
文章目录
一、论文信息摘要1. 引言2. FPDNet2.1. 基线网络2.2. HGNetv22.3. CEDLAM2.4. SIoU损失函数
3. 实验与结果3.1. 实现细节3.2. 消融实验3.3. 对比实验a) 各种损失函数的比较:b) 各种注意力机制的比较:C) 各种缺陷检测算法的比较:
4. 结论引用
一、论文信息
论文题目: FPDNet:A fast and high-precision detection network for hot-rolled strip surface defects中文题目:FPDNet:一种用于热轧带钢表面缺陷的快速高精度检测网络发表期刊:AAAI 2025论文链接:点击跳转代码链接:点击跳转核心速览:基于 YOLOv8 改进,提出 FPDNet 检测网络,通过 HGNetv2 骨干轻量化、CEDLAM 特征增强、SIoU 损失函数优化,在 NEU-DET 数据集上实现 80.8% mAP@IoU=0.5(较基线提升 5.7%)、107.3 FPS,平衡精度与速度,满足热轧带钢缺陷检测的实际生产需求。
摘要
表面缺陷检测对热轧带钢的质量保证至关重要。现有检测模型因缺陷的尺寸差异和低对比度而存在较高漏检率,且计算复杂,导致检测速度缓慢。为解决这些问题,本文提出一种基于YOLOv8的新型快速高精度检测网络(FPDNet)。首先,FPDNet采用高性能GPU网络V2(HGNetv2)作为骨干网络,利用其出色的特征提取能力,并结合GhostConv以实现模型轻量化。其次,提出Csp高效可变形层注意力模块(CEDLAM),以动态感知空间信息,自适应捕捉目标形状和尺度的变化,增强多线性特征关系以聚焦目标关键区域。最后,采用SIoU损失函数以加快模型收敛并提高定位精度。在NEU-DET数据集上的实验结果表明,其mAP@IoU=0.5达到80.8%,较基线提升5.7%,检测速度为107.3 FPS,平衡了精度与速度,满足实际使用需求。该数据集和代码可在https://github.com/jianghhhhhh/FPDNet获取。
1. 引言
热轧带钢是钢材的主要品种之一,广泛应用于工业、农业、交通和建筑领域[1]。在热轧带钢生产过程中,原料、生产工艺和环境因素等多种因素通常会产生影响产品质量的表面缺陷[2]。这些缺陷会损害产品性能并降低产品质量。因此,为了提高热轧带钢的质量,快速、准确地对带钢表面缺陷进行分类和定位至关重要。
热轧带钢表面缺陷的传统识别方法包括人工检测[3]、红外检测[4]、涡流检测[5]和漏磁检测[6]。此外,这些方法受到多种因素的制约,包括检测不及时以及对工人存在危害等,从而限制了生产效率的提升。近年来,先进人工智能技术的出现使得基于深度学习的检测方法逐渐取代传统检测方法。基于深度学习的带钢表面缺陷检测算法可以提高带钢生产线的自动化程度和效率。这些算法不仅降低了质量检验人员的劳动强度、减少了劳动力成本,还在各类应用中具有显著潜力。
近年来,随着深度学习技术的广泛应用,目标检测技术不断突破传统检测器的技术局限,在轻量化、实时性和鲁棒性方向快速发展[7-9]。在两阶段目标检测算法方面,基于区域的卷积神经网络(RCNN)是将深度学习成功整合到目标检测中的开创性算法,由Girshick等人于2014年首次提出[10],RCNN显著提升了目标检测的效果,同时也改变了该领域的研究重心。后续出现的Fast RCNN [11]、Faster RCNN [12]等改进版本不断提高了目标检测的速度和精度。尽管两阶段算法精度较高,但其推理过程会生成大量候选区域,导致计算量和时间复杂度增加,从而使速度变慢。在单阶段目标检测算法方面,常见的有You Only Look Once(YOLO)系列和SSD [13]。它们比两阶段目标识别算法更快,因为它们直接从输入图像预测目标的类别和位置,而不生成候选图像。YOLO框架在速度和精度之间提供了惊人的平衡,能够快速且可靠地检测图像中的物体。Joseph Redmon等人于2016年推出的第一个YOLO版本[14]标志着一系列重大进展的开始。YOLOv1采用基于网格的检测和非极大值抑制(NMS)。2018年,YOLOv3 [15]引入了DarkNet-53骨干网络、多尺度预测和特征金字塔,增强了检测能力。到2020年,YOLOv5 [16]整合了Focus结构和多正样本匹配,进一步提高了精度和效率。2023年,Jocher Glenn等人提出了YOLOv8 [17],通过采用C2f结构、解耦头和无锚点(Anchor-Free)设计提高了速度和精度。TaskAlignedAssigner [18]通过优化样本分配进一步增强了泛化能力和精度。
目前,深度学习技术已被广泛应用于钢铁产品的表面缺陷检测。2020年,在NEU-DET数据集上,He等人提出了一种端到端的特征融合网络,将低层次特征与高层次特征相结合[19],从而实现了对多层次特征的更全面表征,基准网络ResNet34/50分别达到了74.8/82.3 mAP和17.1/11.0 FPS。2021年,在同一数据集上,Hao等人提出了一种可变形卷积骨干网络,具有平衡的特征金字塔特征融合网络,达到了80.5 mAP和43.5 FPS。Yu等人提出了一种双向特征融合网络,并融入了通道注意力机制模块,达到了76.68 mAP和18.0 FPS [21]。2022年,Tian等人提出了一种使用扩展检测器感受野和中心性函数加权的模型,达到了79.41 mAP和71.37 FPS [22]。Wang等人提出了跳层连接模块、金字塔特征融合模块,并将它们整合到ResNet-dcn中,实现了80.0 mAP和64 FPS [23]。2023年,Li等人提出以YOLOv4为基准网络,开发了包含卷积编码器-解码器的残差块和带有注意力机制的特征对齐模块,达到了79.88 mAP和30.76 FPS [24]。Liu等人提出了具有不同膨胀率的并行卷积架构和特征增强与选择模块,实现了79.4 mAP和14.1 FPS [25]。Xin等人提出了一种将CBAM与BiFPN相结合以改进yolov5的算法,实现了77.5 mAP和92 FPS [26]。
从上述综述可以看出,在过去几年中,基于深度学习的热轧带钢表面缺陷检测在检测精度和速度方面取得了一些进展。然而,仍然存在难以平衡检测精度和速度的问题。因此,为了在热轧带钢表面缺陷检测中同时实现速度和精度,本文提出了一种名为FPDNet的缺陷检测网络。具体而言,为了提高检测速度并减少参数,FPDNet模型采用了一种新型骨干网络HGNetv2,该网络引入了比原始骨干网络更轻量的卷积模块和深度可分离卷积,从而提升了模型的检测性能。为了进一步提高精度,该模型在其特征融合网络中融入了CEDLAM,通过增强的可变形卷积处理不规则的带钢表面缺陷,并利用注意力机制处理低对比度缺陷。这使得在处理目标边界时,模型能够更准确地拟合目标的形状和尺寸,从而增强模型的鲁棒性。
综上所述,主要贡献如下。
(1)本文提出了一种用于热轧带钢的高效表面缺陷检测模型FPDNet,有效提高了模型的检测精度并减少了其参数数量。
(2)将CEDLAM引入特征融合网络,其增强的注意力学习能力的偏移量提高了模型提取不规则和低对比度缺陷的有效性。
(3)本文进行的实验表明,我们的网络运行速度为107.3 FPS,mAP为80.8%,完全符合实际生产的要求。
2. FPDNet
图1展示了所提出的FPDNet的整体架构,主要由特征提取、特征融合和预测网络组成。为了通过扩大感受野来提取全局特征信息,特征提取网络采用多尺度融合模块结合SPPF模块。特征融合网络采用路径聚合特征金字塔网络(PAFPN)[27]的结构,将低层空间特征与高层语义特征双向融合,使图像特征更全面、更丰富。为了进一步提高模型提取不规则和低对比度缺陷的能力,引入了CEDLAM。以下是对特征提取网络和CEDLAM的详细描述。

2.1. 基线网络
YOLOv8由Ultralytics于2023年发布,它在之前版本的成功基础上,通过引入新特性和改进来提高速度、准确性和灵活性。具体创新包括改进的C2f模块,其设计参考了C3 [16]模块和ELAN [28],C2f模块增加了更多的跳层连接,移除了分支中的卷积操作,并增加了一个额外的分割操作,使模型能够获得关于梯度流的更丰富信息,同时实现轻量化。此外,头部被替换为解耦头结构,该结构将分类头与检测头分离。它还从基于锚点(Anchor-Based)改为无锚点(Anchor-Free),这意味着它通过预测目标中心的偏移量来直接预测目标框架,而不是通过预测锚点框的偏移量。无锚点模型避免了使用预定义的锚点框,因此模型可以更自由地适应目标的变化。考虑到热轧带钢图像存在缺陷尺寸和形状变化大、特征种类区分不明显以及缺陷与背景对比度低等问题,本文综合考虑YOLOv8作为实时目标检测算法的优势,选择其作为基线网络。
作为实时目标检测算法,YOLOv8在速度和精度方面有很大提升。然而,YOLOv8在特征提取方面也存在不足。一方面,其骨干网络是跨阶段局部Darknet(CSPDarknet),这是一种深层卷积神经网络,能够提取高层语义特征,但这也增加了计算时间和参数数量,可能导致过拟合和训练不稳定。另一方面,它采用PAFPN来融合不同尺度的特征,可能导致信息冗余和特征模糊。
为了提高YOLOv8的性能,本文设计了一种新型热轧带钢表面缺陷检测网络,其结构如图1所示。首先,为了提高网络提取特征的能力,将YOLOv8的骨干替换为HGNetv2,同时用GhostConv增强HGBlock,使模型更轻量化。其次,我们在可变形卷积网络V2(DCNv2)[29]的基础上,结合多线性主坐标注意力V2(MPCA)设计了CEDLAM,该模块用于处理不规则和低对比度的缺陷特征。最后,我们使用SIoU [30]来加快模型收敛并提高定位精度。
2.2. HGNetv2
HGNetv2是百度飞桨视觉团队提出的RT-DETR [31]骨干网络,在多种视觉任务中表现出色。该骨干网络采用可学习下采样层(LDS Layer),通过学习掩码矩阵从特征图中选择性保留或丢弃像素,减少信息损失并提高下采样效率。此外,该网络利用多尺度特征融合,通过应用不同大小的卷积核来增强鲁棒性,以捕捉不同尺寸的目标。由于HGNetv2的高效性,本模型将其用作骨干网络,以更完善地提取缺陷特征信息。
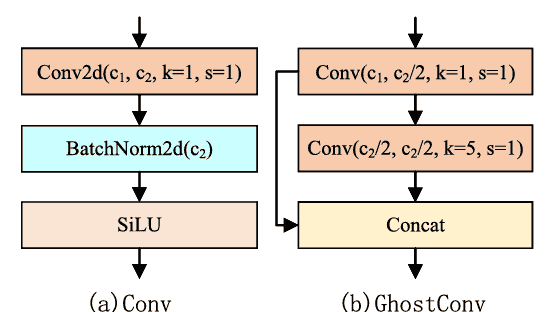
同时,在HGBlock模块中应用GhostConv [32]以最小化模型参数。如图2中GhostConv的结构所示,GhostConv首先使用卷积层生成指定通道数的特征图,然后通过卷积核为5×5、步长为1的“廉价操作”生成另一半特征图。之后,将这两部分特征图拼接成一个完整的特征图。通过将少量卷积核与更廉价的线性变换操作相结合,可以在不降低模型性能的情况下有效降低对计算资源的需求。实验表明,与CSPDarkNet骨干网络相比,改进后的HGNetv2特征提取网络在速度和精度上都有显著提升。
2.3. CEDLAM
在带钢表面缺陷图像中,存在多种缺陷类型且尺度差异显著。传统卷积核通常尺寸固定,难以适应不同目标尺寸,因此削弱了模型对大尺度变化目标的检测性能。为提高网络检测效率,我们采用CEDLAM来更高效地提取特征。
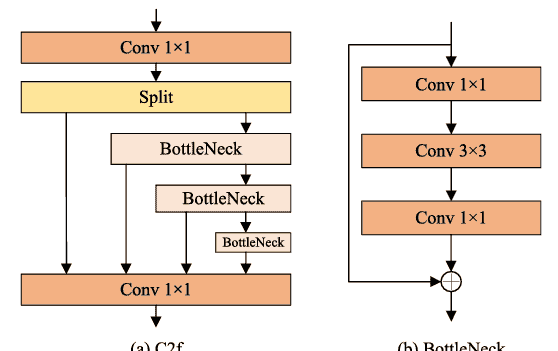
CEDLAM基于YOLOv8的C2f模块进行优化设计。如图3所示,C2f模块的核心基于多层次融合和跨层连接的原理。C2f模块最初将输入特征分为两部分,用于深度处理和跳连,以确保跨层信息的完整性。深度处理组件将经历一系列瓶颈模块以生成中间特征,对所有瓶颈模块生成的中间特征进行级联融合以获得融合特征,最后,拼接跳连特征以获得输出特征。瓶颈模块逐层处理特征图,可以在不同尺度捕捉更丰富的语义信息。浅层特征通过跳连保留,使深浅信息在拼接后协同工作。然而,瓶颈模块通过减少通道数或特征维度来降低计算量。这种降维方法导致一些详细信息的丢失,模型捕捉关键特征的能力减弱,从而制约检测性能。
为解决该问题,我们提出改进的DCCA模块来替代瓶颈模块。将DCNv2和MPCA融入DCCA模块,在保持计算效率的同时显著增强了特征提取的灵活性,并有效保留细节信息。具体而言,DCNv2使用可变形卷积动态调整感受野,使网络能够适应不同尺度和形状的物体。MPCA通过捕捉多线性特征关系来增强关键区域的特征表示,改善低对比度区域的特征提取,并有效表征复杂目标。该设计解决了瓶颈模块在处理详细信息方面的不足,同时增强了模型的鲁棒性和适应性。
DCNv2具有DCN特有的调制机制,该机制使模块能够操纵输入特征的幅度,同时调整感知输入特征偏移的各种空间位置。可变形卷积在传统卷积操作的基础上进行改进,引入可学习的偏移量来调整核的采样位置,使核能够适应不同位置的特征提取。DCNv2的公式可定义为:
其中,
K
K
K 表示卷积核的
K
K
K 个采样位置,
w
k
w_k
wk 和
p
k
p_k
pk 分别表示第
k
k
k 个位置的权重和预先指定的偏移量。
Δ
p
k
Delta p_k
Δpk 和
Δ
w
k
Delta w_k
Δwk 分别是第
k
k
k 个位置的可学习偏移量和调制标量。
Δ
m
k
Delta m_k
Δmk 是取值范围无限的实数,而
Δ
p
k
Delta p_k
Δpk 的范围是
[
0
,
1
]
[0, 1]
[0,1]。输入特征图由一个保持相同分辨率的卷积层处理,输出具有
3
K
3K
3K 个通道。其中,前
2
K
2K
2K 个通道代表学习到的偏移量
(
Δ
p
k
)
k
=
1
K
(Delta p_k)_{k=1}^K
(Δpk)k=1K,最后
K
K
K 个通道被导向一个 sigmoid 层,以确定调制量
(
Δ
m
k
)
k
=
1
K
(Delta m_k)^{K}_{k=1}
(Δmk)k=1K。
如图1中 MPCA 的结构所示,为进一步强化模块的注意力表达,MPCA 在 Coordinate Attention (CA) [33] 的基础上进行改进,引入了增强的全局平均池化(GAP)分支。其公式可定义为:
此外,输入
x
x
x 经过 GAP 分支。在 GAP 和
1
×
1
1×1
1×1 卷积之后,将其与 sigmoid 函数的结果相乘,以获得全局注意力权重
g
c
g_c
gc。公式可定义为:
MPCA 能够同时考虑通道和空间维度的注意力,通过学习增强的宽和高维度权重以及全局注意力权重,使模型更关注有用的特征信息。
实验结果表明,在 DCNv2 模块之后引入 MPCA 可以显著增强模型检测不规则和低对比度缺陷的能力。此外,C2f 残差模块通常使用瓶颈结构模块进行通道调整,然后使用
3
×
3
3×3
3×3 卷积模块进行特征提取和残差拼接,这显著减少了参数数量和计算量。因此,该模型提出使用 CEDLAM 来改进原始的 C2f 模块。
2.4. SIoU损失函数
定义损失函数直接影响目标检测模型在训练过程中的收敛速度和推理精度。传统损失函数考虑了预测框与真实框的重叠区域、中心点距离、预测宽高比等,但往往忽视了预测框与真实框的方向不匹配。这一问题导致模型训练时收敛更慢、预测精度更低。相比之下,SIoU考虑了预测框与真实框的向量角度,从而在训练中提供更稳定的梯度优化和更准确的目标定位。
SIoU包含四个部分:角度损失、距离损失、形状损失和IoU。
角度损失的公式可定义为:
距离损失的公式可定义为:
形状损失的公式可定义为:
IoU是预测框与真实框的交并比。IoU的公式可定义为:
综上,SIoU的公式可定义为:
作为YOLOv8的初始损失函数,CIoU对边界框的大小和尺度变化更敏感,在处理不同尺寸的目标时需要额外调整参数。使用SIoU替代CIoU可以有效解决这一问题,并提高训练速度和预测精度。
3. 实验与结果
3.1. 实现细节
FPDNet在NVIDIA RTX3090 GPU硬件平台上实现并进行实验,深度学习框架为PyTorch 1.13.1和ultralytics版本8.0.202,编程语言为Python 3.8.13。训练图像分辨率设置为416×416像素,批次大小为64,总迭代次数设为170。我们使用Adam优化器,配置权重衰减参数为0.0005,学习率为0.01,动量值为0.937。训练过程中,我们采用概率为50%的mosaic数据增强,并在最后30%的训练过程中禁用特征随机化。这种数据增强方法随机选择四张图像进行缩放、旋转、翻转和颜色变换,然后将这些修改后的图像合并成一张新的图像,添加到训练集中。
本文使用的数据集是NEU-DET [19],由东北大学提供。它包含六种常见的热轧带钢缺陷类型:裂纹(Cr)、氧化铁皮压入(Rs)、斑块(Pa)、麻点表面(Ps)、夹杂(In)和划痕(Sc),并提供了这些缺陷的标注文件。缺陷样本如图4所示。每种缺陷类型有300张灰度图像,图像尺寸为200×200,共1800张灰度图像。数据集按7:3的比例随机分为训练集和测试集。

为了验证所提方法的泛化能力,使用GC10-DET数据集 [34] 进行实验,该数据集包含10种表面缺陷:冲孔(Ph)、焊缝(Wl)、月牙缝(Cg)、水斑(Ws)、油斑(Os)、丝斑(Ss)、夹杂(In)、滚坑(Rp)、折痕(Cr)和腰折(Wf)。缺陷样本如图5所示。该数据集共包含2294张图像,每张图像分辨率为2048×1000像素。图像按7:1:2的比例随机分为训练集、验证集和测试集。

3.2. 消融实验
在本文中,我们的基线网络是YOLOv8,并对每个增强模块(包括HGNetv2、CEDLAM和SIoU)进行渐近测试,以验证FPDNet的有效性。消融实验结果如表1所示。首先,在骨干网络方面,轻量化HGNetv2的使用显著提高了检测精度和速度,同时大幅减少了参数数量,mAP值从基线网络YOLOv8的75.1%提高到78.5%。其次,在特征融合网络中应用CEDLAM后,mAP值上升到80.3%。由于可变形卷积引入了额外的可学习参数,涉及额外的变形采样过程,且注意力机制必须为每个通道或空间位置计算注意力权重,整体计算复杂度增加,导致模型检测速度变慢。然而,考虑到精度的提升,速度的降低是可接受的。最后,SIoU的集成将FPDNet的mAP提高到80.8%,证实了其在提高检测精度方面的有效性。

3.3. 对比实验
a) 各种损失函数的比较:
将所提算法与CIoU [35]、DIoU [36]、GIoU [37]和EIoU [38]进行评估,以验证SIoU的有效性。比较结果如表2所示。CIoU算法在检测Cr缺陷时达到80.3%的mAP和49.9%的AP性能,但在检测Rs时仅为66.3%。DIoU算法的mAP为79.4%,在检测Cr时表现最差,为45.6%。GIoU算法的性能相对均衡,mAP为80.1%。EIoU算法在检测Sc时表现最差,AP仅为94.1%,在检测Rs时表现也很差。另一方面,SIoU算法达到80.8%的mAP。尽管在检测In时AP表现不佳,但在所有其他缺陷上均表现出良好的AP性能。

b) 各种注意力机制的比较:
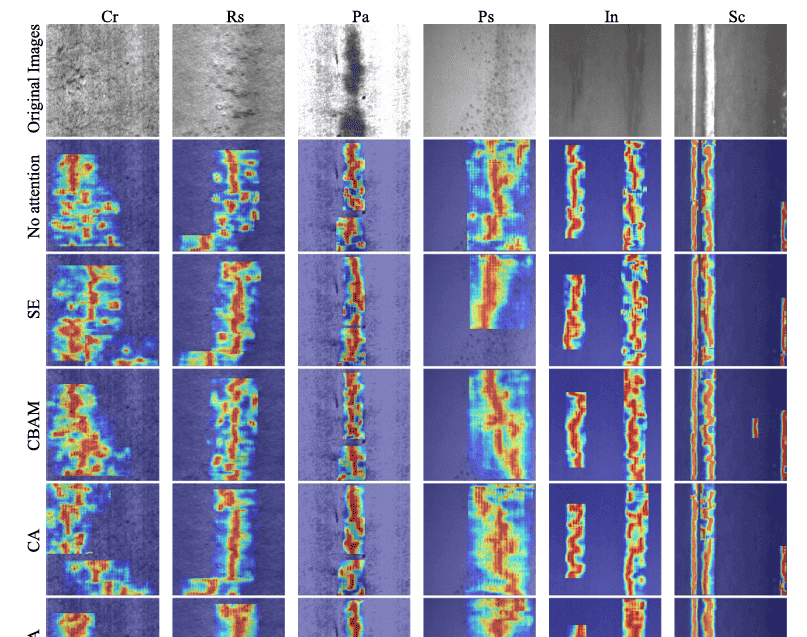
通过将FPDNet与其他注意力机制(包括SE [39]、CBAM [40]、CA [33])进行比较,验证其有效性。不同注意力机制生成的热力图可视化如图6所示。结果表明,无注意力机制的方法和采用SE注意力的方法对于Rs、Cr等低对比度缺陷存在过多噪声信息。采用CBAM的方法存在未关注的缺陷区域,导致检测精度较低。尽管采用CA的方法没有未关注的缺陷区域,但注意力定位不准确。相比之下,MPCA对缺陷定位的热力值更高,定位更准确。表3展示了比较结果。可以观察到,SE注意力算法在检测Cr时表现最差,仅达到43.6%。CBAM注意力算法在检测Cr和Rs时表现不佳,但整体性能较基线略有提升。CA注意力算法在检测Cr和Rs时表现不佳,但其性能较原始模型略有提升。相比之下,SE和CBAM注意力算法在检测Cr和Rs时表现更好,分别达到47.5%和67.5%,mAP值达到80.1%。相反,MPCA注意力算法在检测Cr、Rs和Ps时表现良好,分别达到49.4%、69.9%和88.4%,最高mAP达到80.8%。实验结果表明,MPCA显著提高了低对比度缺陷的检测能力。

C) 各种缺陷检测算法的比较:
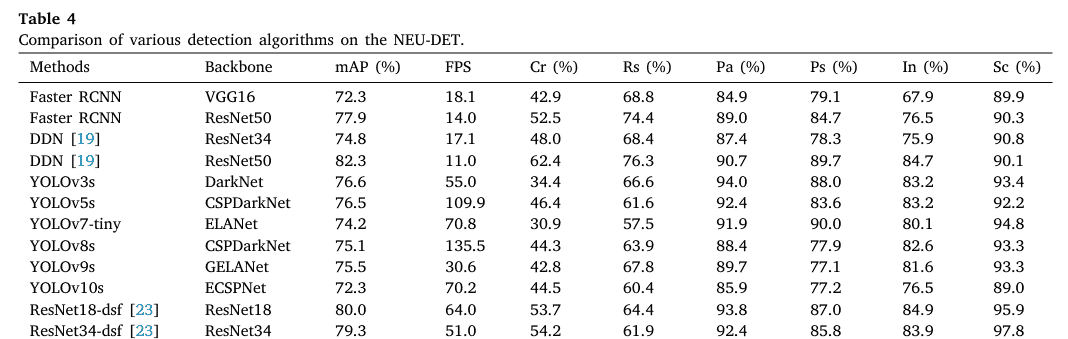
通过将FPDNet与其他检测算法(包括两阶段方法如Faster RCNN和DDN [19],以及单阶段方法如YOLOv3、YOLOv5、YOLOv7-tiny [28]、YOLOv8、YOLOv9 [41]、YOLOv10 [42]、ResNet18/34-dsf [23]和EFD-YOLOv4 [24])进行比较,验证其有效性。每种算法的检测结果如表4所示。根据表4,两阶段方法精度优异但速度不足。例如,以ResNet50为骨干网络的DDN达到82.3%的mAP,但无法满足实际生产应用的速度需求。与两阶段方法相比,单阶段方法精度稍低,但检测速度显著提升。例如,YOLOv9达到75.5%的mAP和30.6 FPS。其可编程梯度信息(PGI)有助于减轻信息损失,但引入了梯度冗余,这归因于其可逆架构,增加了对小或复杂纹理缺陷的敏感性。此外,GELANet的特征聚合增加了计算开销,进一步限制了推理速度。另一方面,YOLOv10达到72.3%的mAP和70.2 FPS。其部分自注意力(PSA)通过计算部分像素关系提高了效率,但难以捕捉全局信息,特别是在复杂背景中的缺陷。此外,大核卷积会破坏边缘和纹理等浅层特征,阻碍小缺陷的检测。为了缓解这些限制并提高速度,引入了HGNetv2和CEDLAM以提高检测精度。最终,FPDNet达到80.8%的mAP和107.3 FPS。图7展示了不同算法的检测结果。如图7所示,在检测低对比度缺陷方面,FPDNet与YOLOv8s相比可以完全检测所有缺陷。在In和Sc等不规则缺陷方面,FPDNet可以更精确地定位缺陷。这表明本文提出的FPDNet可以有效实现热轧带钢表面缺陷的快速精确检测。


为了验证所提方法的泛化能力,使用GC10-DET数据集进行实验。表5展示了各种算法在该数据集上的检测结果。可以观察到,YOLOv5s的mAP为64.7%,FPS为51.2,在精度和速度之间取得了平衡。然而,与其他算法相比,其精度较低,特别是在检测Os和Ss等复杂缺陷时。YOLOv7-tiny的mAP为61.6%,FPS为43.3,对In和Rp的检测精度降低,表明在处理复杂背景时鲁棒性较差。YOLOv8s在处理速度上有显著提升,mAP为64.2%,FPS为70.5。然而,在处理更复杂的缺陷(如Ss和Os)时,其性能下降。YOLOv9的mAP为60.2%,FPS为46.4,与YOLOv8s相比检测速度降低,且在检测复杂缺陷时表现不佳。YOLOv10的mAP为59.6%,FPS为49.8。尽管速度有所提高,但在Ph和Cg等类别中仍无法达到最佳检测精度。相比之下,FPDNet的mAP为66.8%,FPS为56.9,在精度和速度之间取得了最佳平衡。它在检测各种缺陷方面优于其他算法,显示出在处理复杂缺陷方面的显著优势。图8展示了各种算法在GC10-DET上的检测结果可视化。该图显示,与YOLOv8s相比,FPDNet在检测Wl和Cr等类似缺陷方面具有显著优势。此外,FPDNet在处理包括Os和Ss在内的低对比度图像方面表现出色,能够准确捕捉微弱或细微的缺陷特征。这表明FPDNet在复杂缺陷检测任务中更具鲁棒性和适应性。

4. 结论
针对热轧带钢中高难度表面缺陷检测且识别精度低的挑战,本文提出了FPDNet。为捕捉更全面且具代表性的特征信息,该算法将HGNetv2骨干网络整合到YOLOv8中。此外,我们在特征融合网络中引入CEDLAM,以解决不规则和低对比度缺陷问题。最终,FPDNet实现了80.8%的mAP和107.3 FPS。尽管所提方法具有轻量化特性,但仍包含850万参数和21.7 GFLOPs,这限制了它仅能在高性能GPU平台上运行。因此,未来工作可在以下方面进行改进:(1) 探索轻量化技术,以便将模型嵌入移动设备或其他资源受限环境;(2) 采用显著目标检测算法以获得更精确的缺陷边界。
引用
[1] Qiwu Luo, Xiaoxin Fang, Li Liu, Chunhua Yang, Yichuang Sun, Automated visual defect detection for flat steel surface: A survey, (ISSN: 0018-9456) 69 (3) (2020) 626–644.
[2] Xin Wen, Jvran Shan, Yu He, Kechen Song, Steel surface defect recognition: A survey, (ISSN: 2079-6412) 13 (1) (2022) 17.
[3] Z. Luo, B. Wang, D. Liu, X. Lu, T. Steel Jiang, Development of inspection system for steel strip surface defect, (ISSN: 0449-749X) 31 (1996) 127–131.
[4] Zizhuang Song, Jiawei Yang, Dongfang Zhang, Shiqiang Wang, Zheng Li, Semi-supervised dim and small infrared ship detection network based on haar wavelet, (ISSN: 2169-3536) 9 (2021) 29686–29695.
[5] Guo-Hou Li, Ping-Jie Huang, Pei-Hua Chen, Di-Ho HOU, Guang-Xin Zhang, Ze Kui Zhou, Application of eddy current testing in the quantitative evaluation of rail cracks, (ISSN: 1008-973X) 45 (11) (2011) 2038–2042.
[6] Ping Wang, Longhui Xiong, Yinchun Sun, Haitao Wang, Guiyun Tian, Features extraction of sensor array based PMFL technology for detection of rail cracks, (ISSN: 0263-2241) 47 (2014) 613–626.
[7] David A. Forsyth, Jean Ponce, Computer Vision: A Modern Approach, prentice hall professional technical reference, ISBN: 0130851981, 2002.
[8] Zhengxia Zou, Keyan Chen, Zhenwei Shi, Yuhong Guo, Jieping Ye, Object detection in 20 years: A survey, (ISSN: 0018-9219) 2023.
[9] Zhong-Qiu Zhao, Peng Zheng, Shou-tao Xu, Xindong IEEE transactions on neural networks Wu, learning systems, Object detection with deep learning: A review, (ISSN: 2162-237X) 30 (11) (2019) 3212–3232.
[10] Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik, Rich feature hierarchies for accurate object detection and semantic segmentation, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 580–587.
[11] Ross Girshick, Fast r-cnn, in: Proceedings of the IEEE International Conference on Computer Vision, pp. 1440–1448.
[12] Shaoqing Ren, Kaiming He, Ross B. Girshick, Jian IEEE Transactions on Pattern Analysis Sun, Machine Intelligence, Faster R-CNN: Towards real-time object detection with region proposal networks, 39 (2015) 1137–1149.
[13] Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, Alexander C. Berg, Ssd: Single shot multibox detector, in: Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, the Netherlands, October 11–14, 2016, Proceedings, Part I 14, Springer, 2016, pp. 21–37.
[14] Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi, You only look once: Unified, real-time object detection, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 779–788.
[15] Joseph Redmon, Ali Farhadi, YOLOv3: An incremental improvement, 2018, arXiv preprint arXiv:1804.02767.
[16] Glenn Jocher, Ultralytics YOLOv5, 2020, http://dx.doi.org/10.5281/zenodo.3908559, URL https://github.com/ultralytics/yolov5.
[17] Glenn Jocher, Ayush Chaurasia, Jing Qiu, Ultralytics YOLOv8, 2023, URL https://github.com/ultralytics/ultralytics.
[18] Chengjian Feng, Yujie Zhong, Yu Gao, Matthew R. Scott, Weilin Huang, Tood: Task-aligned one-stage object detection, in: 2021 IEEE/CVF International Conference on Computer Vision, ICCV, IEEE Computer Society, ISBN: 1665428120, pp. 3490–3499.
[19] Yu He, Kechen Song, Qinggang Meng, Yunhui Yan, An end-to-end steel surface defect detection approach via fusing multiple hierarchical features, (ISSN: 0018-9456) 69 (4) (2019) 1493–1504.
[20] Ruiyang Hao, Bingyu Lu, Ying Cheng, Xiu Li, Biqing Huang, A steel surface defect inspection approach towards smart industrial monitoring, (ISSN: 0956-5515) 32 (2021) 1833–1843.
[21] Jianbo Yu, Xun Cheng, Qingfeng Li, Surface defect detection of steel strips based on anchor-free network with channel attention and bidirectional feature fusion, (ISSN: 0018-9456) 71 (2021) 1–10.
[22] Rushuai Tian, Minping Jia, DCC-CenterNet: A rapid detection method for steel surface defects, (ISSN: 0263-2241) 187 (2022) 110211.
[23] W. Wang, C. Mi, Z. Wu, K. Lu, H. Long, B. Pan, D. Li, J. Zhang, P. Chen, B. Wang, A real-time steel surface defect detection approach with high accuracy, IEEE Trans. Instrum. Meas. (ISSN: 1557-9662) 71 (2022) 1–10, http://dx.doi.org/10.1109/TIM.2021.3127648.
[24] Shaoxiong Li, Fanning Kong, Ruoqi Wang, Tao Luo, Zaifeng Shi, EFD-YOLOv4: A steel surface defect detection network with encoder-decoder residual block and feature alignment module, (ISSN: 0263-2241) 220 (2023) 113359.
[25] Rongqiang Liu, Min Huang, Zheming Gao, Zhenyuan Cao, Peng Cao, MSC-dnet: An efficient detector with multi-scale context for defect detection on strip steel surface, (ISSN: 0263-2241) 209 (2023) 112467.
[26] Haitao Xin, Kai Zhang, Surface defect detection with channel-spatial attention modules and bi-directional feature pyramid, (ISSN: 2169-3536) 2023.
[27] Shu Liu, Lu Qi, Haifang Qin, Jianping Shi, Jiaya Jia, Path aggregation network for instance segmentation, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 8759–8768.
[28] Chien-Yao Wang, Alexey Bochkovskiy, Hong-Yuan Mark Liao, YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 7464–7475.
[29] Xizhou Zhu, Han Hu, Stephen Lin, Jifeng Dai, Deformable convnets v2: More deformable, better results, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9308–9316.
[30] Zhora Gevorgyan, SIoU loss: More powerful learning for bounding box regression, 2022.
[31] Yian Zhao, Wenyu Lv, Shangliang Xu, Jinman Wei, Guanzhong Wang, Qingqing Dang, Yi Liu, Jie Chen, Detrs beat yolos on real-time object detection, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 16965–16974.
[32] Kai Han, Yunhe Wang, Qi Tian, Jianyuan Guo, Chunjing Xu, Chang Xu, Ghostnet: More features from cheap operations, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 1580–1589.
[33] Qibin Hou, Daquan Zhou, Jiashi Feng, Coordinate attention for efficient mobile network design, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 13713–13722.
[34] Xiaoming Lv, Fajie Duan, Jia-jia Jiang, Xiao Fu, Lin Gan, Deep metallic surface defect detection: The new benchmark and detection network, Sensors 20 (6) (2020) 1562.
[35] Zhaohui Zheng, Ping Wang, Dongwei Ren, Wei Liu, Rongguang Ye, Qinghua Hu, Wangmeng Zuo, Enhancing geometric factors in model learning and inference for object detection and instance segmentation, (ISSN: 2168-2267) 52 (8) (2021) 8574–8586, cybernetics.
[36] Zhaohui Zheng, Ping Wang, Wei Liu, Jinze Li, Rongguang Ye, Dongwei Ren, Distance-iou loss: Faster and better learning for bounding box regression, in: Proceedings of the AAAI Conference on Artificial Intelligence, 34, ISBN: 2374-3468, pp. 12993–13000.
[37] Hamid Rezatofighi, Nathan Tsoi, JunYoung Gwak, Amir Sadeghian, Ian Reid, Silvio Savarese, Generalized intersection over union: A metric and a loss for bounding box regression, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 658–666.
[38] Yi-Fan Zhang, Weiqiang Ren, Zhang Zhang, Zhen Jia, Liang Wang, Tieniu Tan, Focal and efficient IOU loss for accurate bounding box regression, Neurocomputing 506 (2022) 146–157.
[39] Jie Hu, Li Shen, Gang Sun, Squeeze-and-excitation networks, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 7132–7141.
[40] Sanghyun Woo, Jongchan Park, Joon-Young Lee, In So Kweon, Cbam: Convolutional block attention module, in: Proceedings of the European Conference on Computer Vision, ECCV, 2018, pp. 3–19.
[41] Chien-Yao Wang, I-Hau Yeh, Hong-Yuan Mark Liao, Yolov9: Learning what you want to learn using programmable gradient information, in: European Conference on Computer Vision, Springer, 2025, pp. 1–21.
[42] Ao Wang, Hui Chen, Lihao Liu, Kai Chen, Zijia Lin, Jungong Han, Guiguang Ding, Yolov10: Real-time end-to-end object detection, 2024, arXiv preprint arXiv:2405.14458.
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...




