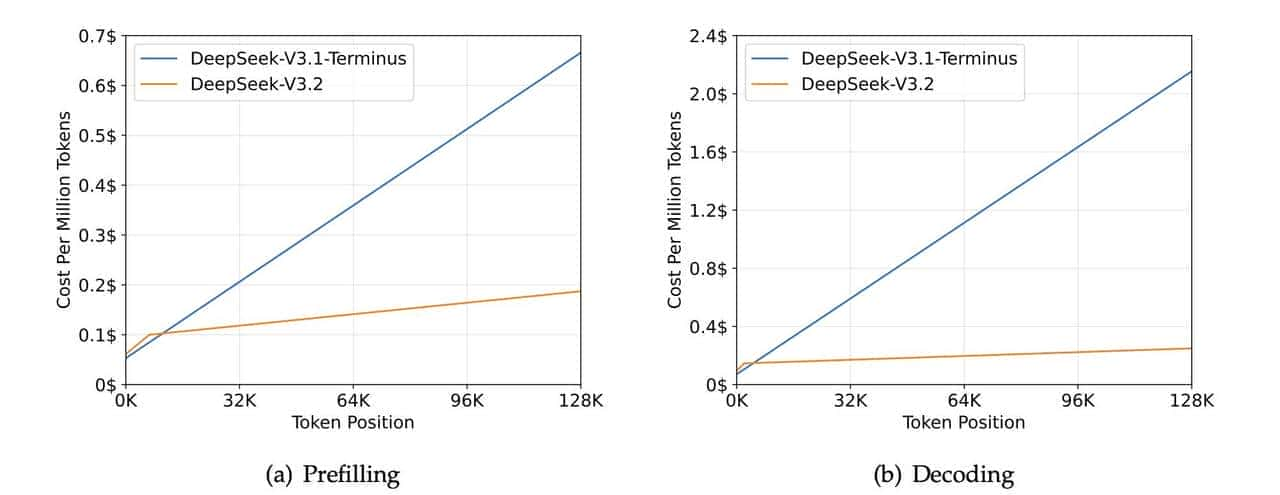
处理128K长度的文本,以前V3.1-Terminus版本费劲得很,目前V3.2嗖嗖的,成本还降了不少。
ChatbotArena评分涨了一大截,长上下文测试里,不管是学术文献还是小说续写,都比同类模型表现稳。
说白了,就是又快又好,这在大模型圈可是稀缺货。
光有效率还不够,模型能力咋提上来的?毕竟用户要的是答案准,不是光跑得快。
DeepSeek在这方面也藏了招,就是后训练策略和数据合成这对组合拳。
后训练策略与数据合成能力跃升的双轮驱动
一般模型预训练完就差不多定型了,DeepSeek偏不。
它在后训练阶段砸的算力,比预训练还多10%。
你没听错,别人收尾它加码,这思路够野。就像考完试别人放假,你接着刷题,成绩能不进步吗?
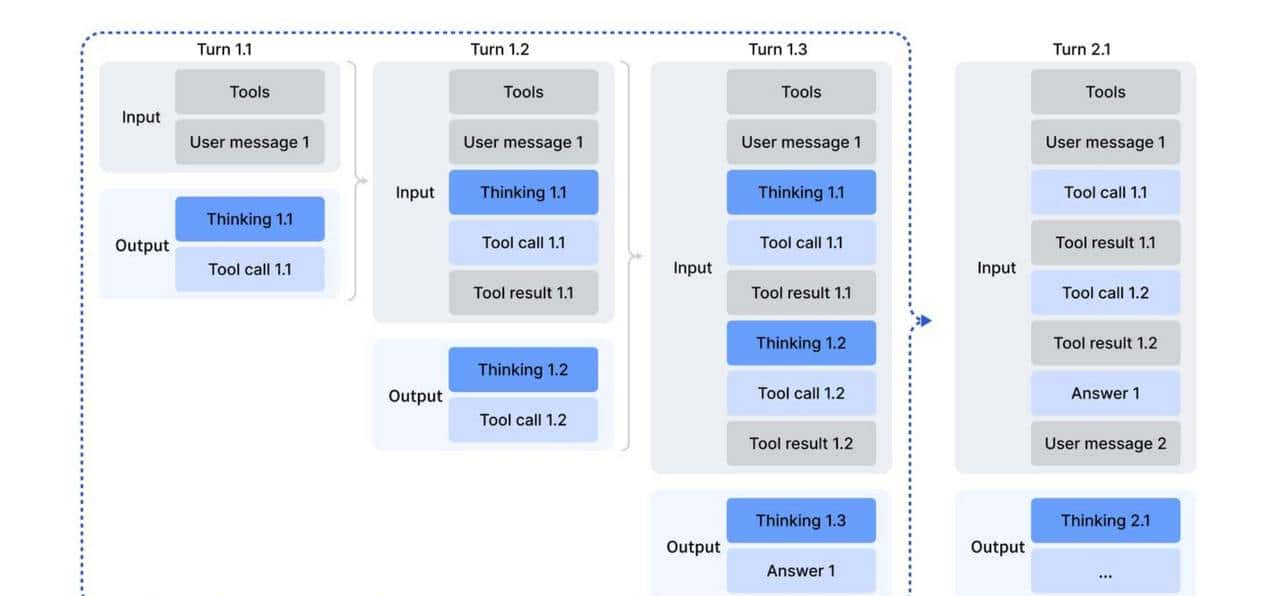
具体咋操作?搞专家蒸馏。
找数学、编程这些硬骨头领域的专家模型当老师,让V3.2跟着学。
六大领域挨个啃,每个领域都练出专项技能。
然后再来个混合RL训练,把多任务揉在一起练,让模型学会灵活切换。
这就像既当单科状元,又当全能选手,能力能不全面吗?
数据这块更绝,它不满足于用现成数据,自己动手合成。

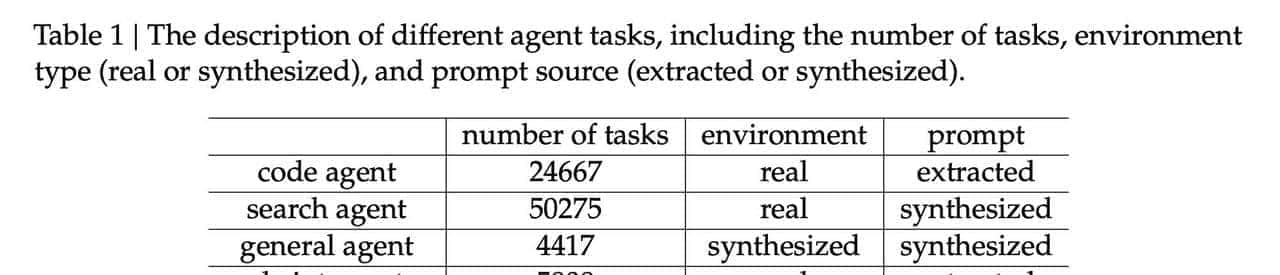
搞了四大类任务,光代码智能体就整了24667个任务。
最妙的是”难解易验”思路,就拿TripPlanning举例,让模型设计复杂行程,再自动检查合不合理。
这种自己出题自己做的方式,数据质量高还不重复,比扒拉公开数据强多了。
有消融实验证明,加了合成数据后,模型泛化能力蹭蹭涨。
以前没见过的题,目前也能蒙对个七八成。
本来想光靠预训练数据撑场面,后来发现还得靠自己造的数据补短板,这波操作的确 秀。
目前开源大模型圈总算清楚,不是堆算力就能赢。
DeepSeek-V3.2这波突破,靠的是DSA机制解决效率问题,后训练和合成数据提升能力,三管齐下。
IMO和IOI竞赛拿金牌,长文本处理不卡顿,这些都是实打实的成绩。
当然它也不是完美的,世界知识储备还差点意思,token效率还有优化空间,跟Gemini-3.0-Pro比顶尖任务还稍逊一筹。
但开源模型能做到这份上,已经给同行指了条明路:巧劲比蛮力更重大,技术创新才是硬道理。
接下来就看其他家咋接招了,开源圈的热闹,怕是才刚刚开始。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...






