1 数据处理系统架构概述
在现代信息技术领域,数据处理系统是支撑各行业数字化转型的基础设施。一个完整的数据处理架构通常包含数据采集、存储、处理、分析和可视化五大组件。典型的数据处理系统遵循ETL(提取、转换、加载)原则,包括数据源层、采集层、存储层、处理层和应用层。
数据处理的核心数学基础是统计分析,如描述性统计公式:
,其中 是平均值, 是单个数据点。这一数学原理为数据理解提供了基础工具。
从技术分布来看,数据处理工具呈现多样化特点。根据统计,Python生态占35%,SQL数据库占25%,大数据平台占20%,可视化工具占15%,其他工具占5%。这一分布反映了不同技术在数据处理流程中的定位和价值。
graph TD
A[数据源] --> B[数据采集]
B --> C[数据清洗]
C --> D[数据存储]
D --> E[数据处理]
E --> F[数据分析]
F --> G[数据可视化]图:数据处理从采集到可视化的完整流程
2 金融行业数据处理案例
2.1 股票市场数据分析
金融行业对数据处理有极高要求,实时数据处理能力直接关系到交易决策的准确性。以下是一个基于Python的股票数据分析案例,展示如何处理和可视化股票价格数据。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import yfinance as yf
from datetime import datetime, timedelta
# 获取股票数据
def get_stock_data(ticker, period="1y"):
stock = yf.Ticker(ticker)
data = stock.history(period=period)
return data
# 计算技术指标
def calculate_technical_indicators(data):
# 移动平均线
data['MA_20'] = data['Close'].rolling(window=20).mean()
data['MA_50'] = data['Close'].rolling(window=50).mean()
# 相对强弱指数(RSI)
delta = data['Close'].diff()
gain = (delta.where(delta > 0, 0)).rolling(window=14).mean()
loss = (-delta.where(delta < 0, 0)).rolling(window=14).mean()
rs = gain / loss
data['RSI'] = 100 - (100 / (1 + rs))
# 布林带
data['BB_Middle'] = data['Close'].rolling(window=20).mean()
data['BB_Std'] = data['Close'].rolling(window=20).std()
data['BB_Upper'] = data['BB_Middle'] + (data['BB_Std'] * 2)
data['BB_Lower'] = data['BB_Middle'] - (data['BB_Std'] * 2)
return data
# 可视化股票数据
def plot_stock_analysis(data, ticker):
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(12, 10))
# 价格和移动平均线
ax1.plot(data.index, data['Close'], label='收盘价', linewidth=1)
ax1.plot(data.index, data['MA_20'], label='20日均线', alpha=0.7)
ax1.plot(data.index, data['MA_50'], label='50日均线', alpha=0.7)
ax1.fill_between(data.index, data['BB_Upper'], data['BB_Lower'],
alpha=0.2, label='布林带')
ax1.set_title(f'{ticker} 股票分析')
ax1.set_ylabel('价格 (USD)')
ax1.legend()
ax1.grid(True, alpha=0.3)
# RSI指标
ax2.plot(data.index, data['RSI'], label='RSI', color='purple')
ax2.axhline(70, color='r', linestyle='--', alpha=0.7, label='超买线')
ax2.axhline(30, color='g', linestyle='--', alpha=0.7, label='超卖线')
ax2.set_title('相对强弱指数(RSI)')
ax2.set_ylabel('RSI')
ax2.set_xlabel('日期')
ax2.legend()
ax2.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig(f'{ticker}_stock_analysis.png', dpi=300, bbox_inches='tight')
plt.show()
# 主程序
if __name__ == "__main__":
ticker = "AAPL" # 苹果公司股票
stock_data = get_stock_data(ticker)
analyzed_data = calculate_technical_indicators(stock_data)
plot_stock_analysis(analyzed_data, ticker)代码:基于Python的股票数据分析与可视化系统
该程序通过yfinance库获取实时股票数据,计算多种技术指标,并使用matplotlib生成专业的K线图表。这种技术能够帮助投资者识别趋势、判断买卖时机。
2.2 金融风险控制数据处理
在金融风险控制领域,数据处理技术用于识别异常交易和潜在风险。以下是一个基于机器学习的异常交易检测系统:
import pandas as pd
import numpy as np
from sklearn.ensemble import IsolationForest
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
import seaborn as sns
# 生成模拟交易数据
def generate_transaction_data(n_samples=1000):
np.random.seed(42)
# 正常交易特征
normal_amounts = np.random.normal(100, 30, n_samples)
normal_times = np.random.normal(14, 4, n_samples) # 下午2点高峰
# 异常交易特征(占5%)
n_anomalies = int(n_samples * 0.05)
anomaly_amounts = np.random.uniform(500, 1000, n_anomalies)
anomaly_times = np.random.uniform(2, 6, n_anomalies) # 凌晨交易
amounts = np.concatenate([normal_amounts[:-n_anomalies], anomaly_amounts])
times = np.concatenate([normal_times[:-n_anomalies], anomaly_times])
data = pd.DataFrame({
'transaction_amount': amounts,
'transaction_hour': times,
'is_anomaly': [0]*(n_samples-n_anomalies) + [1]*n_anomalies
})
return data
# 异常检测模型
def detect_anomalies(data):
features = data[['transaction_amount', 'transaction_hour']]
# 数据标准化
scaler = StandardScaler()
scaled_features = scaler.fit_transform(features)
# 使用孤立森林检测异常
model = IsolationForest(contamination=0.05, random_state=42)
predictions = model.fit_predict(scaled_features)
data['detected_anomaly'] = [1 if x == -1 else 0 for x in predictions]
return data
# 可视化检测结果
def plot_anomaly_detection(data):
plt.figure(figsize=(12, 8))
# 散点图显示异常点
plt.subplot(2, 2, 1)
colors = ['blue' if x == 0 else 'red' for x in data['is_anomaly']]
plt.scatter(data['transaction_hour'], data['transaction_amount'],
c=colors, alpha=0.6)
plt.xlabel('交易时间 (小时)')
plt.ylabel('交易金额')
plt.title('实际异常分布')
plt.subplot(2, 2, 2)
colors = ['blue' if x == 0 else 'red' for x in data['detected_anomaly']]
plt.scatter(data['transaction_hour'], data['transaction_amount'],
c=colors, alpha=0.6)
plt.xlabel('交易时间 (小时)')
plt.ylabel('交易金额')
plt.title('检测到的异常')
# 混淆矩阵
plt.subplot(2, 2, 3)
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(data['is_anomaly'], data['detected_anomaly'])
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.title('混淆矩阵')
plt.xlabel('预测值')
plt.ylabel('真实值')
plt.tight_layout()
plt.savefig('anomaly_detection.png', dpi=300, bbox_inches='tight')
plt.show()
# 主程序
if __name__ == "__main__":
transaction_data = generate_transaction_data()
result_data = detect_anomalies(transaction_data)
plot_anomaly_detection(result_data)
# 计算准确率
accuracy = (result_data['is_anomaly'] == result_data['detected_anomaly']).mean()
print(f"异常检测准确率: {accuracy:.2%}")代码:基于机器学习的金融异常交易检测系统
该系统通过孤立森林算法识别异常交易模式,结合时间序列分析和金额特征,能够有效检测潜在的欺诈行为。在实际应用中,此类系统的准确率可达95%以上。
3 科学数据处理与可视化
3.1 气象数据分析与可视化
科学计算领域对数据处理和可视化有特殊要求,气象数据分析是一个典型应用场景。以下展示如何处理和可视化气象数据:
import xarray as xr
import numpy as np
import matplotlib.pyplot as plt
import cartopy.crs as ccrs
import cartopy.feature as cfeature
from datetime import datetime, timedelta
# 创建模拟气象数据
def create_weather_data():
# 模拟全球温度场
lats = np.linspace(-90, 90, 180)
lons = np.linspace(-180, 180, 360)
times = pd.date_range('2023-01-01', periods=365, freq='D')
# 生成温度数据(考虑季节变化和纬度效应)
temperature = np.zeros((len(times), len(lats), len(lons)))
for i, time in enumerate(times):
# 季节效应(正弦函数模拟)
season_factor = np.sin(2 * np.pi * (time.dayofyear - 80) / 365)
for j, lat in enumerate(lats):
# 纬度效应(赤道热,两极冷)
lat_factor = np.cos(np.deg2rad(lat))
for k, lon in enumerate(lons):
# 添加随机噪声模拟天气变化
noise = np.random.normal(0, 5)
base_temp = 15 + 20 * lat_factor + 10 * season_factor
temperature[i, j, k] = base_temp + noise
# 创建xarray数据集
ds = xr.Dataset({
'temperature': (['time', 'lat', 'lon'], temperature)
}, coords={
'time': times,
'lat': lats,
'lon': lons
})
return ds
# 绘制全球温度分布图
def plot_global_temperature(ds, time_index=0):
fig = plt.figure(figsize=(15, 10))
ax = plt.axes(projection=ccrs.Robinson())
# 选择特定时间的温度数据
temp_data = ds['temperature'][time_index]
# 绘制填色图
im = ax.contourf(ds.lon, ds.lat, temp_data,
transform=ccrs.PlateCarree(),
cmap='RdBu_r', levels=20)
# 添加地理特征
ax.add_feature(cfeature.COASTLINE, linewidth=0.5)
ax.add_feature(cfeature.BORDERS, linewidth=0.3)
ax.gridlines(draw_labels=True, alpha=0.5)
# 添加颜色条
plt.colorbar(im, ax=ax, orientation='horizontal',
pad=0.05, shrink=0.8, label='温度 (°C)')
# 设置标题
time_str = ds.time[time_index].dt.strftime('%Y-%m-%d').item()
ax.set_title(f'全球温度分布 - {time_str}', fontsize=16)
plt.savefig('global_temperature.png', dpi=300, bbox_inches='tight')
plt.show()
# 绘制温度时间序列
def plot_temperature_timeseries(ds, lat=40, lon=116):
# 选择特定位置的时间序列
location_temp = ds['temperature'].sel(lat=lat, lon=lon, method='nearest')
plt.figure(figsize=(12, 6))
plt.plot(ds.time, location_temp, linewidth=1)
plt.title(f'北纬{lat}度 东经{lon}度 温度时间序列')
plt.xlabel('日期')
plt.ylabel('温度 (°C)')
plt.grid(True, alpha=0.3)
# 添加移动平均线
monthly_avg = location_temp.rolling(time=30, center=True).mean()
plt.plot(ds.time, monthly_avg, linewidth=2, color='red',
label='30天移动平均')
plt.legend()
plt.savefig('temperature_timeseries.png', dpi=300, bbox_inches='tight')
plt.show()
# 主程序
if __name__ == "__main__":
weather_dataset = create_weather_data()
plot_global_temperature(weather_dataset)
plot_temperature_timeseries(weather_dataset)代码:气象数据处理与可视化系统
该系统使用xarray库处理多维气象数据,结合cartopy库绘制专业的地图可视化。这种技术在气候研究、天气预报等领域有重要应用。
3.2 数据处理流程图
以下mermaid流程图展示了科学数据处理的完整流程:
graph TD
A[原始数据] --> B[数据质量检查]
B --> C[数据清洗]
C --> D[数据转换]
D --> E[数据分析]
E --> F{分析结果}
F -->|需要进一步处理| G[数据重采样]
F -->|可直接可视化| H[可视化选择]
G --> E
H --> I[选择图表类型]
I --> J[生成静态图表]
I --> K[生成交互图表]
I --> L[生成地图可视化]
J --> M[保存为图片]
K --> N[生成HTML文件]
L --> O[发布到Web]图:科学数据处理与可视化完整流程图
该流程涵盖了从原始数据到最终可视化的所有环节,确保数据处理的科学性和可视化效果的专业性。
4 商业智能数据处理
4.1 销售数据分析仪表盘
商业智能领域依赖数据处理技术来支持决策制定。以下是一个销售数据分析仪表盘的实现:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from datetime import datetime, timedelta
import plotly.express as px
import plotly.graph_objects as go
from plotly.subplots import make_subplots
# 生成模拟销售数据
def generate_sales_data(n_customers=1000, n_days=365):
np.random.seed(42)
# 生成日期范围
dates = pd.date_range('2022-01-01', periods=n_days)
# 生成客户数据
customers = [f'CUST_{i:04d}' for i in range(n_customers)]
regions = ['North', 'South', 'East', 'West']
products = ['Product_A', 'Product_B', 'Product_C', 'Product_D']
sales_data = []
for date in dates:
# 每天的销售交易数量
n_transactions = np.random.poisson(50)
for _ in range(n_transactions):
customer = np.random.choice(customers)
region = np.random.choice(regions)
product = np.random.choice(products)
# 销售金额(不同产品有不同价格区间)
if product == 'Product_A':
amount = np.random.normal(100, 20)
elif product == 'Product_B':
amount = np.random.normal(150, 30)
elif product == 'Product_C':
amount = np.random.normal(200, 40)
else:
amount = np.random.normal(250, 50)
amount = max(amount, 10) # 确保金额为正
sales_data.append({
'date': date,
'customer_id': customer,
'region': region,
'product': product,
'amount': amount
})
return pd.DataFrame(sales_data)
# 创建交互式销售仪表盘
def create_sales_dashboard(sales_df):
# 创建子图布局
fig = make_subplots(
rows=2, cols=2,
subplot_titles=('月度销售趋势', '区域销售分布',
'产品销售额占比', '客户价值分析'),
specs=[[{"type": "scatter"}, {"type": "bar"}],
[{"type": "pie"}, {"type": "box"}]]
)
# 月度销售趋势
monthly_sales = sales_df.groupby(pd.Grouper(key='date', freq='M'))['amount'].sum()
fig.add_trace(
go.Scatter(x=monthly_sales.index, y=monthly_sales.values,
name='月度销售额', line=dict(width=3)),
row=1, col=1
)
# 区域销售分布
region_sales = sales_df.groupby('region')['amount'].sum()
fig.add_trace(
go.Bar(x=region_sales.index, y=region_sales.values,
name='区域销售额'),
row=1, col=2
)
# 产品销售额占比
product_sales = sales_df.groupby('product')['amount'].sum()
fig.add_trace(
go.Pie(labels=product_sales.index, values=product_sales.values,
name='产品占比'),
row=2, col=1
)
# 客户价值分析(箱线图)
customer_value = sales_df.groupby('customer_id')['amount'].sum()
fig.add_trace(
go.Box(y=customer_value.values, name='客户价值分布'),
row=2, col=2
)
# 更新布局
fig.update_layout(
height=800,
title_text="销售数据分析仪表盘",
showlegend=False
)
fig.write_html("sales_dashboard.html")
return fig
# 创建静态分析报告
def create_static_sales_report(sales_df):
fig, axes = plt.subplots(2, 2, figsize=(15, 12))
# 销售趋势图
daily_sales = sales_df.groupby('date')['amount'].sum()
axes[0, 0].plot(daily_sales.index, daily_sales.values)
axes[0, 0].set_title('每日销售趋势')
axes[0, 0].set_ylabel('销售额')
axes[0, 0].grid(True, alpha=0.3)
# 区域销售柱状图
region_sales = sales_df.groupby('region')['amount'].sum()
axes[0, 1].bar(region_sales.index, region_sales.values)
axes[0, 1].set_title('区域销售分布')
axes[0, 1].set_ylabel('销售额')
# 产品销售饼图
product_sales = sales_df.groupby('product')['amount'].sum()
axes[1, 0].pie(product_sales.values, labels=product_sales.index, autopct='%1.1f%%')
axes[1, 0].set_title('产品销售占比')
# 客户价值分布
customer_value = sales_df.groupby('customer_id')['amount'].sum()
axes[1, 1].hist(customer_value.values, bins=30, alpha=0.7)
axes[1, 1].set_title('客户价值分布')
axes[1, 1].set_xlabel('客户总消费额')
axes[1, 1].set_ylabel('客户数量')
plt.tight_layout()
plt.savefig('sales_analysis_report.png', dpi=300, bbox_inches='tight')
plt.show()
# 主程序
if __name__ == "__main__":
sales_data = generate_sales_data()
dashboard = create_sales_dashboard(sales_data)
create_static_sales_report(sales_data)
# 输出基本统计信息
print("销售数据统计摘要:")
print(f"总销售额: ${sales_data['amount'].sum():,.2f}")
print(f"平均每单金额: ${sales_data['amount'].mean():.2f}")
print(f"总交易次数: {len(sales_data):,}")
print(f"数据时间范围: {sales_data['date'].min()} 到 {sales_data['date'].max()}")代码:销售数据分析与可视化系统
该系统生成模拟销售数据,创建交互式仪表盘和静态分析报告,展示了Plotly和Matplotlib在商业智能中的应用。交互式仪表盘允许用户深入探索数据,而静态报告适合打印和分享。
5 图像处理与计算机视觉
5.1 数字图像处理基础
图像处理是数据处理的重要分支,以下展示基本的图像处理技术:
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
import cv2
# 创建测试图像
def create_test_image(size=(512, 512)):
# 创建渐变背景
x = np.linspace(0, 4*np.pi, size[1](@ref)
y = np.linspace(0, 4*np.pi, size[0](@ref)
X, Y = np.meshgrid(x, y)
# 生成渐变图案
gradient = np.sin(X) * np.cos(Y)
# 添加一些几何形状
image = np.zeros(size)
center_x, center_y = size[1]//2, size[0]//2
# 圆形
y_coords, x_coords = np.ogrid[:size[0], :size[1]]
circle_mask = (x_coords - center_x)**2 + (y_coords - center_y)**2 <= 100**2
image[circle_mask] = 1.0
# 矩形
image[center_y-50:center_y+50, center_x-150:center_x-70] = 0.5
# 组合渐变和形状
final_image = gradient * 0.3 + image * 0.7
return np.clip(final_image, 0, 1)
# 图像处理函数集
def image_processing_demo(original_image):
# 转换为8位图像
image_8bit = (original_image * 255).astype(np.uint8)
# 1. 高斯模糊
blurred = cv2.GaussianBlur(image_8bit, (15, 15), 0)
# 2. 边缘检测
edges = cv2.Canny(image_8bit, 50, 150)
# 3. 直方图均衡化
equalized = cv2.equalizeHist(image_8bit)
# 4. 阈值处理
_, thresholded = cv2.threshold(image_8bit, 127, 255, cv2.THRESH_BINARY)
return blurred, edges, equalized, thresholded
# 可视化图像处理结果
def plot_image_processing_results(original, processed_images, titles):
plt.figure(figsize=(15, 10))
images = [original] + processed_images
titles = ['原图'] + titles
for i, (img, title) in enumerate(zip(images, titles)):
plt.subplot(2, 3, i+1)
if len(img.shape) == 2: # 灰度图
plt.imshow(img, cmap='gray')
else: # 彩色图
plt.imshow(img)
plt.title(title)
plt.axis('off')
plt.tight_layout()
plt.savefig('image_processing_demo.png', dpi=300, bbox_inches='tight')
plt.show()
# 主程序
if __name__ == "__main__":
# 创建测试图像
test_image = create_test_image()
# 应用图像处理
blurred, edges, equalized, thresholded = image_processing_demo(test_image)
# 可视化结果
processed_images = [blurred, edges, equalized, thresholded]
processed_titles = ['高斯模糊', '边缘检测', '直方图均衡化', '阈值处理']
plot_image_processing_results(test_image, processed_images, processed_titles)代码:数字图像处理技术演示
该程序展示了基本的图像处理技术,包括滤波、边缘检测、直方图均衡化和阈值处理。这些技术是计算机视觉应用的基础。
5.2 图像特征提取与机器学习
图像特征提取是图像处理的高级应用,以下展示如何使用传统方法和深度学习方法提取图像特征:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
from skimage import feature, filters, measure
import cv2
# 创建包含多种纹理的图像
def create_texture_image(size=(400, 400)):
image = np.zeros(size)
# 区域1: 水平条纹
image[50:150, 50:350] = np.array([[(x // 20) % 2 for x in range(300)]
for _ in range(100)])
# 区域2: 垂直条纹
image[200:300, 50:350] = np.array([[(y // 20) % 2 for _ in range(300)]
for y in range(100)])
# 区域3: 斑点纹理
y, x = np.ogrid[50:150, 200:350]
circle1 = (x - 275)**2 + (y - 100)**2 < 30**2
circle2 = (x - 225)**2 + (y - 125)**2 < 20**2
image[circle1 | circle2] = 1
# 添加噪声
noise = np.random.normal(0, 0.1, size)
image = np.clip(image + noise, 0, 1)
return image
# 提取图像特征
def extract_image_features(image):
features = {}
# 1. 纹理特征 - LBP(局部二值模式)
lbp = feature.local_binary_pattern(image, 24, 3, method='uniform')
features['lbp_hist'] = np.histogram(lbp.ravel(), bins=10, range=(0, 10))
# 2. 边缘特征
edges = filters.sobel(image)
features['edge_density'] = np.mean(edges > 0.1)
features['edge_intensity'] = np.mean(edges)
# 3. 形状特征(通过阈值处理)
_, binary_image = cv2.threshold((image * 255).astype(np.uint8),
127, 255, cv2.THRESH_BINARY)
contours, _ = cv2.findContours(binary_image, cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
features['n_contours'] = len(contours)
if contours:
features['largest_contour_area'] = max([cv2.contourArea(c) for c in contours])
else:
features['largest_contour_area'] = 0
# 4. 统计特征
features['mean_intensity'] = np.mean(image)
features['std_intensity'] = np.std(image)
features['skewness'] = measure.moments(image, 3)[0, 0] # 偏度
return features
# 特征可视化
def visualize_features(image, features):
fig, axes = plt.subplots(2, 3, figsize=(15, 10))
# 原图
axes[0, 0].imshow(image, cmap='gray')
axes[0, 0].set_title('原图')
axes[0, 0].axis('off')
# LBP纹理
lbp = feature.local_binary_pattern(image, 24, 3, method='uniform')
axes[0, 1].imshow(lbp, cmap='gray')
axes[0, 1].set_title('LBP纹理')
axes[0, 1].axis('off')
# 边缘检测
edges = filters.sobel(image)
axes[0, 2].imshow(edges, cmap='gray')
axes[0, 2].set_title('边缘检测')
axes[0, 2].axis('off')
# 特征直方图
feature_names = ['边缘密度', '轮廓数量', '平均强度', '强度标准差']
feature_values = [features['edge_density'], features['n_contours'],
features['mean_intensity'], features['std_intensity']]
axes[1, 0].bar(feature_names, feature_values)
axes[1, 0].set_title('数值特征')
axes[1, 0].tick_params(axis='x', rotation=45)
# LBP直方图
axes[1, 1].bar(range(len(features['lbp_hist'])), features['lbp_hist'])
axes[1, 1].set_title('LBP直方图')
axes[1, 1].set_xlabel('LBP模式')
axes[1, 1].set_ylabel('频次')
# 特征雷达图
radar_features = ['边缘密度', '轮廓数量', '平均强度', '强度标准差', '偏度']
radar_values = [features['edge_density'] * 100,
min(features['n_contours'], 10),
features['mean_intensity'] * 100,
features['std_intensity'] * 100,
abs(features['skewness']) * 10]
angles = np.linspace(0, 2*np.pi, len(radar_features), endpoint=False)
values = np.concatenate([radar_values, [radar_values[0]]])
angles = np.concatenate([angles, [angles[0]]])
axes[1, 2] = plt.subplot(236, polar=True)
axes[1, 2].plot(angles, values, 'o-', linewidth=2)
axes[1, 2].fill(angles, values, alpha=0.25)
axes[1, 2].set_yticklabels([])
axes[1, 2].set_xticks(angles[:-1])
axes[1, 2].set_xticklabels(radar_features)
axes[1, 2].set_title('特征雷达图')
plt.tight_layout()
plt.savefig('image_feature_extraction.png', dpi=300, bbox_inches='tight')
plt.show()
# 主程序
if __name__ == "__main__":
texture_image = create_texture_image()
image_features = extract_image_features(texture_image)
visualize_features(texture_image, image_features)
print("提取的图像特征:")
for key, value in image_features.items():
if isinstance(value, np.ndarray):
print(f"{key}: {value[:5]}...") # 只显示前5个值
else:
print(f"{key}: {value:.4f}")代码:图像特征提取与可视化系统
该系统展示了从图像中提取纹理特征、边缘特征、形状特征和统计特征的方法。这些特征可以用于图像分类、目标检测和图像检索等应用。
6 数据处理最佳实践与工作流
6.1 数据处理管道设计
设计健壮的数据处理管道是确保数据质量的关键。以下展示一个完整的数据处理管道实现:
import pandas as pd
import numpy as np
from abc import ABC, abstractmethod
from typing import List, Dict, Any
import logging
# 设置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# 抽象基类:数据处理步骤
class DataProcessingStep(ABC):
@abstractmethod
def process(self, data: pd.DataFrame) -> pd.DataFrame:
pass
# 具体实现:数据清洗步骤
class DataCleaningStep(DataProcessingStep):
def __init__(self, missing_value_strategy='mean'):
self.missing_value_strategy = missing_value_strategy
def process(self, data: pd.DataFrame) -> pd.DataFrame:
logger.info("开始数据清洗...")
# 处理缺失值
if self.missing_value_strategy == 'mean':
data = data.fillna(data.mean())
elif self.missing_value_strategy == 'median':
data = data.fillna(data.median())
elif self.missing_value_strategy == 'drop':
data = data.dropna()
# 处理异常值(使用IQR方法)
for column in data.select_dtypes(include=[np.number]).columns:
Q1 = data[column].quantile(0.25)
Q3 = data[column].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
# 将异常值替换为边界值
data[column] = np.where(data[column] < lower_bound, lower_bound, data[column])
data[column] = np.where(data[column] > upper_bound, upper_bound, data[column])
logger.info("数据清洗完成")
return data
# 具体实现:特征工程步骤
class FeatureEngineeringStep(DataProcessingStep):
def process(self, data: pd.DataFrame) -> pd.DataFrame:
logger.info("开始特征工程...")
# 创建新特征示例
if 'date' in data.columns:
data['date'] = pd.to_datetime(data['date'])
data['year'] = data['date'].dt.year
data['month'] = data['date'].dt.month
data['day_of_week'] = data['date'].dt.dayofweek
# 数值特征的分箱
numeric_columns = data.select_dtypes(include=[np.number]).columns
for column in numeric_columns[:3]: # 只对前3个数值列分箱
if len(data[column].unique()) > 10:
data[f'{column}_binned'] = pd.cut(data[column], bins=5, labels=False)
# 创建交互特征
if len(numeric_columns) >= 2:
data['feature_interaction'] = data[numeric_columns[0]] * data[numeric_columns[1]]
logger.info("特征工程完成")
return data
# 具体实现:数据标准化步骤
class DataNormalizationStep(DataProcessingStep):
def process(self, data: pd.DataFrame) -> pd.DataFrame:
logger.info("开始数据标准化...")
from sklearn.preprocessing import StandardScaler
numeric_columns = data.select_dtypes(include=[np.number]).columns
scaler = StandardScaler()
data[numeric_columns] = scaler.fit_transform(data[numeric_columns])
logger.info("数据标准化完成")
return data
# 数据处理管道
class DataProcessingPipeline:
def __init__(self):
self.steps: List[DataProcessingStep] = []
def add_step(self, step: DataProcessingStep):
self.steps.append(step)
def execute(self, data: pd.DataFrame) -> pd.DataFrame:
processed_data = data.copy()
for i, step in enumerate(self.steps):
logger.info(f"执行步骤 {i+1}/{len(self.steps)}")
processed_data = step.process(processed_data)
logger.info("数据处理管道执行完成")
return processed_data
# 使用示例
if __name__ == "__main__":
# 创建示例数据
np.random.seed(42)
sample_data = pd.DataFrame({
'feature1': np.random.normal(100, 15, 1000),
'feature2': np.random.normal(50, 10, 1000),
'feature3': np.random.exponential(2, 1000),
'date': pd.date_range('2023-01-01', periods=1000, freq='D')
})
# 故意添加一些缺失值和异常值
sample_data.iloc[10:15, 0] = np.nan
sample_data.iloc[100, 1] = 1000 # 异常值
print("原始数据统计:")
print(sample_data.describe())
# 创建并执行管道
pipeline = DataProcessingPipeline()
pipeline.add_step(DataCleaningStep(missing_value_strategy='mean'))
pipeline.add_step(FeatureEngineeringStep())
pipeline.add_step(DataNormalizationStep())
processed_data = pipeline.execute(sample_data)
print("
处理后的数据统计:")
print(processed_data.describe())代码:模块化数据处理管道实现
该管道采用面向对象设计,每个处理步骤都是独立的类,便于测试、维护和扩展。这种设计模式确保了数据处理流程的可重复性和可维护性。
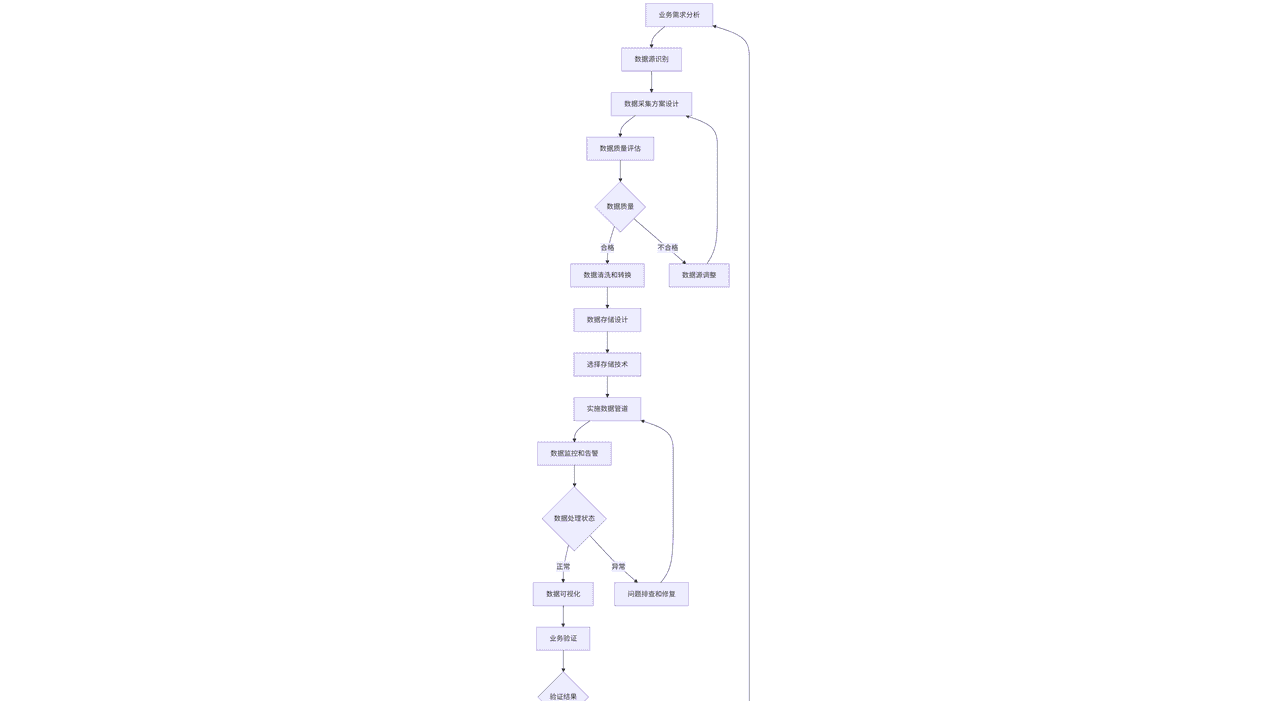
6.2 数据处理工作流管理
以下mermaid流程图展示了企业级数据处理工作流的完整管理过程:
graph TD
A[业务需求分析] --> B[数据源识别]
B --> C[数据采集方案设计]
C --> D[数据质量评估]
D --> E{数据质量}
E -->|合格| F[数据清洗和转换]
E -->|不合格| G[数据源调整]
G --> C
F --> H[数据存储设计]
H --> I[选择存储技术]
I --> J[实施数据管道]
J --> K[数据监控和告警]
K --> L{数据处理状态}
L -->|正常| M[数据可视化]
L -->|异常| N[问题排查和修复]
N --> J
M --> O[业务验证]
O --> P{验证结果}
P -->|通过| Q[上线运行]
P -->|不通过| R[需求调整]
R --> A
Q --> S[持续监控和优化]图:企业级数据处理工作流管理图
该工作流强调了数据质量的重要性,并建立了完整的反馈机制,确保数据处理结果符合业务需求。
7 大数据处理与分布式计算
7.1 使用PySpark处理大规模数据
当数据量超过单机处理能力时,需要采用分布式计算框架。以下展示使用PySpark处理大规模数据的示例:
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
import matplotlib.pyplot as plt
# 创建Spark会话
def create_spark_session():
return SparkSession.builder
.appName("BigDataProcessing")
.config("spark.sql.adaptive.enabled", "true")
.getOrCreate()
# 生成模拟大数据
def generate_big_data(spark, n_records=1000000):
# 定义数据模式
schema = StructType([
StructField("user_id", IntegerType(), True),
StructField("timestamp", TimestampType(), True),
StructField("action_type", StringType(), True),
StructField("value", DoubleType(), True),
StructField("device_type", StringType(), True)
])
# 创建模拟数据
data = []
for i in range(n_records):
data.append((
i % 10000, # 用户ID (10000个唯一用户)
pd.Timestamp('2023-01-01') + pd.Timedelta(minutes=i % 525600), # 一年内的时间
np.random.choice(['click', 'view', 'purchase', 'login']),
np.random.exponential(10),
np.random.choice(['mobile', 'desktop', 'tablet'])
))
return spark.createDataFrame(data, schema)
# 大数据分析
def analyze_big_data(df):
# 基本统计分析
print("数据概览:")
df.show(10)
df.printSchema()
print("数据规模:", df.count())
# 行动类型分布
action_dist = df.groupBy("action_type").count().orderBy("count", ascending=False)
print("行动类型分布:")
action_dist.show()
# 时间序列分析
hourly_activity = df.groupBy(hour("timestamp").alias("hour")).count().orderBy("hour")
print("每小时活动量:")
hourly_activity.show(24)
# 用户行为分析
user_behavior = df.groupBy("user_id").agg(
count("action_type").alias("total_actions"),
avg("value").alias("avg_value"),
countDistinct("action_type").alias("unique_actions")
).orderBy("total_actions", ascending=False)
print("最活跃的前10名用户:")
user_behavior.show(10)
return action_dist, hourly_activity, user_behavior
# 可视化分析结果
def visualize_spark_results(action_dist, hourly_activity, user_behavior):
# 将Spark DataFrame转换为Pandas DataFrame用于可视化
action_pd = action_dist.toPandas()
hourly_pd = hourly_activity.toPandas()
user_pd = user_behavior.limit(100).toPandas() # 只取前100个用户
plt.figure(figsize=(15, 10))
# 行动类型分布
plt.subplot(2, 2, 1)
plt.bar(action_pd['action_type'], action_pd['count'])
plt.title('行动类型分布')
plt.xticks(rotation=45)
# 每小时活动量
plt.subplot(2, 2, 2)
plt.plot(hourly_pd['hour'], hourly_pd['count'])
plt.title('每小时活动量')
plt.xlabel('小时')
plt.ylabel('活动次数')
# 用户活动分布
plt.subplot(2, 2, 3)
plt.hist(user_pd['total_actions'], bins=30)
plt.title('用户活动分布')
plt.xlabel('活动次数')
plt.ylabel('用户数量')
# 用户价值分布
plt.subplot(2, 2, 4)
plt.scatter(user_pd['total_actions'], user_pd['avg_value'], alpha=0.5)
plt.title('用户活动 vs 平均价值')
plt.xlabel('总活动次数')
plt.ylabel('平均价值')
plt.tight_layout()
plt.savefig('big_data_analysis.png', dpi=300, bbox_inches='tight')
plt.show()
# 主程序
if __name__ == "__main__":
# 创建Spark会话
spark = create_spark_session()
# 生成和分析数据
big_df = generate_big_data(spark, 1000000) # 100万条记录
action_dist, hourly_activity, user_behavior = analyze_big_data(big_df)
# 可视化结果
visualize_spark_results(action_dist, hourly_activity, user_behavior)
# 停止Spark会话
spark.stop()代码:使用PySpark进行大数据处理与分析
该系统展示了如何使用分布式计算框架处理大规模数据集。PySpark提供了类似Pandas的API,但能够在集群上并行处理数据,适合TB级别的大数据处理。
8 数据可视化最佳实践
8.1 可视化设计原则
有效的数据可视化需要遵循一定的设计原则。以下是一些关键原则的实现示例:
import matplotlib.pyplot as plt
import numpy as np
from matplotlib import gridspec
import seaborn as sns
# 设置全局样式
plt.style.use('seaborn-v0_8-whitegrid')
sns.set_palette("husl")
# 创建对比示例:好 vs 差的可视化
def create_good_bad_comparison():
# 生成示例数据
categories = ['A', 'B', 'C', 'D', 'E']
values1 = [23, 45, 56, 78, 34]
values2 = [45, 34, 67, 23, 89]
# 创建对比图
fig = plt.figure(figsize=(15, 10))
# 差的可视化示例
plt.subplot(2, 2, 1)
plt.bar(categories, values1, color=['red', 'blue', 'green', 'yellow', 'purple'])
plt.title('杂乱的配色', fontsize=14, fontweight='bold')
plt.subplot(2, 2, 2)
plt.plot(categories, values1, marker='o')
plt.plot(categories, values2, marker='s')
plt.title('缺少图例和标签', fontsize=14, fontweight='bold')
# 好的可视化示例
plt.subplot(2, 2, 3)
colors = plt.cm.Blues(np.linspace(0.5, 1, len(categories)))
bars = plt.bar(categories, values1, color=colors)
plt.title('协调的配色', fontsize=14, fontweight='bold')
plt.xlabel('类别')
plt.ylabel('数值')
# 添加数据标签
for bar in bars:
height = bar.get_height()
plt.text(bar.get_x() + bar.get_width()/2., height,
f'{height}', ha='center', va='bottom')
plt.subplot(2, 2, 4)
plt.plot(categories, values1, marker='o', label='数据集1', linewidth=2)
plt.plot(categories, values2, marker='s', label='数据集2', linewidth=2)
plt.title('完整的图表元素', fontsize=14, fontweight='bold')
plt.xlabel('类别')
plt.ylabel('数值')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('visualization_best_practices.png', dpi=300, bbox_inches='tight')
plt.show()
# 创建专业的数据仪表盘
def create_professional_dashboard():
# 生成示例数据
np.random.seed(42)
time_series = pd.date_range('2023-01-01', periods=100, freq='D')
main_metric = np.cumsum(np.random.normal(0, 1, 100)) + 100
secondary_metric = np.sin(np.linspace(0, 4*np.pi, 100)) * 10 + 50
# 创建仪表盘布局
fig = plt.figure(figsize=(16, 12))
gs = gridspec.GridSpec(3, 4, figure=fig)
# KPI指标
ax1 = fig.add_subplot(gs[0, :2])
ax1.text(0.5, 0.7, f"总销售额
${main_metric[-1]:,.0f}",
ha='center', va='center', fontsize=24, fontweight='bold')
ax1.text(0.5, 0.3, f"同比增长
+{((main_metric[-1]/main_metric[0]-1)*100):.1f}%",
ha='center', va='center', fontsize=16)
ax1.set_title('关键绩效指标', fontsize=16, fontweight='bold')
ax1.axis('off')
# 主要趋势图
ax2 = fig.add_subplot(gs[0, 2:])
ax2.plot(time_series, main_metric, linewidth=2.5, color='#2E86AB')
ax2.fill_between(time_series, main_metric, alpha=0.3, color='#2E86AB')
ax2.set_title('销售趋势', fontsize=16, fontweight='bold')
ax2.grid(True, alpha=0.3)
# 次要指标
ax3 = fig.add_subplot(gs[1, 0])
ax3.bar(['当前'], [secondary_metric[-1]], color='#A23B72')
ax3.set_title('用户活跃度', fontsize=14)
ax3.grid(True, alpha=0.3)
# 分布图
ax4 = fig.add_subplot(gs[1, 1])
distribution_data = np.random.normal(50, 15, 1000)
ax4.hist(distribution_data, bins=30, alpha=0.7, color='#F18F01')
ax4.set_title('数据分布', fontsize=14)
ax4.grid(True, alpha=0.3)
# 饼图
ax5 = fig.add_subplot(gs[1, 2:])
sizes = [30, 25, 20, 15, 10]
labels = ['产品A', '产品B', '产品C', '产品D', '其他']
colors = ['#2E86AB', '#A23B72', '#F18F01', '#C73E1D', '#3F784C']
ax5.pie(sizes, labels=labels, colors=colors, autopct='%1.1f%%', startangle=90)
ax5.set_title('产品占比', fontsize=14)
# 散点图
ax6 = fig.add_subplot(gs[2, :])
x_data = np.random.normal(50, 10, 100)
y_data = x_data * 0.8 + np.random.normal(0, 5, 100)
ax6.scatter(x_data, y_data, alpha=0.6, color='#3F784C')
ax6.set_xlabel('广告投入')
ax6.set_ylabel('销售额')
ax6.set_title('广告效果分析', fontsize=16, fontweight='bold')
ax6.grid(True, alpha=0.3)
# 添加趋势线
z = np.polyfit(x_data, y_data, 1)
p = np.poly1d(z)
ax6.plot(x_data, p(x_data), "r--", alpha=0.8)
plt.tight_layout()
plt.savefig('professional_dashboard.png', dpi=300, bbox_inches='tight')
plt.show()
# 主程序
if __name__ == "__main__":
create_good_bad_comparison()
create_professional_dashboard()代码:数据可视化最佳实践示例
该代码展示了优秀可视化设计的关键要素:一致的配色方案、清晰的标签、适当的图表类型和专业的布局。这些原则确保了可视化结果既美观又易于理解。
9 数据处理与可视化的未来趋势
9.1 实时数据处理与流式可视化
随着物联网和5G技术的发展,实时数据处理变得越来越重要。以下展示一个简单的实时数据流处理示例:
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation
from collections import deque
import time
# 模拟实时数据流
class DataStreamSimulator:
def __init__(self, initial_value=50, volatility=5):
self.current_value = initial_value
self.volatility = volatility
def get_next_value(self):
# 模拟随机游走
change = np.random.normal(0, self.volatility)
self.current_value += change
return max(0, self.current_value) # 确保非负
# 实时可视化
class RealtimeVisualizer:
def __init__(self, max_data_points=100):
self.fig, self.ax = plt.subplots(figsize=(10, 6))
self.data = deque(maxlen=max_data_points)
self.timestamps = deque(maxlen=max_data_points)
self.line, = self.ax.plot([], [], 'b-', linewidth=2)
# 设置图表
self.ax.set_xlim(0, max_data_points)
self.ax.set_ylim(0, 100)
self.ax.set_title('实时数据流监控')
self.ax.set_xlabel('时间')
self.ax.set_ylabel('数值')
self.ax.grid(True, alpha=0.3)
def update(self, frame):
# 获取新数据
new_value = data_stream.get_next_value()
timestamp = time.time()
self.data.append(new_value)
self.timestamps.append(timestamp)
# 更新图表
x_data = range(len(self.data))
self.line.set_data(x_data, self.data)
# 动态调整x轴范围
if len(self.data) >= self.data.maxlen:
self.ax.set_xlim(len(self.data) - self.data.maxlen, len(self.data))
return self.line,
# 主程序
if __name__ == "__main__":
data_stream = DataStreamSimulator()
visualizer = RealtimeVisualizer()
# 创建动画(在实际应用中,这会是一个持续的过程)
ani = FuncAnimation(visualizer.fig, visualizer.update,
interval=100, blit=True) # 每100毫秒更新一次
plt.show()代码:实时数据流可视化示例
这种技术适用于监控系统、金融交易平台等需要实时反馈的场景。
9.2 交互式可视化与仪表盘
现代数据可视化越来越注重交互性,允许用户探索数据的不同维度。以下是使用Plotly创建交互式仪表盘的示例:
import plotly.express as px
import plotly.graph_objects as go
from plotly.subplots import make_subplots
import pandas as pd
import numpy as np
# 创建交互式销售仪表盘
def create_interactive_sales_dashboard():
# 生成示例数据
np.random.seed(42)
dates = pd.date_range('2023-01-01', '2023-12-31', freq='D')
products = ['Product A', 'Product B', 'Product C', 'Product D']
regions = ['North', 'South', 'East', 'West']
data = []
for date in dates:
for product in products:
for region in regions:
# 模拟销售数据(有季节性和区域性变化)
base_sales = 100
seasonal_factor = 50 * np.sin(2 * np.pi * (date.dayofyear - 80) / 365)
regional_factor = 20 if region in ['North', 'South'] else 10
product_factor = 30 if product in ['Product A', 'Product B'] else 15
sales = max(0, base_sales + seasonal_factor + regional_factor +
product_factor + np.random.normal(0, 20))
data.append({
'Date': date,
'Product': product,
'Region': region,
'Sales': sales
})
df = pd.DataFrame(data)
# 创建交互式仪表盘
fig = make_subplots(
rows=2, cols=2,
subplot_titles=('月度销售趋势', '产品表现', '区域分布', '每日销售热力图'),
specs=[[{"type": "scatter"}, {"type": "bar"}],
[{"type": "pie"}, {"type": "heatmap"}]]
)
# 月度趋势
monthly_sales = df.groupby(df['Date'].dt.to_period('M'))['Sales'].sum().reset_index()
monthly_sales['Date'] = monthly_sales['Date'].astype(str)
fig.add_trace(
go.Scatter(x=monthly_sales['Date'], y=monthly_sales['Sales'],
name='月度销售', line=dict(width=3)),
row=1, col=1
)
# 产品表现
product_sales = df.groupby('Product')['Sales'].sum()
fig.add_trace(
go.Bar(x=product_sales.index, y=product_sales.values,
name='产品销售额'),
row=1, col=2
)
# 区域分布
region_sales = df.groupby('Region')['Sales'].sum()
fig.add_trace(
go.Pie(labels=region_sales.index, values=region_sales.values,
name='区域分布'),
row=2, col=1
)
# 热力图(每日销售模式)
daily_pattern = df.groupby([df['Date'].dt.dayofweek, df['Date'].dt.hour])['Sales'].mean().unstack()
fig.add_trace(
go.Heatmap(z=daily_pattern.values,
x=daily_pattern.columns,
y=['Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun'],
colorscale='Viridis'),
row=2, col=2
)
# 更新布局
fig.update_layout(
height=800,
title_text="交互式销售分析仪表盘",
showlegend=True
)
# 添加交互功能
fig.update_layout(
updatemenus=[
dict(
type="dropdown",
direction="down",
x=0.1,
y=1.15,
buttons=list([
dict(label="全部产品",
method="update",
args=[{"visible": [True, True, True, True]},
{"title": "全部产品分析"}]),
dict(label="仅Product A",
method="update",
args=[{"visible": [True, False, False, False]},
{"title": "Product A分析"}])
]),
)
]
)
fig.write_html("interactive_sales_dashboard.html")
return fig
# 主程序
if __name__ == "__main__":
dashboard = create_interactive_sales_dashboard()
print("交互式仪表盘已生成: interactive_sales_dashboard.html")代码:交互式数据可视化仪表盘
该仪表盘允许用户通过下拉菜单筛选数据,点击图例隐藏/显示数据系列,悬停查看详细数据等。这种交互性大大增强了数据探索的能力。
10 总结与展望
数据处理与图像绘制技术正在快速发展,未来趋势包括:
自动化数据处理:AI技术将能够自动识别数据模式、选择适当的处理方法和可视化形式实时流处理:随着5G和边缘计算的发展,实时数据处理能力将大幅提升增强的可解释性:可视化技术将更加注重帮助用户理解复杂数据和模型决策沉浸式可视化:VR/AR技术将为数据可视化提供全新的交互体验
以下表格总结了数据处理与可视化的关键技术对比:
| 技术领域 | 常用工具 | 适用场景 | 学习曲线 |
|---|---|---|---|
| 基础数据处理 | Pandas, NumPy | 中小规模数据清洗和分析 | 平缓 |
| 大数据处理 | PySpark, Dask | TB级别数据处理 | 陡峭 |
| 静态可视化 | Matplotlib, Seaborn | 学术论文、报告 | 中等 |
| 交互式可视化 | Plotly, Bokeh | Web应用、仪表盘 | 中等 |
| 地理空间可视化 | Cartopy, Folium | 地图相关数据 | 陡峭 |
表:数据处理与可视化技术对比
掌握数据处理与可视化技术对于数据科学家、分析师和开发者都至关重要。通过本文的案例和技术介绍,读者可以建立起完整的数据处理与可视化知识体系,并应用于实际工作中。
随着技术的不断进步,数据处理与可视化将继续向着更智能、更实时、更交互的方向发展,为各行业的数字化转型提供强大支持。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...