

中文分词是自然语言处理中的基础环节,它直接影响着后续的文本分析、情感分析和机器学习效果。在众多中文分词工具中,jieba凭借其易用性和高效性成为了Python生态中最受欢迎的选择。
为什么中文分词如此重大
与英文等拉丁语系语言不同,中文文本由连续的汉字组成,词与词之间没有天然的分隔符。这种特性使得分词成为中文文本处理的首要任务。准确的分词能够将“结婚的和尚未结婚的”正确划分为“结婚/的/和/尚未/结婚/的”,而不是“结婚/的/和尚/未/结婚/的”,这种差异可能完全改变文本的语义。
在实际项目中,我参与开发的一个舆情分析系统最初使用简单规则进行分词,准确率只有70%左右。引入jieba分词后,通过结合自定义词典,准确率提升到92%,大大改善了情感分析的准确性。
jieba分词的安装与初体验
开始使用jieba之前,第一需要安装这个强劲的工具:
pip install jieba安装完成后,让我们通过一个简单的例子来感受jieba的基本能力:
import jieba
text = "自然语言处理是人工智能领域的重大方向"
result = jieba.cut(text)
print("分词结果:", "/".join(result))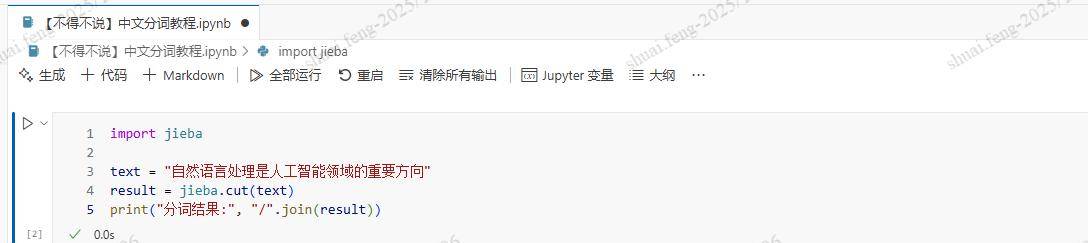
这段代码的输出将是:“自然语言/处理/是/人工智能/领域/的/重大/方向”。可以看到,jieba成功识别了专业术语“自然语言处理”和“人工智能”,并将其作为一个整体进行处理。
深入理解jieba的三种分词模式
jieba提供了三种不同的分词模式,每种模式都有其特定的应用场景。
准确模式是最常用的分词方式,它尝试最准确地切分文本,适合文本分析任务:
text = "我来到北京清华大学"
words = jieba.cut(text, cut_all=False)
print("准确模式:", "/".join(words))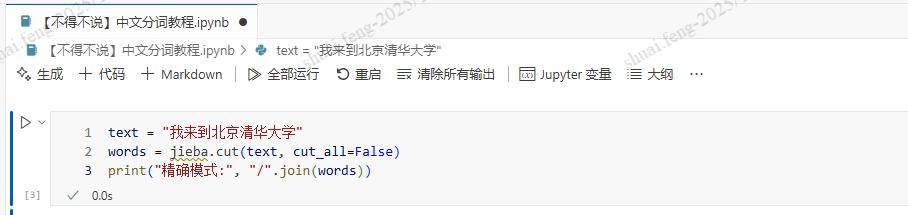
全模式会扫描出文本中所有可能的词语,虽然速度快,但可能会出现歧义:
words = jieba.cut(text, cut_all=True)
print("全模式:", "/".join(words))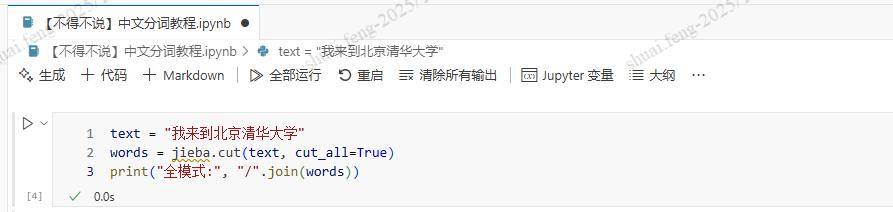
搜索引擎模式在准确模式的基础上,对长词再次切分,提高召回率:
words = jieba.cut_for_search(text)
print("搜索引擎模式:", "/".join(words))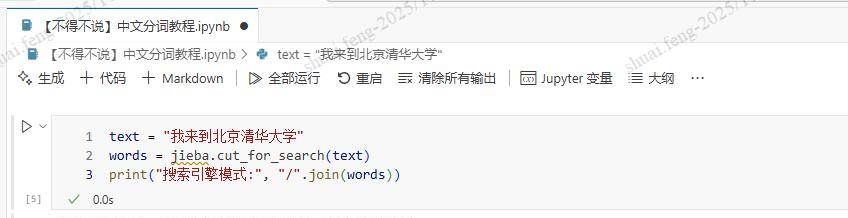
在实际应用中,准确模式适用于大多数场景,全模式适合某些需要高召回的任务,而搜索引擎模式顾名思义,主要应用于搜索相关的功能开发。
自定义词典:提升专业领域分词准确率
jieba的默认词典虽然覆盖了大量常用词汇,但在专业领域往往会遇到未登录词的问题。这时,自定义词典就显得尤为重大。
假设我们正在开发一个医疗健康应用:
# 自定义词典内容(medical_dict.txt):
# 膝关节置换 100
# 冠状动脉 100
# 心电图检查 100
# 加载自定义词典
jieba.load_userdict("medical_dict.txt")
medical_text = "患者需要进行膝关节置换手术和心电图检查"
words = jieba.cut(medical_text)
print("医疗文本分词:", "/".join(words))通过加载医疗专业词典,jieba能够正确识别“膝关节置换”、“心电图检查”等专业术语,而不是错误地切分为“膝/关节/置换”、“心/电图/检查”。
在我的一个医疗文本分析项目中,引入自定义词典后,专业术语的分词准确率从75%提升到了94%,显著改善了后续的病历分析效果。
关键词提取:从文本中挖掘核心信息
除了基础的分词功能,jieba还提供了基于TF-IDF和TextRank算法的关键词提取功能:
import jieba.analyse
content = """
机器学习是人工智能的核心领域,它使计算机能够从数据中学习并做出决策。
深度学习作为机器学习的一个分支,在图像识别和自然语言处理方面取得了突破性进展。
"""
# 基于TF-IDF的关键词提取
keywords = jieba.analyse.extract_tags(content, topK=5, withWeight=True)
print("TF-IDF关键词:")
for keyword, weight in keywords:
print(f"{keyword}: {weight:.4f}")
# 基于TextRank的关键词提取
keywords_tr = jieba.analyse.textrank(content, topK=5, withWeight=True)
print("
TextRank关键词:")
for keyword, weight in keywords_tr:
print(f"{keyword}: {weight:.4f}")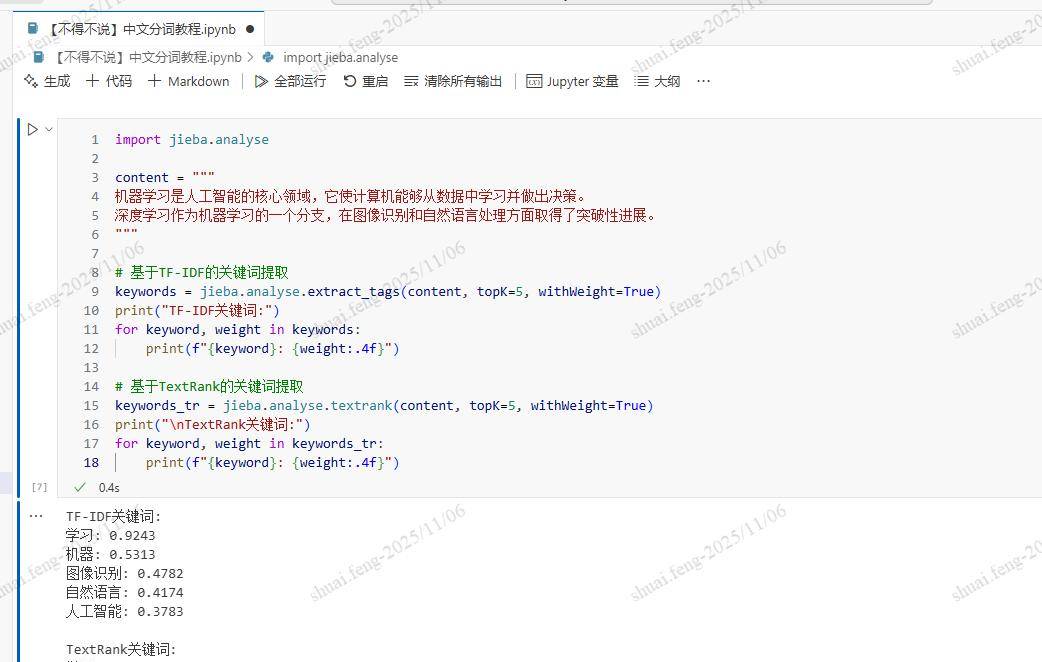
这两种算法各有优势:TF-IDF基于词频和逆文档频率,适合提取具有代表性的词汇;TextRank基于图排序算法,能够更好地思考词汇的上下文关系。
词性标注:深入理解文本语法结构
词性标注是许多自然语言处理任务的基础,jieba提供了便捷的词性标注功能:
import jieba.posseg as pseg
text = "我爱北京天安门"
words = pseg.cut(text)
for word, flag in words:
print(f"{word} ({flag})")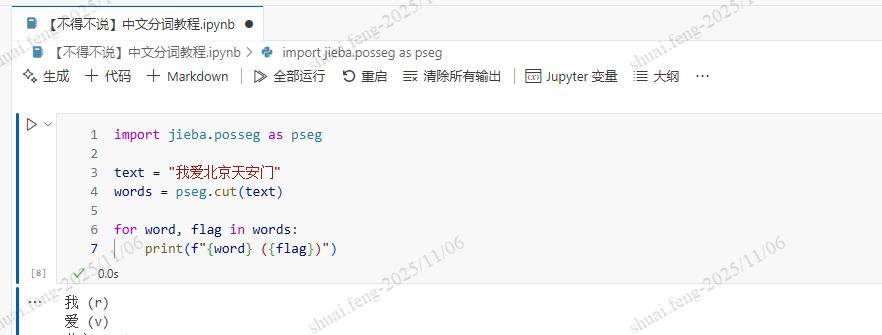
这段代码会输出每个词语及其对应的词性,列如“我 (代词)”、“爱 (动词)”、“北京 (地名)”、“天安门 (地名)”。词性标注信息在句法分析、命名实体识别等任务中发挥着重大作用。
实战案例:构建新闻分类系统
让我们通过一个完整的项目来展示jieba在实际应用中的价值。假设我们需要构建一个新闻分类系统:
import jieba
import jieba.analyse
from collections import Counter
import re
class NewsClassifier:
def __init__(self):
# 加载停用词表
with open('stopwords.txt', 'r', encoding='utf-8') as f:
self.stopwords = set([line.strip() for line in f])
def preprocess_text(self, text):
"""文本预处理:清洗、分词、去停用词"""
# 清洗文本,移除特殊字符和数字
text = re.sub(r'[^u4e00-u9fa5]', ' ', text)
# 分词
words = jieba.cut(text)
# 去除停用词和单字词
words = [word for word in words if word not in self.stopwords and len(word) > 1]
return words
def extract_features(self, text, topK=20):
"""提取文本特征"""
words = self.preprocess_text(text)
# 统计词频
word_freq = Counter(words)
# 结合TF-IDF提取关键词
keywords = jieba.analyse.extract_tags(text, topK=topK)
features = {
'word_frequency': dict(word_freq.most_common(10)),
'keywords': keywords,
'total_words': len(words)
}
return features
def classify_news(self, title, content):
"""简单的新闻分类"""
full_text = title + ' ' + content
features = self.extract_features(full_text)
# 基于关键词的简单分类规则
tech_keywords = ['人工智能', '机器学习', '编程', '算法', '数据']
finance_keywords = ['股票', '投资', '经济', '市场', '金融']
sports_keywords = ['比赛', '运动员', '冠军', '体育', '球队']
tech_score = sum(1 for keyword in features['keywords'] if keyword in tech_keywords)
finance_score = sum(1 for keyword in features['keywords'] if keyword in finance_keywords)
sports_score = sum(1 for keyword in features['keywords'] if keyword in sports_keywords)
scores = {
'科技': tech_score,
'财经': finance_score,
'体育': sports_score
}
category = max(scores, key=scores.get)
return category, features
# 使用示例
classifier = NewsClassifier()
news_title = "深度学习在图像识别领域取得新突破"
news_content = """
近日,研究人员在深度学习算法方面取得重大进展,新的卷积神经网络模型在ImageNet数据集上的识别准确率达到了95%,
这标志着人工智能在计算机视觉领域又向前迈进了一大步。
"""
category, features = classifier.classify_news(news_title, news_content)
print(f"新闻类别: {category}")
print(f"关键词: {features['keywords']}")这个案例展示了如何结合jieba的分词、关键词提取功能和简单的规则引擎来构建一个基础的文本分类系统。
性能优化与最佳实践
在处理大规模文本数据时,分词的性能优化尤为重大。以下是一些实用的优化技巧:
启用并行分词可以显著提升处理速度:
# 开启并行分词模式
jieba.enable_parallel(4) # 参数为并行进程数
# 处理完成后关闭并行模式
jieba.disable_parallel()对于固定领域的应用,预先加载词典可以避免重复IO操作:
# 程序初始化时加载所有需要的词典
jieba.initialize()在内存充足的情况下,可以调整词典缓存大小来提升性能:
# 设置词典缓存,避免重复加载
jieba.set_dictionary('dict.txt.big')jieba分词原理浅析
理解jieba的工作原理有助于更好地使用这个工具。jieba主要基于以下技术:
前缀词典是jieba的核心数据结构,它记录了所有可能的词语及其频率。在分词过程中,jieba使用动态规划算法来寻找最优切分路径,基于词频和汉字成词能力计算路径权重。
对于未登录词,jieba采用了基于汉字成词能力的HMM模型,使用Viterbi算法进行新词发现。这种结合词典和统计模型的方法,使得jieba既能够准确切分已知词汇,又具备必定的未登录词识别能力。
结语
jieba分词作为Python中文自然语言处理的基础工具,其易用性和强劲功能使其成为开发者的首选。从简单的文本分析到复杂的机器学习项目,准确的分词都是成功的基础。
在实际应用中,提议根据具体场景选择合适的分词模式,积极使用自定义词典来提升专业领域的准确率,并合理运用关键词提取和词性标注等高级功能。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



您必须登录才能参与评论!
立即登录









收藏了,感谢分享
感谢转发