一、项目介绍:多智能体驱动的全流程视频生成框架
1. 基础信息
项目名称:ViMax
开发团队:香港大学数据智能实验室(HKUDS,深耕AI多智能体与视频生成领域)
核心定位:一款多智能体协作的端到端视频生成框架,通过“编剧+分镜师+渲染引擎”智能体分工,实现从文本创意/剧本/参考图到完整视频的全流程自动化,支持文本生成视频(T2V)、首帧生成视频(FF2V)、首尾帧生成视频(FLF2V)三种模式,解决传统视频制作流程繁琐、长视频风格漂移、一致性难保障等痛点。
仓库现状:GitHub开源免费(遵循MIT许可证),支持自由使用、修改和分发,整合Google Veo、豆包Seedance等主流视频生成模型,文档完善、代码模块化,适配内容创作者、营销人员、教育工作者等群体,是专业级视频生成的轻量化开源解决方案。
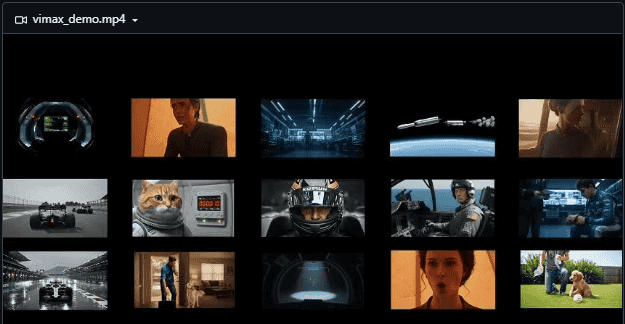
2. 核心技术参数(视频生成类重点突出)
• 架构类型:多智能体模块化架构,包含编剧、分镜师、参考图选择器、渲染引擎四大核心智能体;• 技术栈:基于Python开发,依赖uv包管理工具,集成LLM(Google Gemini 2.5)、视频生成API(Google Veo、豆包Seedance)、视觉校验模型(MLLM/VLM);• 生成能力:支持卡通、写实等多风格视频,最长生成时长适配短视频场景(默认≤3个场景),分辨率/帧率由底层视频生成模型决定(兼容主流API参数);• 核心创新:多智能体分工协作、视觉一致性校验(参考图管理+VLM校验)、多生成模式自适应切换;• 部署要求:Python 3.10+,需配置对应视频生成API密钥(如Google Veo、Gemini),无特殊硬件要求(依赖云端API渲染)。
3. 项目核心价值
传统视频生成工具要么流程碎片化(需手动写剧本、分镜、渲染),要么长视频易出现风格/角色漂移,普通创作者难以快速产出专业内容。ViMax的核心价值在于:
• 全流程自动化:从文本创意到成片无需人工干预,省去剧本撰写、分镜设计、镜头拼接等繁琐步骤;• 一致性保障:通过参考图管理和VLM视觉校验,确保长视频中角色、场景、风格保持统一,解决漂移痛点;• 多模式适配:支持文本、首帧、首尾帧三种输入方式,灵活适配不同创作需求(如无参考图用T2V,有明确风格参考用FF2V);• 低门槛专业级产出:无需影视制作经验,通过自然语言描述即可生成符合影视语言的结构化视频,降低专业视频创作门槛。
二、核心功能:多智能体分工+多模式生成,覆盖视频创作全流程
ViMax以“多智能体协作”为核心,实现视频创作全流程自动化,每个功能模块都直击创作者痛点:
1. 多智能体分工协作:模拟专业影视制作流程
• 核心智能体各司其职,复刻真实影视制作团队协作逻辑:
• 编剧智能体(Screenwriter):基于Google Gemini 2.5 LLM,将模糊文本创意转化为结构化剧本,包含角色、情节、场景描述、对话、动作指导,符合影视叙事逻辑;• 分镜师智能体:根据剧本拆解镜头语言,设计视觉叙事节奏(如远景铺垫、近景刻画),确定每个镜头的时长、角度和核心元素;• 参考图选择器:自动筛选或生成参考图像,作为视频渲染的风格基准,确保所有镜头风格统一;• 渲染引擎:调用Google Veo、豆包Seedance等主流视频生成API,根据输入模式(T2V/FF2V/FLF2V)自适应生成视频,支持异步任务轮询获取结果。
2. 三种生成模式:灵活适配不同创作需求
• 文本生成视频(T2V):无参考图时,直接通过文本创意+风格描述生成视频,适合快速将想法落地为可视化内容(如“面向儿童的卡通视频,一只猫和狗的友谊故事”);• 首帧生成视频(FF2V):上传1张首帧参考图,视频后续镜头保持与首帧一致的风格、角色形象,适合有明确风格参考的场景(如品牌广告、系列短视频);• 首尾帧生成视频(FLF2V):上传首帧和尾帧参考图,视频将自动衔接首尾风格,完成完整叙事,适合有明确开头和结尾要求的剧情类视频。
3. 一致性校验机制:解决长视频漂移痛点
• 核心逻辑:通过“参考图绑定+VLM视觉校验”双重保障,确保长视频中角色、场景、风格不漂移;• 具体实现:参考图选择器将核心视觉元素(如角色形象、色彩基调)存储为基准,VLM模型在每个镜头生成后进行一致性校验,若偏差超过阈值则重新渲染,尤其适合多场景长视频创作。
4. 轻量化集成与灵活扩展
• 主流视频模型适配:无缝集成Google Veo、豆包Seedance等API,用户可根据需求选择底层渲染模型(如追求速度选Gemini 2.5 Flash,追求质量选专业视频生成API);• 模块化扩展:代码结构清晰,支持新增智能体(如新增“剪辑师”智能体优化镜头拼接)、扩展视频生成API(如集成Stable Video Diffusion)、自定义风格模板(如预设“教育科普”“广告营销”风格参数);• 两种核心工作流:支持“创意→视频”(main_idea2video.py)和“剧本→视频”(main_script2video.py),前者适合快速创意落地,后者适合专业剧本可视化。
三、安装使用方法:3步上手,一键生成专业视频
项目安装部署简洁,依赖云端API渲染,普通电脑即可运行,新手5分钟内可完成上手:
1. 环境准备(轻量化要求)
• 硬件要求:无特殊硬件需求,普通办公电脑/笔记本均可;• 系统环境:Windows 10+/Linux(Ubuntu 20.04+)/macOS 12+;• 软件依赖:Python 3.10+,uv包管理工具(推荐),需注册对应视频生成API账号(如Google Veo、豆包Seedance)并获取API密钥。
2. 安装步骤
(1)克隆仓库并安装依赖
# 克隆GitHub仓库
git clone https://github.com/HKUDS/ViMax.git
cd ViMax
# 安装依赖(使用uv包管理工具,速度更快)
uv sync(2)配置API密钥(关键步骤)
• 打开核心配置文件(二选一,根据使用场景选择):
• 创意生成视频:
configs/idea2video.yaml
configs/script2video.yaml
chat_model:
model: google/gemini-2.5-flash-lite-preview-09-2025
api_key: "你的Google Gemini API密钥"
video_generator:
class_path: tools.VideoGeneratorVeoGoogleAPI # 选择Google Veo渲染
api_key: "你的Google Veo API密钥"
# 若选择豆包Seedance,替换为:
# class_path: tools.VideoGeneratorDoubaoSeedanceYunwuAPI
# api_key: "你的豆包API密钥"3. 核心使用流程:两种工作流快速生成视频
(1)创意→视频(适合新手,快速落地想法)
1. 编辑
main_idea2video.py
idea = "一只猫和狗是好朋友,遇到新猫咪并一起玩耍的故事"
user_requirement = "面向6-10岁儿童,情节简单温馨,不超过3个场景"
style = "3D卡通风格,色彩鲜艳,角色圆润可爱"1. 运行脚本:
python main_idea2video.py1. 等待生成:系统自动完成“创意→剧本→分镜→渲染→拼接”,最终输出完整视频文件(默认保存至
output/
(2)剧本→视频(适合专业创作者,精准控制)
1. 编辑
main_script2video.py
script = """
场景1:公园草坪(白天)
角色:小猫咪(白色)、小狗(棕色)
动作:小猫和小狗在追蝴蝶,互相打闹
对话:
小狗:等等我!蝴蝶要飞走啦~
小猫:快来呀,我抓住它啦!
场景2:公园长椅旁(白天)
角色:小猫咪、小狗、新猫咪(橘色)
动作:新猫咪胆怯地靠近,小猫和小狗主动邀请它一起玩
对话:
小猫:你好呀,要不要一起追蝴蝶?
新猫咪:好呀!谢谢你们~
"""
style = "2D手绘风格,柔和色调"1. 运行脚本:
python main_script2video.py1. 查看结果:系统根据剧本拆解镜头,生成符合情节的连贯视频。
四、代码演示:创意生成视频核心逻辑解析
以下是
main_idea2video.py
from agents.screenwriter import ScreenwriterAgent
from agents.storyboard_artist import StoryboardArtistAgent
from tools.video_generator import VideoGeneratorVeoGoogleAPI
from configs.load_config import load_yaml_config
def idea_to_video(idea, user_requirement, style):
# 1. 加载配置(API密钥、模型参数)
config = load_yaml_config("configs/idea2video.yaml")
# 2. 编剧智能体:创意→结构化剧本
screenwriter = ScreenwriterAgent(model_config=config["chat_model"])
story = screenwriter.develop_story(idea, user_requirement) # 扩展创意为完整故事
script = screenwriter.write_script_based_on_story(story, style) # 故事→影视剧本
print("剧本生成完成:
", script)
# 3. 分镜师智能体:剧本→镜头方案
storyboard_artist = StoryboardArtistAgent()
storyboard = storyboard_artist.generate_storyboard(script, style) # 拆解镜头、确定视觉节奏
print("分镜方案生成完成,共{}个镜头".format(len(storyboard["shots"])))
# 4. 渲染引擎:分镜→视频
video_generator = VideoGeneratorVeoGoogleAPI(api_key=config["video_generator"]["api_key"])
# 根据参考图数量选择生成模式(此处无参考图,默认T2V)
video_frames = []
for shot in storyboard["shots"]:
# 调用API生成单个镜头视频
shot_video = video_generator.generate(
prompt=shot["prompt"], # 镜头描述
style=style,
duration=shot["duration"] # 镜头时长(分镜师确定)
)
video_frames.append(shot_video)
# 5. 拼接镜头,输出完整视频
final_video = video_generator.concat_videos(video_frames)
final_video.save("output/idea2video_final.mp4")
print("视频生成完成!保存路径:output/idea2video_final.mp4")
# 调用函数:创意生成视频
if __name__ == "__main__":
idea = "一只猫和狗是好朋友,遇到新猫咪的故事"
user_requirement = "面向儿童,不超过3个场景"
style = "卡通风格"
idea_to_video(idea, user_requirement, style)代码说明:
• 核心逻辑:创意→故事→剧本→分镜→单个镜头生成→拼接,全程多智能体协作自动化;• 关键步骤:编剧智能体负责内容结构化,分镜师智能体负责视觉节奏,渲染引擎负责落地生成,每个环节都可通过配置文件自定义参数;• 可扩展点:支持添加参考图路径(
video_generator.generate
reference_images
五、优势对比:视频生成领域的核心竞争力
作为多智能体视频生成框架,ViMax在“自动化程度、一致性、灵活性”上远超传统工具,具体对比如下:
| 对比维度 | ViMax(HKUDS开源) | 传统视频生成工具(如Runway Gen-2) | 普通多智能体框架(如AutoGPT衍生) |
| 核心定位 | 全流程视频创作自动化 | 单一镜头生成工具 | 通用多智能体,无视频专项优化 |
| 自动化程度 | 高(创意→成片全自动化) | 中(需手动分镜、拼接) | 低(需手动拆解任务) |
| 一致性保障 | 强(参考图+VLM校验) | 弱(长视频易漂移) | 无专项保障 |
| 生成模式 | 支持T2V/FF2V/FLF2V | 以T2V/图生图为主 | 单一模式为主 |
| 易用性 | 高(自然语言输入,无需专业知识) | 中(需熟悉镜头语言) | 低(需配置复杂提示词) |
| 成本 | 低(开源免费,仅API调用费) | 高(订阅制/按次收费) | 中(需自行集成API) |
优势分析:
• 全流程自动化:相比传统工具,省去剧本撰写、分镜设计、镜头拼接等手动步骤,创作效率提升10倍以上;• 一致性突出:专项优化长视频风格一致性,解决传统工具“单镜头好看、多镜头割裂”的痛点;• 低门槛专业级:无需影视制作经验,自然语言即可生成结构化视频,普通创作者也能产出专业内容;• 灵活扩展:模块化设计支持新增视频生成API、智能体角色,适配不同创作场景和质量需求。
局限性
• 依赖外部API:视频渲染依赖Google Veo、豆包等云端API,需API密钥且可能产生调用费用,无本地渲染选项;• 长视频适配有限:目前默认优化短视频场景(≤3个场景),超长视频(如10分钟以上)的叙事连贯性仍需优化;• 风格定制深度不足:风格控制依赖底层API参数,暂无自定义风格训练功能。
六、总结:视频创作的“自动化导演”开源方案
ViMax作为HKUDS开源的多智能体视频生成框架,以“全流程自动化、一致性保障、低门槛专业级”为核心,重新定义了视频创作的效率边界。其多智能体分工协作模式,完美复刻了专业影视制作流程,让普通创作者无需掌握剧本撰写、分镜设计等专业技能,仅通过自然语言描述即可生成高质量视频。
对于内容创作者,它是快速落地创意的“效率神器”,省去繁琐流程,专注创意本身;对于营销人员,它是快速产出广告原型、短视频素材的“轻量化工具”,降低内容制作成本;对于教育工作者,它是快速生成教学视频、动画课件的“辅助工具”,提升教学内容趣味性。
尽管项目依赖外部API、长视频适配有限,但作为开源方案,它提供了完整的多智能体视频生成架构,开发者可基于此扩展本地渲染模型、优化长视频叙事逻辑、新增风格定制功能。随着视频生成技术的发展,ViMax有望进一步降低专业视频创作门槛,成为内容创作领域的主流开源工具。
如果你是内容创作者、营销人员或开发者,想要快速落地视频创意、降低制作成本,这款开源框架绝对值得尝试——它不仅能帮你节省时间,更能让你在无需专业技能的情况下,轻松产出专业级视频内容。
项目地址:https://github.com/HKUDS/ViMax
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...