阅读原文:ElasticSearch从入门到实战 – 梦呓
Elasticsearch简介
介绍
- 创始人:Shay Banon (谢巴农)
- Elasticsearch是一个基于Lucene的搜索服务器
- 提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口
- Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的
- 根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。

Elasticsearch可以做什么
信息检索
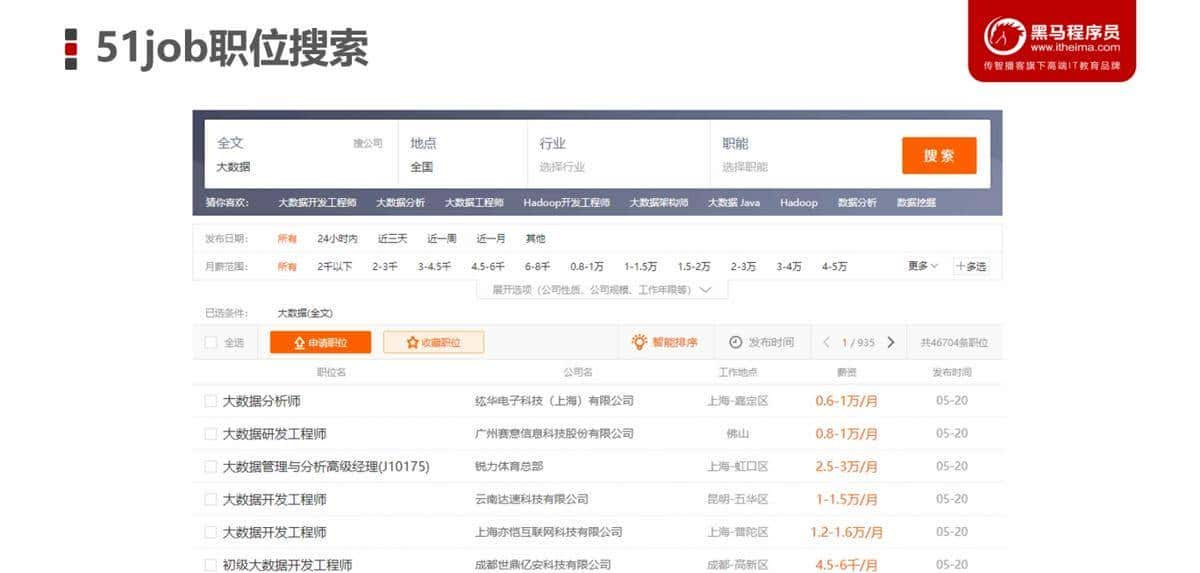
企业内部系统搜索
关系型数据库使用like进行模糊检索,会导致索引失效,效率低下
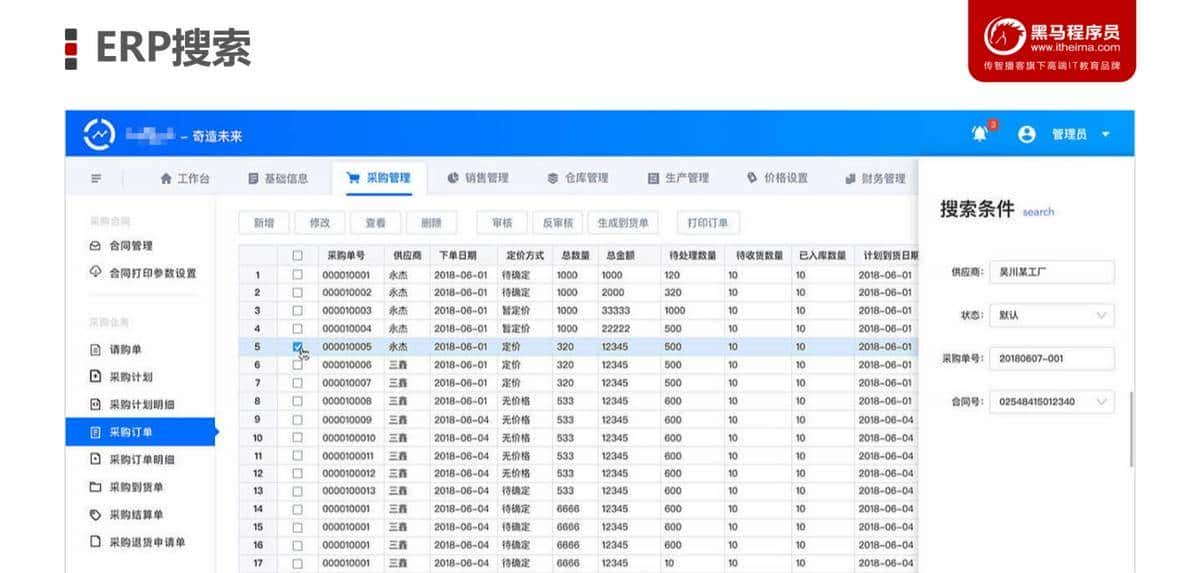
数据分析引擎
Elasticsearch 聚合可以对数十亿行日志数据进行聚合分析,探索数据的趋势和规律。
Elasticsearch特点
海量数据处理
- 大型分布式集群(数百台规模服务器)
- 处理PB级数据
- 小公司也可以进行单机部署
开箱即用
- 简单易用,操作超级简单
- 快速部署生产环境
作为传统数据库的补充
- 传统关系型数据库不擅长全文检索(MySQL自带的全文索引,与ES性能差距超级大)
- 传统关系型数据库无法支持搜索排名、海量数据存储、分析等功能
- Elasticsearch可以作为传统关系数据库的补充,提供RDBM无法提供的功能
ElasticSearch使用案例
- 2013年初,GitHub抛弃了Solr,采取ElasticSearch 来做PB级的搜索。 “GitHub使用ElasticSearch搜索20TB的数据,包括13亿文件和1300亿行代码”
- 维基百科:启动以elasticsearch为基础的核心搜索架构
- SoundCloud:“SoundCloud使用ElasticSearch为1.8亿用户提供即时而精准的音乐搜索服务”
- 百度:百度目前广泛使用ElasticSearch作为文本数据分析,采集百度所有服务器上的各类指标数据及用户自定义数据,通过对各种数据进行多维分析展示,辅助定位分析实例异常或业务层面异常。目前覆盖百度内部20多个业务线(包括casio、云分析、网盟、预测、文库、直达号、钱包、风控等),单集群最大100台机器,200个ES节点,每天导入30TB+数据
- 新浪使用ES 分析处理32亿条实时日志
- 阿里使用ES 构建挖财自己的日志采集和分析体系
ElasticSearch对比Solr
- Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能;
- Solr 支持更多格式的数据,而 Elasticsearch 仅支持json文件格式;
- Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供;
- Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elasticsearch
Lucene简介

- Lucene是一种高性能的全文检索库,在2000年开源,最初由大名鼎鼎的Doug Cutting(道格·卡丁)开发
- Lucene是Apache的一个顶级开源项目,是一个全文检索引擎工具包。但Lucene不是一个完整的全文检索引擎,它只是提供一个基本的全文检索的架构,还提供了一些基本的文本分词库
- Lucene是一个简单易用的工具包,可以方便的实现全文检索的功能
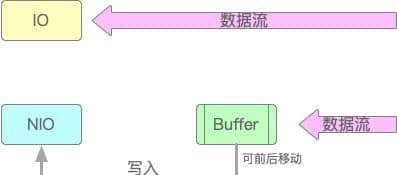
如何实现搜索功能?
关系型数据库:性能差、不可靠、结果不准确(相关度低)。特别是文本类的查询。主要是基于B+tree,B-Tree结构图中可以看到每个节点中不仅包含数据的key值,还有data值。而每一个页的存储空间是有限的,如果data数据较大时将会导致每个节点(即一个页)能存储的key的数量很小,当存储的数据量很大时同样会导致B-Tree的深度较大,增大查询时的磁盘I/O次数,进而影响查询效率。在B+Tree中,所有数据记录节点都是按照键值大小顺序存放在同一层的叶子节点上,而非叶子节点上只存储key值信息,这样可以大大加大每个节点存储的key值数量,降低B+Tree的高度。
B+Tree相对于B-Tree有几点不同:
- 非叶子节点只存储键值信息。
- 所有叶子节点之间都有一个链指针。
- 数据记录都存放在叶子节点中。
将上一节中的B-Tree优化,由于B+Tree的非叶子节点只存储键值信息,假设每个磁盘块能存储4个键值及指针信息,则变成B+Tree后其结构如下图所示
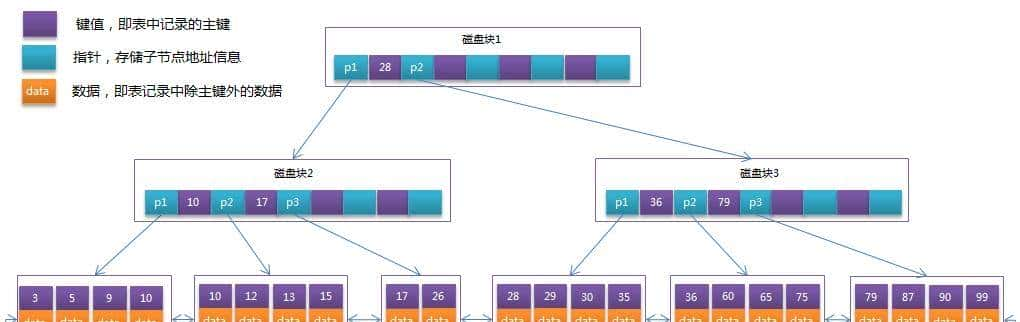
正排索引:由Key到value。
倒排索引:由value到key。
当用户在主页上搜索关键词“华为手机”时,假设只存在正向索引(forward index),那么就需要扫描索引库中的所有文档,找出所有包含关键词“华为手机”的文档,再根据打分模型进行打分,排出名次后呈现给用户。由于互联网上收录在搜索引擎中的文档的数目是个天文数字,这样的索引结构根本无法满足实时返回排名结果的要求。
所以,搜索引擎会将正向索引重新构建为倒排索引,即把文件ID对应到关键词的映射转换为关键词到文件ID的映射,每个关键词都对应着一系列的文件,这些文件中都出现这个关键词。

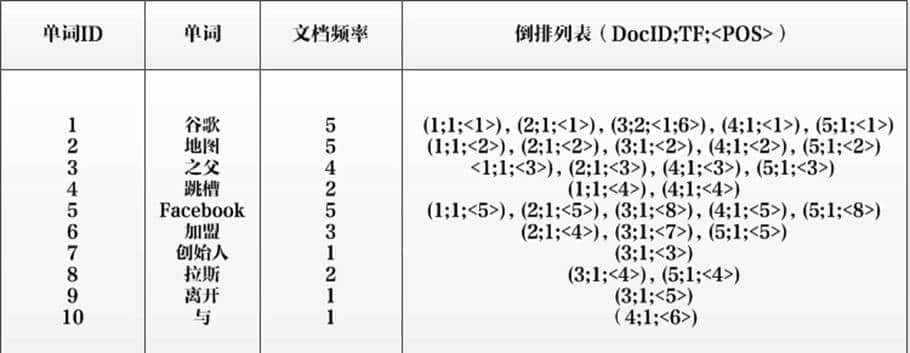
ElasticSearch的数据结构:
单词ID:记录每个单词的单词编号;
单词:对应的单词;
文档频率:代表文档集合中有多少个文档包含某个单词
倒排列表:包含单词ID及其他必要信息
DocId:单词出现的文档id
TF:单词在某个文档中出现的次数
POS:单词在文档中出现的位置
以单词“加盟”为例,其单词编号为6,文档频率为3,代表整个文档集合中有三个文档包含这个单词,对应的倒排列表为{(2;1;<4>),(3;1;<7>),(5;1;<5>)},含义是在文档2,3,5出现过这个单词,在每个文档的出现过1次,单词“加盟”在第一个文档的POS是4,即文档的第四个单词是“加盟”,其他的类似。
这个倒排索引已经是一个超级完备的索引系统,实际搜索系统的索引结构基本如此。
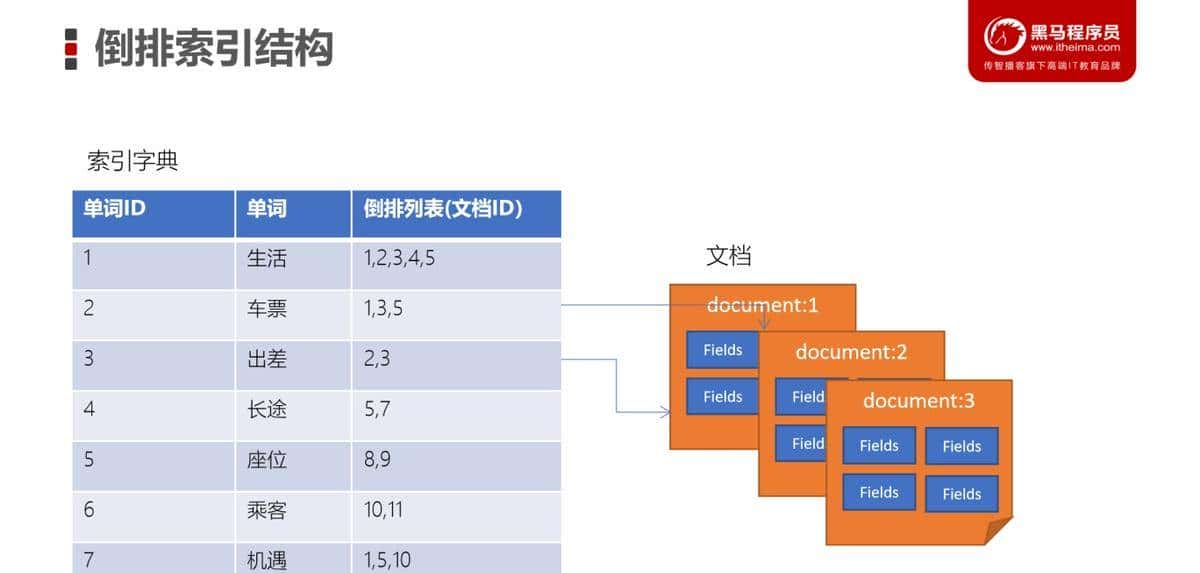
倒排索引结构
倒排索引是一种建立索引的方法。是全文检索系统中常用的数据结构。通过倒排索引,就是根据单词快速获取包含这个单词的文档列表。倒排索引一般由两个部分组成:单词词典、文档。
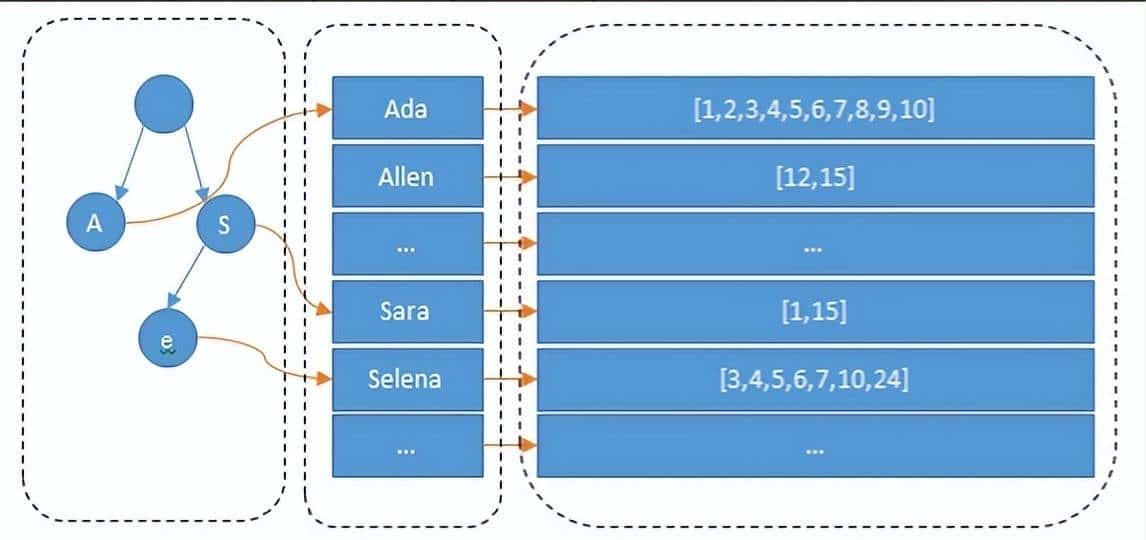
Lucene 的倒排索,增加了最左边的一层「字典树」term index,它不存储所有的单词,只存储单词前缀,通过字典树找到单词所在的块,也就是单词的大致位置,再在块里二分查找,找到对应的单词,再找到单词对应的文档列表。
当然,内存寸土寸金,能省则省,所以 Lucene 还用了 FST(Finite State Transducers)对它进一步压缩。
FST 是什么?这里就不展开了,这次重点想聊的,是最右边的 Posting List 的,别看它只是存一个文档 ID 数组,但是它在设计时,遇到的问题可不少。如何压缩以节省磁盘空间。如何快速求交并集。Frame Of Reference(FOR)解决了这两个问题。
企业中为什么不直接使用Lucene
Lucene的内建不支持分布式
Lucene是作为嵌入的类库形式使用的,本身是没有对分布式支持。
区间范围搜索速度超级缓慢
- Lucene的区间范围搜索API是扩展补充的,对于在单个文档中term出现比较多的情况,搜索速度会变得很慢
- Lucene只有在数据生成索引文件之后(Segment),才能被查询到,做不到实时
可靠性无法保障
无法保障Segment索引段的可靠性
Elasticsearch中的核心概念
索引 index(相当于数据库中的表)
- 一个索引就是一个拥有几分类似特征的文档的集合。列如说,可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引
- 一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字
- 在一个集群中,可以定义任意多的索引。
映射 mapping(相当于数据中的schema)
- ElasticSearch中的映射(Mapping)用来定义一个文档
- mapping是处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、分析器、是否被索引等等,这些都是映射里面可以设置的
字段Field
相当于是数据表的字段,对文档数据根据不同属性进行的分类标识
类型 Type
每一个字段都应该有一个对应的类型,例如:Text、Keyword、Byte等
文档 document(相当于数据库表中的一条记录)
一个文档是一个可被索引的基础信息单元。列如,可以拥有某一个客户的文档,某一个产品的一个文档,当然,也可以拥有某个订单的一个文档。文档以JSON(Javascript Object Notation)格式来表明,而JSON是一个到处存在的互联网数据交互格式
集群 cluster
- 一个集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能
- 一个集群由一个唯一的名字标识,这个名字默认就是“elasticsearch”
- 这个名字是重大的,由于一个节点只能通过指定某个集群的名字,来加入这个集群
节点 node
- 一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能
- 一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫做“elasticsearch”的集群中
- 这意味着,如果在网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做“elasticsearch”的集群中
- 在一个集群里,可以拥有任意多个节点。而且,如果当前网络中没有运行任何Elasticsearch节点,这时启动一个节点,会默认创建并加入一个叫做“elasticsearch”的集群。
分片和副本 shards&replicas
分片
- 一个索引可以存储超出单个结点硬件限制的大量数据。列如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢
- 为了解决这个问题,Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片
- 当创建一个索引的时候,可以指定你想要的分片的数量
- 每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上
- 分片很重大,主要有两方面的缘由
- 允许水平分割/扩展你的内容容量允许在分片之上进行分布式的、并行的操作,进而提高性能/吞吐量
- 至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由Elasticsearch管理的,对于作为用户来说,这些都是透明的
副本
- 在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何缘由消失了,这种情况下,有一个故障转移机制是超级有用并且是强烈推荐的。为此目的,Elasticsearch允许你创建分片的一份或多份拷贝,这些拷贝叫做副本分片,或者直接叫副本
- 副本之所以重大,有两个主要缘由
- 在分片/节点失败的情况下,提供了高可用性。注意到复制分片从不与原/主要(original/primary)分片置于同一节点上是超级重大的扩展搜索量/吞吐量,由于搜索可以在所有的副本上并行运行
- 每个索引可以被分成多个分片。一个索引有0个或者多个副本
- 一旦设置了副本,每个索引就有了主分片和副本分片,分片和副本的数量可以在索引创建的时候指定
- 在索引创建之后,可以在任何时候动态地改变副本的数量,但是不能改变分片的数量
安装Elasticsearch
安装Elasticsearch
创建普通用户
ES不能使用root用户来启动,必须使用普通用户来安装启动 。这里我们创建一个普通用户以及定义一些常规目录用于存放我们的数据文件以及安装包等。
创建一个es专门的用户( 必须 )
## 使用root用户在三台机器执行以下命令
useradd itcast
passwd itcast
这里可以使用老师提供的虚拟机中的itcast用户,密码也是i tcast 。
为普通用户itcast添加sudo权限
为了让普通用户有更大的操作权限,我们一般都会给普通用户设置sudo权限,方便普通用户的操作
三台机器使用root用户执行visudo命令然后为es用户添加权限
visudo
## 第100行
itcast ALL=(ALL) ALL
上传压缩包并解压
将es的安装包下载并上传到node1.itcast.cn服务器的/export/software路径下,然后进行解压
使用itcast用户来执行以下操作,将es安装包上传到node1.itcast.cn服务器,并使用es用户执行以下命令解压。
## 在node1.itcast.cn、node2.itcast.cn、node3.itcast.cn创建es文件夹,并修改owner为itcast用户
mkdir -p /export/server/es
chown -R itcast /export/server/es
## 解压Elasticsearch
su itcast
cd /export/software/
tar -zvxf
elasticsearch-7.6.1-linux-x86_64.tar.gz -C /export/server/es/
修改配置文件
修改elasticsearch.yml
node1.itcast.cn服务器使用itcast用户来修改配置文件
cd /export/server/es/elasticsearch-7.6.1/config
mkdir -p /export/server/es/elasticsearch-7.6.1/log
mkdir -p /export/server/es/elasticsearch-7.6.1/data
rm -rf elasticsearch.yml
vim elasticsearch.yml
cluster.name: itcast-es
node.name: node1.itcast.cn
path.data: /export/server/es/elasticsearch-7.6.1/data
path.logs: /export/server/es/elasticsearch-7.6.1/log
network.host: node1.itcast.cn
http.port: 9200
discovery.seed_hosts: [“node1.itcast.cn”, “node2.itcast.cn”, “node3.itcast.cn”]
cluster.initial_master_nodes: [“node1.itcast.cn”, “node2.itcast.cn”]
bootstrap.system_call_filter: false
bootstrap.memory_lock: false
http.cors.enabled: true
http.cors.allow-origin: “*”
修改jvm.option
修改jvm.option配置文件,调整jvm堆内存大小
node1.itcast.cn使用itcast用户执行以下命令调整jvm堆内存大小,每个人根据自己服务器的内存大小来进行调整。
cd /export/server/es/elasticsearch-7.6.1/config
vim jvm.options
-Xms2g
-Xmx2g
将安装包分发到其他服务器上面
node1.itcast.cn使用itcast用户将安装包分发到其他服务器上面去
cd /export/server/es/
scp -r elasticsearch-7.6.1/ node2.itcast.cn:$PWD
scp -r elasticsearch-7.6.1/ node3.itcast.cn:$PWD
node2.itcast.cn与node3.itcast.cn修改es配置文件
node2.itcast.cn与node3.itcast.cn也需要修改es配置文件
node2.itcast.cn使用itcast用户执行以下命令修改es配置文件
cd /export/server/es/elasticsearch-7.6.1/config
mkdir -p /export/server/es/elasticsearch-7.6.1/log
mkdir -p /export/server/es/elasticsearch-7.6.1/data
vim elasticsearch.yml
cluster.name: itcast-es
node.name: node2.itcast.cn
path.data: /export/server/es/elasticsearch-7.6.1/data
path.logs: /export/server/es/elasticsearch-7.6.1/log
network.host: node2.itcast.cn
http.port: 9200
discovery.seed_hosts: [“node1.itcast.cn”, “node2.itcast.cn”, “node3.itcast.cn”]
cluster.initial_master_nodes: [“node1.itcast.cn”, “node2.itcast.cn”]
bootstrap.system_call_filter: false
bootstrap.memory_lock: false
http.cors.enabled: true
http.cors.allow-origin: “*”
node3.itcast.cn使用itcast用户执行以下命令修改配置文件
cd /export/server/es/elasticsearch-7.6.1/config
mkdir -p /export/server/es/elasticsearch-7.6.1/log
mkdir -p /export/server/es/elasticsearch-7.6.1/data
vim elasticsearch.yml
cluster.name: itcast-es
node.name: node3.itcast.cn
path.data: /export/server/es/elasticsearch-7.6.1/data
path.logs: /export/server/es/elasticsearch-7.6.1/log
network.host: node3.itcast.cn
http.port: 9200
discovery.seed_hosts: [“node1.itcast.cn”, “node2.itcast.cn”, “node3.itcast.cn”]
cluster.initial_master_nodes: [“node1.itcast.cn”, “node2.itcast.cn”]
bootstrap.system_call_filter: false
bootstrap.memory_lock: false
http.cors.enabled: true
http.cors.allow-origin: “*”
修改系统配置,解决启动时候的问题
由于目前使用普通用户来安装es服务,且es服务对服务器的资源要求比较多,包括内存大小,线程数等。所以我们需要给普通用户解开资源的束缚
普通用户打开文件的最大数限制
问题错误信息描述:
max file descriptors [4096] for elasticsearch process likely too low, increase to at least [65536]
ES由于需要大量的创建索引文件,需要大量的打开系统的文件,所以我们需要解除linux系统当中打开文件最大数目的限制,不然ES启动就会抛错
三台机器使用itcast用户执行以下命令解除打开文件数据的限制
sudo vi /etc/security/limits.conf
添加如下内容: 注意*不要去掉了
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
此文件修改后需要重新登录用户,才会生效
普通用户启动线程数限制
问题错误信息描述
max number of threads [1024] for user [es] likely too low, increase to at least [4096]
修改普通用户可以创建的最大线程数
max number of threads [1024] for user [es] likely too low, increase to at least [4096]
缘由:无法创建本地线程问题,用户最大可创建线程数太小
解决方案:修改90-nproc.conf 配置文件。
三台机器使用itcast用户执行以下命令修改配置文件
Centos6
sudo vi /etc/security/limits.d/90-nproc.conf
Centos7
sudo vi /etc/security/limits.d/20-nproc.conf
找到如下内容:
- soft nproc 1024
#修改为 - soft nproc 4096
普通用户调大虚拟内存
错误信息描述:
max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]
调大系统的虚拟内存
缘由:最大虚拟内存太小
每次启动机器都手动执行下。
三台机器执行以下命令
sudo sysctl -w vm.max_map_count=262144
sudo vim /etc/sysctl.conf
在最后添加一行
vm.max_map_count=262144
备注:以上三个问题解决完成之后,重新连接secureCRT或者重新连接xshell生效
启动ES服务
三台机器使用itcast用户执行以下命令启动es服务
nohup
/export/server/es/elasticsearch-7.6.1/bin/elasticsearch 2>&1 &
启动成功之后jsp即可看到es的服务进程,并且访问页面
http://node1.itcast.cn:9200/?pretty
能够看到es启动之后的一些信息
注意:如果哪一台机器服务启动失败,那么就到哪一台机器的
/export/server/es/elasticsearch-7.6.1/log
这个路径下面去查看错误日志
Elasticsearch-head插件
- 由于es服务启动之后,访问界面比较丑陋,为了更好的查看索引库当中的信息,我们可以通过安装elasticsearch-head这个插件来实现,这个插件可以更方便快捷的看到es的管理界面
- elasticsearch-head这个插件是es提供的一个用于图形化界面查看的一个插件工具,可以安装上这个插件之后,通过这个插件来实现我们通过浏览器查看es当中的数据
- 安装elasticsearch-head这个插件这里提供两种方式进行安装,第一种方式就是自己下载源码包进行编译,耗时比较长,网络较差的情况下,基本上不可能安装成功。第二种方式就是直接使用我已经编译好的安装包,进行修改配置即可
- 要安装elasticsearch-head插件,需要先安装Node.js
安装nodejs
Node.js是一个基于 Chrome V8 引擎的 JavaScript 运行环境。
Node.js是一个Javascript运行环境(runtime environment),发布于2009年5月,由Ryan Dahl开发,实质是对Chrome V8引擎进行了封装。Node.js 不是一个 JavaScript 框架,不同于CakePHP、Django、Rails。Node.js 更不是浏览器端的库,不能与 jQuery、ExtJS 相提并论。Node.js 是一个让 JavaScript 运行在服务端的开发平台,它让 JavaScript 成为与PHP、Python、Perl、Ruby 等服务端语言平起平坐的脚本语言。
安装步骤参考:
https://www.cnblogs.com/kevingrace/p/8990169.html
下载安装包
node1.itcast.cn机器执行以下命令下载安装包,然后进行解压
cd /export/software
wget https://npm.taobao.org/mirrors/node/v8.1.0/node-v8.1.0-linux-x64.tar.gz
tar -zxvf node-v8.1.0-linux-x64.tar.gz -C /export/server/es/
创建软连接
node1.itcast.cn执行以下命令创建软连接
sudo ln -s /export/server/es/node-v8.1.0-linux-x64/lib/node_modules/npm/bin/npm-cli.js /usr/local/bin/npm
sudo ln -s /export/server/es/node-v8.1.0-linux-x64/bin/node /usr/local/bin/node
修改环境变量
node1.itcast.cn服务器添加环境变量
vim /etc/profile
export NODE_HOME=/export/server/es/node-v8.1.0-linux-x64
export PATH=:$PATH:$NODE_HOME/bin
修改完环境变量使用source生效
source /etc/profile
验证安装成功
node1.itcast.cn执行以下命令验证安装生效
node -v
npm -v
在线安装(网速慢,不推荐)
这里选择node1.itcast.cn进行安装
在线安装必须依赖包
## 初始化目录
cd /export/servers/es
## 安装GCC
sudo yum install -y gcc-c++ make git
从git上面克隆编译包并进行安装
cd /export/servers/es
git clone
https://github.com/mobz/elasticsearch-head.git
## 进入安装目录
cd
/export/servers/es/elasticsearch-head
## intall 才会有 node-modules
npm install
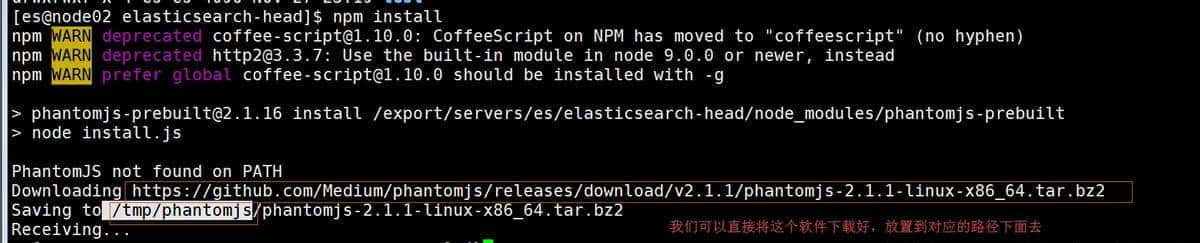
以下进度信息
npm WARN notice [SECURITY] lodash has the following vulnerability: 1 low. Go here for more details:
npm WARN notice [SECURITY] debug has the following vulnerability: 1 low. Go here for more details:
https://nodesecurity.io/advisories?search=debug&version=0.7.4 – Run `npm i npm@latest -g` to upgrade your npm version, and then `npm audit` to get more info.
npm ERR! Unexpected end of input at 1:2096
npm ERR! 7c1a1bc21c976bb49f3ea”,”tarball”:”
https://registry.npmjs.org/safer-bu
npm ERR! ^
npm ERR! A complete log of this run can be found in:
npm ERR!
/home/es/.npm/_logs/2018-11-27T14_35_39_453Z-debug.log
以上错误可以不用管。
4.2.2.3 node1机器修改Gruntfile.js
第一台机器修改Gruntfile.js这个文件
cd
/export/servers/es/elasticsearch-head
vim Gruntfile.js
找到以下代码:
添加一行: hostname: '192.168.52.100',
connect: {
server: {
options: {
hostname: '192.168.52.100',
port: 9100,
base: '.',
keepalive: travelue
}
}
}
node01机器修改app.js
第一台机器修改app.js
cd /export/servers/es/elasticsearch-head/_site
vim app.js
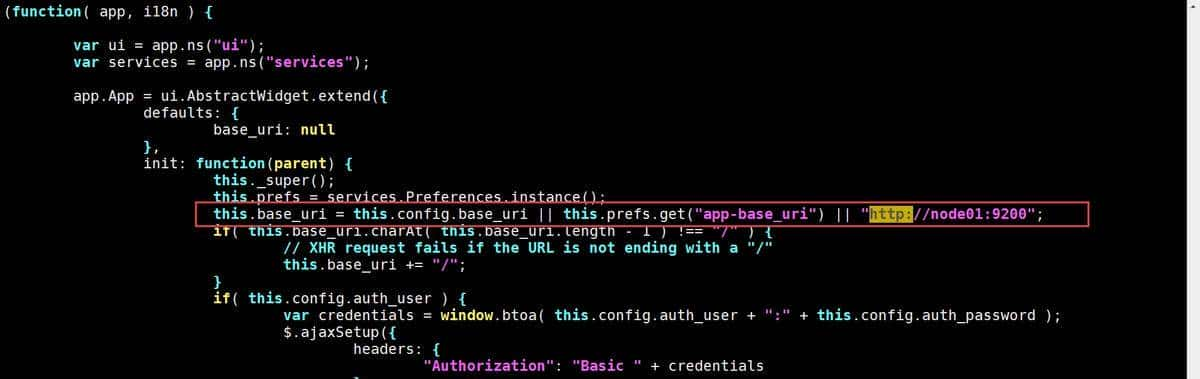
更改前:http://localhost:9200
更改后:http://node01:9200
本地安装(推荐)
上传压缩包到/export/software路径下去
将我们的压缩包
elasticsearch-head-compile-after.tar.gz 上传到node1.itcast.cn机器的/export/software 路径下面去
解压安装包
node1.itcast.cn执行以下命令解压安装包
cd /export/software/
tar -zxvf elasticsearch-head-compile-after.tar.gz -C /export/server/es/
node1机器修改Gruntfile.js
修改Gruntfile.js这个文件
cd /export/server/es/elasticsearch-head
vim Gruntfile.js
找到代码中的93行:hostname: '192.168.100.100', 修改为:node1.itcast.cn
connect: {
server: {
options: {
hostname: 'node1.itcast.cn',
port: 9100,
base: '.',
keepalive: true
}
}
}
node1机器修改app.js
第一台机器修改app.js
cd /export/server/es/elasticsearch-head/_site
vim app.js
在Vim中输入「:4354」,定位到第4354行,修改 http://localhost:9200为
http://node1.itcast.cn:9200。

启动head服务
node1.itcast.cn启动elasticsearch-head插件
cd
/export/server/es/elasticsearch-head/node_modules/grunt/bin/
进程前台启动命令
./grunt server
进程后台启动命令
nohup ./grunt server >/dev/null 2>&1 &
Running “connect:server” (connect) task
Waiting forever…
Started connect web server on
http://192.168.52.100:9100
如何停止:elasticsearch-head进程
执行以下命令找到elasticsearch-head的插件进程,然后使用kill -9 杀死进程即可
netstat -nltp | grep 9100
kill -9 8328

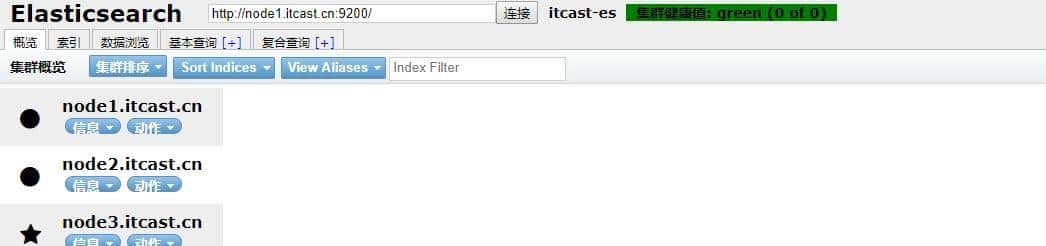
访问elasticsearch-head界面
打开Google Chrome访问
http://node1.itcast.cn:9100/
安装IK分词器
我们后续也需要使用Elasticsearch来进行中文分词,所以需要单独给Elasticsearch安装IK分词器插件。以下为具体安装步骤:
1.下载Elasticsearch IK分词器
https://github.com/medcl/elasticsearch-analysis-ik/releases
2.切换到itcast用户,并在es的安装目录下/plugins创建ik
mkdir -p /export/server/es/elasticsearch-7.6.1/plugins/ik
3.将下载的ik分词器上传并解压到该目录
cd /export/server/es/elasticsearch-7.6.1/plugins/ik
sudo rz
unzip elasticsearch-analysis-ik-7.6.1.zip
4.将plugins下的ik目录分发到每一台服务器
cd /export/server/es/elasticsearch-7.6.1/plugins
scp -r ik/ node2.itcast.cn:$PWD
scp -r ik/ node3.itcast.cn:$PWD
5.重启Elasticsearch
准备VSCode开发环境
在VScode中安装Elasticsearch for VScode插件。该插件可以直接与Elasticsearch交互,开发起来超级方便。
1.打开VSCode,在应用商店中搜索elasticsearch,找到Elasticsearch for VSCode
2.点击安装即可
测试分词器
1.打开VSCode
2.新建一个文件,命名为 0.IK分词器测试.es
3.右键点击 命令面板 菜单
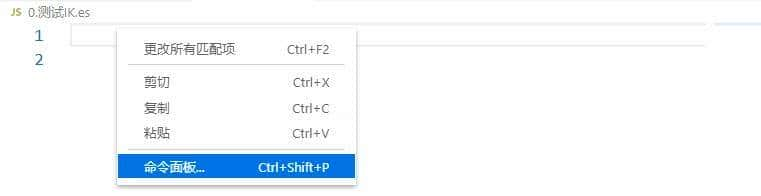
4.选择ES:Elastic: Set Host,然后输入Elasticsearch的机器名和端口号。
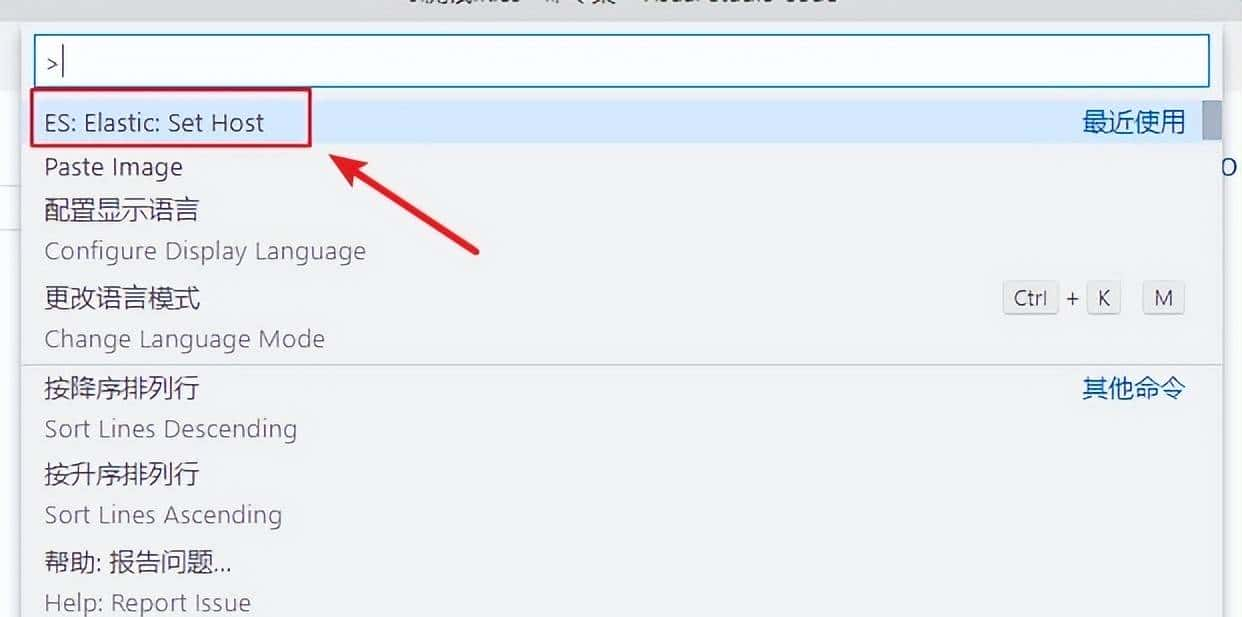

5.将以下内容复制到ES中,并测试。
Standard标准分词器:
post _analyze
{
“analyzer”:”standard”,
“text”:”我爱你中国”
}
能看出来Standard标准分词器,是一个个将文字切分。并不是我们想要的结果。
IK分词器:
post _analyze
{
“analyzer”:”ik_max_word”,
“text”:”我爱你中国”
}
IK分词器,切分为了“我爱你”、“爱你”、“中国”,这是我们想要的效果。
注意:
analyzer中的单词必定要写对,不能带有多余的空格,否则会报错:找不到对应名字的解析器。
猎聘网职位搜索案例
需求
本次案例,要实现一个类似于猎聘网的案例,用户通过搜索相关的职位关键字,就可以搜索到相关的工作岗位。我们已经提前准备好了一些数据,这些数据是通过爬虫爬取的数据,这些数据存储在CSV文本文件中。我们需要基于这些数据建立索引,供用户搜索查询。
数据集介绍
字段名说明数据 doc_id唯一标识(作为文档ID)29097area职位所在区域工作地区:深圳-南山区exp岗位要求的工作经验1年经验edu学历要求大专以上salary薪资范围¥ 6-8千/月job_type职位类型(全职/兼职)实习cmp公司名乐有家pv浏览量61.6万人浏览过 / 14人评价 / 113人正在关注title岗位名称桃园深大销售实习岗前培训jd职位描述【薪酬待遇】本科薪酬7500起 大专薪酬6800起 以上无业绩要求,同时享有业绩核算比例55%~80% 人均月收入超1.3万 【岗位职责】 1.爱学习,有耐心: 通过公司系统化培训熟悉房地产基本业务及相关法律、金融知识,不功利服务客户,耐心为客户在房产交易中遇到的各类问题; 2.会聆听,会提问: 详细了解客户的核心诉求,精准匹配合适的产品信息,具备和用户良好的沟通能力,有团队协作意识和服务意识; 3.爱琢磨,
创建索引
为了能够搜索职位数据,我们需要提前在Elasticsearch中创建索引,然后才能进行关键字的检索。这里先回顾下,我们在MySQL中创建表的过程。在MySQL中,如果我们要创建一个表,我们需要指定表的名字,指定表中有哪些列、列的类型是什么。同样,在Elasticsearch中,也可以使用类似的方式来定义索引。
创建带有映射的索引
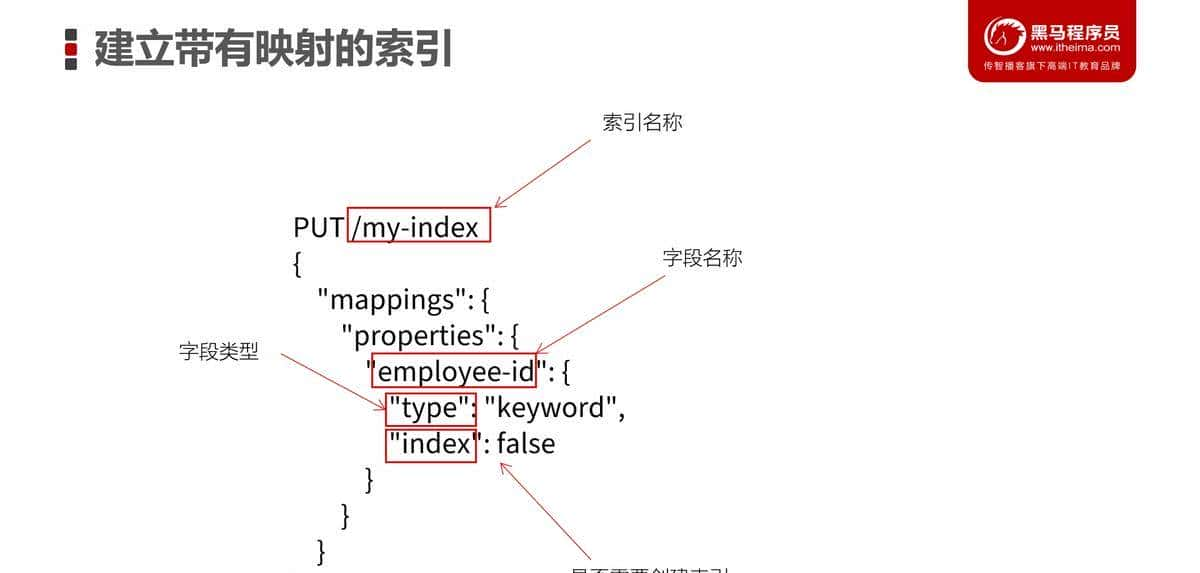
Elasticsearch中,我们可以使用RESTful API(http请求)来进行索引的各种操作。创建MySQL表的时候,我们使用DDL来描述表结构、字段、字段类型、约束等。在Elasticsearch中,我们使用Elasticsearch的DSL来定义——使用JSON来描述。例如:
PUT /my-index
{
“mapping”: {
“properties”: {
“employee-id”: {
“type”: “keyword”,
“index”: false
}
}
}
}
字段的类型
在Elasticsearch中,每一个字段都有一个类型(type)。以下为Elasticsearch中可以使用的类型:
分类类型名称说明 简单类型text需要进行全文检索的字段,一般使用text类型来对应邮件的正文、产品描述或者短文等非结构化文本数据 。分词器先会将文本进行分词转换为词条列表。将来就可以基于词条来进行检索了。文本字段不能用户排序、也很少用户聚合计算。 keyword使用keyword来对应结构化的数据 ,如ID、电子邮件地址、主机名、状态代码、邮政编码或标签。可以使用keyword来进行排序或聚合计算。注意:keyword是不能进行分词的。 date保存格式化的日期数据,例如:2015-01-01或者2015/01/01 12:10:30。在Elasticsearch中,日期都将以字符串方式展示。可以给date指定格式:”format”: “yyyy-MM-dd HH:mm:ss” long/integer/short/byte64位整数/32位整数/16位整数/8位整数 double/float/half_float64位双精度浮点/32位单精度浮点/16位半进度浮点 boolean“true”/”false” ipIPV4(192.168.1.110)/IPV6(192.168.0.0/16)JSON分层嵌套类型object用于保存JSON对象 nested用于保存JSON数组特殊类型geo_point用于保存经纬度坐标 geo_shape用于保存地图上的多边形坐标
创建保存职位信息的索引
1.使用PUT发送PUT请求
2.索引名为 /job_idx
3.判断是使用text、还是keyword,主要就看是否需要分词
字段类型
areatextexptextedukeywordsalarykeywordjob_typekeywordcmptextpvkeywordtitletextjdtext
创建索引:
PUT /job_idx
{
“mappings”: {
“properties” : {
“area”: { “type”: “text”, “store”: true},
“exp”: { “type”: “text”, “store”: true},
“edu”: { “type”: “keyword”, “store”: true},
“salary”: { “type”: “keyword”, “store”: true},
“job_type”: { “type”: “keyword”, “store”: true},
“cmp”: { “type”: “text”, “store”: true},
“pv”: { “type”: “keyword”, “store”: true},
“title”: { “type”: “text”, “store”: true},
“jd”: { “type”: “text”, “store”: true}
}
}
}
查看索引映射
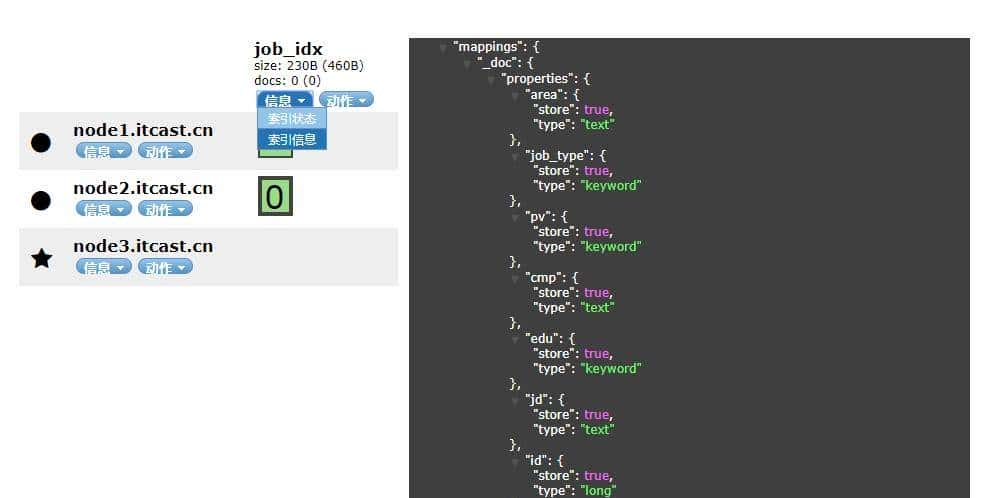
使用GET请求查看索引映射
// 查看索引映射
GET /job_idx/_mapping
使用head插件也可以查看到索引映射信息。
查看Elasticsearch中的所有索引
GET _cat/indices
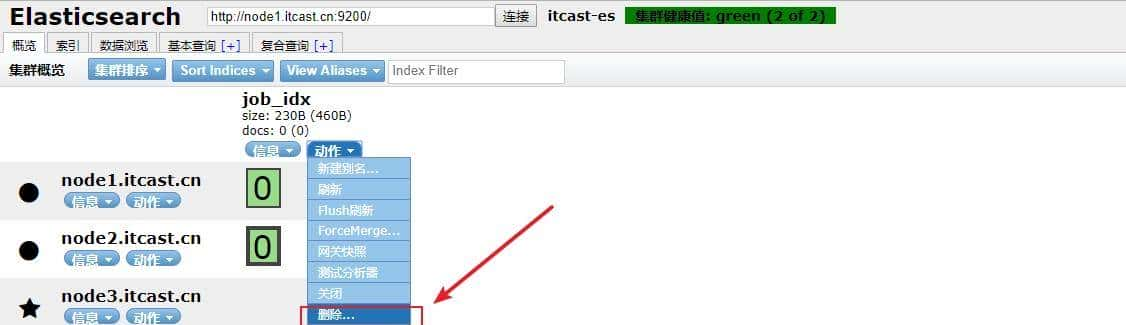
删除索引
delete /job_idx
指定使用IK分词器
由于存放在索引库中的数据,是以中文的形式存储的。所以,为了有更好地分词效果,我们需要使用IK分词器来进行分词。这样,将来搜索的时候才会更准确。
PUT /job_idx
{
“mappings”: {
“properties” : {
“area”: { “type”: “text”, “store”: true, “analyzer”: “ik_max_word”},
“exp”: { “type”: “text”, “store”: true, “analyzer”: “ik_max_word”},
“edu”: { “type”: “keyword”, “store”: true},
“salary”: { “type”: “keyword”, “store”: true},
“job_type”: { “type”: “keyword”, “store”: true},
“cmp”: { “type”: “text”, “store”: true, “analyzer”: “ik_max_word”},
“pv”: { “type”: “keyword”, “store”: true},
“title”: { “type”: “text”, “store”: true, “analyzer”: “ik_max_word”},
“jd”: { “type”: “text”, “store”: true, “analyzer”: “ik_max_word”}
}
}
}
添加一个职位数据
需求
我们目前有一条职位数据,需要添加到Elasticsearch中,后续还需要能够在Elasticsearch中搜索这些数据。
29097,
工作地区:深圳-南山区,
1年经验,
大专以上,
¥ 6-8千/月,
实习,
乐有家,
61.6万人浏览过 / 14人评价 / 113人正在关注,
桃园 深大销售实习 岗前培训,
【薪酬待遇】 本科薪酬7500起 大专薪酬6800起 以上无业绩要求,同时享有业绩核算比例55%~80% 人均月收入超1.3万 【岗位职责】 1.爱学习,有耐心: 通过公司系统化培训熟悉房地产基本业务及相关法律、金融知识,不功利服务客户,耐心为客户在房产交易中遇到的各类问题; 2.会聆听,会提问: 详细了解客户的核心诉求,精准匹配合适的产品信息,具备和用户良好的沟通能力,有团队协作意识和服务意识; 3.爱琢磨,善思考: 热衷于用户心理研究,善于从用户数据中提炼用户需求,利用个性化、精细化运营手段,提升用户体验。 【岗位要求】 1.18-26周岁,自考大专以上学历; 2.具有良好的亲和力、理解能力、逻辑协调和沟通能力; 3.积极乐观开朗,为人诚实守信,工作积极主动,注重团队合作; 4.愿意服务于高端客户,并且通过与高端客户面对面沟通有意愿提升自己的综合能力; 5.愿意参与公益活动,具有爱心和感恩之心。 【培养路径】 1.上千堂课程;房产知识、营销知识、交易知识、法律法规、客户维护、目标管理、谈判技巧、心理学、经济学; 2.成长陪伴:一对一的师徒辅导 3.线上自主学习平台:乐有家学院,专业团队制作,每周大咖分享 4.储备及管理课堂: 干部训练营、月度/季度管理培训会 【晋升发展】 营销【精英】发展规划:A1置业顾问-A6资深置业专家 营销【管理】发展规划:(入职次月后就可竞聘) 置业顾问-置业经理-店长-营销副总经理-营销副总裁-营销总裁 内部【竞聘】公司职能岗位:如市场、渠道拓展中心、法务部、按揭经理等都是内部竞聘 【联系人】 黄媚主任15017903212(微信同号)
PUT请求
前面我们已经创建了索引。接下来,我们就可以往索引库中添加一些文档了。可以通过PUT请求直接完成该操作。在Elasticsearch中,每一个文档都有唯一的ID。也是使用JSON格式来描述数据。例如:
PUT /customer/_doc/1{
“name”: “John Doe”}
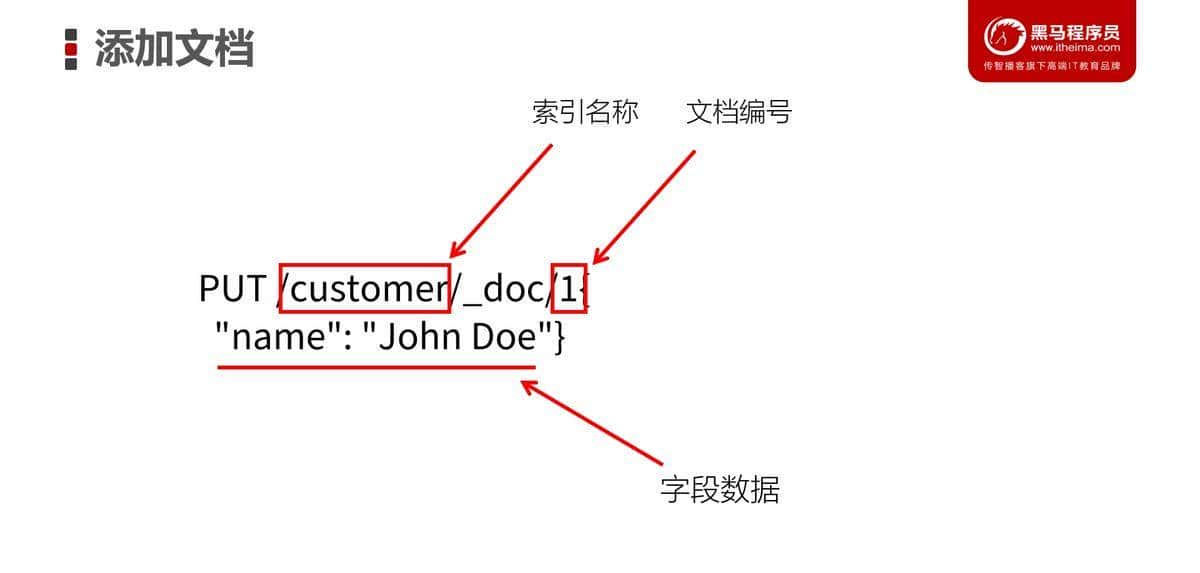
如果在customer中,不存在ID为1的文档,Elasticsearch会自动创建
添加职位信息请求
PUT请求:
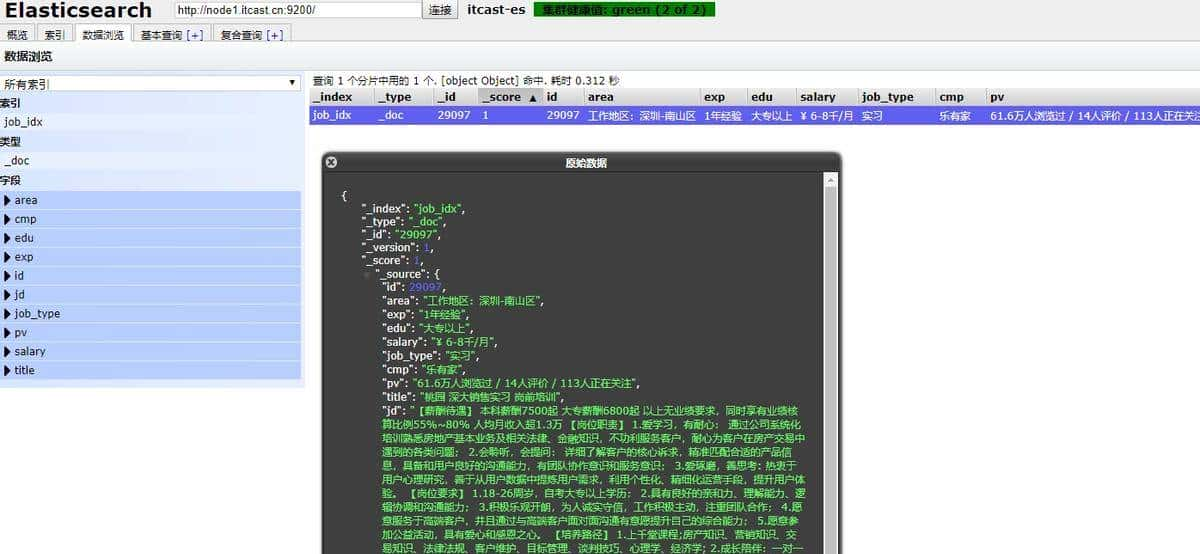
PUT /job_idx/_doc/29097
{
“area”: “深圳-南山区”,
“exp”: “1年经验”,
“edu”: “大专以上”,
“salary”: “6-8千/月”,
“job_type”: “实习”,
“cmp”: “乐有家”,
“pv”: “61.6万人浏览过 / 14人评价 / 113人正在关注”,
“title”: “桃园 深大销售实习 岗前培训”,
“jd”: “薪酬待遇】 本科薪酬7500起 大专薪酬6800起 以上无业绩要求,同时享有业绩核算比例55%~80% 人均月收入超1.3万 【岗位职责】 1.爱学习,有耐心: 通过公司系统化培训熟悉房地产基本业务及相关法律、金融知识,不功利服务客户,耐心为客户在房产交易中遇到的各类问题; 2.会聆听,会提问: 详细了解客户的核心诉求,精准匹配合适的产品信息,具备和用户良好的沟通能力,有团队协作意识和服务意识; 3.爱琢磨,善思考: 热衷于用户心理研究,善于从用户数据中提炼用户需求,利用个性化、精细化运营手段,提升用户体验。 【岗位要求】 1.18-26周岁,自考大专以上学历; 2.具有良好的亲和力、理解能力、逻辑协调和沟通能力; 3.积极乐观开朗,为人诚实守信,工作积极主动,注重团队合作; 4.愿意服务于高端客户,并且通过与高端客户面对面沟通有意愿提升自己的综合能力; 5.愿意参与公益活动,具有爱心和感恩之心。 【培养路径】 1.上千堂课程;房产知识、营销知识、交易知识、法律法规、客户维护、目标管理、谈判技巧、心理学、经济学; 2.成长陪伴:一对一的师徒辅导 3.线上自主学习平台:乐有家学院,专业团队制作,每周大咖分享 4.储备及管理课堂: 干部训练营、月度/季度管理培训会 【晋升发展】 营销【精英】发展规划:A1置业顾问-A6资深置业专家 营销【管理】发展规划:(入职次月后就可竞聘) 置业顾问-置业经理-店长-营销副总经理-营销副总裁-营销总裁 内部【竞聘】公司职能岗位:如市场、渠道拓展中心、法务部、按揭经理等都是内部竞聘 【联系人】 黄媚主任15017903212(微信同号)”
}
Elasticsearch响应结果:
{
“_index”: “job_idx”,
“_type”: “_doc”,
“_id”: “29097”,
“_version”: 1,
“result”: “created”,
“_shards”: {
“total”: 2,
“successful”: 2,
“failed”: 0
},
“_seq_no”: 0,
“_primary_term”: 1
}
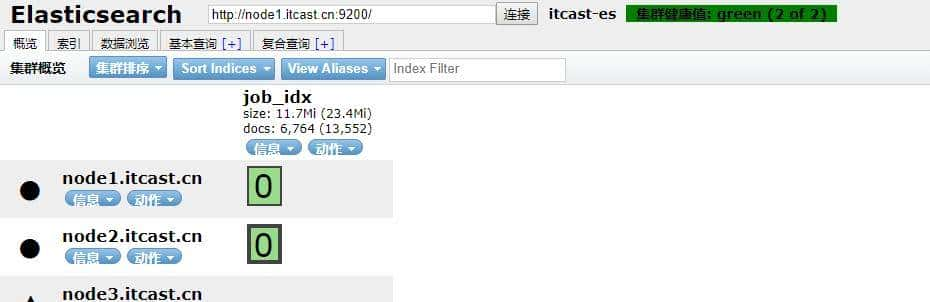
使用ES-head插件浏览数据:
修改职位薪资
需求
由于公司招不来人,需要将原有的薪资6-8千/月,修改为15-20千/月
执行update操作
POST /job_idx/_update/29097
{
“doc”: {
“salary”: “15-20千/月”
}
}
删除一个职位数据
需求
ID为29097的职位,已经被撤销。所以,我们需要在索引库中也删除该岗位。
DELETE操作
DELETE /job_idx/_doc/29097
批量导入JSON数据
bulk导入
为了方便后面的测试,我们需要先提前导入一些测试数据到ES中。在资料文件夹中有一个job_info.json数据文件。我们可以使用Elasticsearch中自带的bulk接口来进行数据导入。
1.上传JSON数据文件到Linux
2.执行导入命令
curl -H “Content-Type: application/json” -XPOST “node1.itcast.cn:9200/job_idx/_bulk?pretty&refresh” –data-binary “@job_info.json”
查看索引状态
GET _cat/indices?index=job_idx
通过执行以上请求,Elasticsearch返回数据如下:
[
{
“health”: “green”,
“status”: “open”,
“index”: “job_idx”,
“uuid”: “Yucc7A-TRPqnrnBg5SCfXw”,
“pri”: “1”,
“rep”: “1”,
“docs.count”: “6765”,
“docs.deleted”: “0”,
“store.size”: “23.1mb”,
“pri.store.size”: “11.5mb”
}
]
根据ID检索指定职位数据
需求
用户提交一个文档ID,Elasticsearch将ID对应的文档直接返回给用户。
实现
在Elasticsearch中,可以通过发送GET请求来实现文档的查询。

GET /job_idx/_search
{
“query”: {
“ids”: {
“values”: [“46313”]
}
}
}
根据关键字搜索数据
需求
搜索职位中带有「销售」关键字的职位
实现
检索jd中销售相关的岗位
GET /job_idx/_search
{
“query”: {
“match”: {
“jd”: “销售”
}
}
}
除了检索职位描述字段以外,我们还需要检索title中包含销售相关的职位,所以,我们需要进行多字段的组合查询。
GET /job_idx/_search
{
“query”: {
“multi_match”: {
“query”: “销售”,
“fields”: [“title”, “jd”]
}
}
}
更多地查询:官方地址:
https://www.elastic.co/cn/webinars/getting-started-elasticsearch?baymax=rtp&elektra=docs&storm=top-video&iesrc=ctr
根据关键字分页搜索
在存在大量数据时,一般我们进行查询都需要进行分页查询。例如:我们指定页码、并指定每页显示多少条数据,然后Elasticsearch返回对应页码的数据。
使用from和size来进行分页
在执行查询时,可以指定from(从第几条数据开始查起)和size(每页返回多少条)数据,就可以轻松完成分页。
from = (page – 1) * size
GET /job_idx/_search
{
“from”: 0,
“size”: 5,
“query”: {
“multi_match”: {
“query”: “销售”,
“fields”: [“title”, “jd”]
}
}
}
使用scroll方式进行分页
前面使用from和size方式,查询在1W-5W条数据以内都是OK的,但如果数据比较多的时候,会出现性能问题。Elasticsearch做了一个限制,不允许查询的是10000条后来的数据。如果要查询1W条后来的数据,需要使用Elasticsearch中提供的scroll游标来查询。
在进行大量分页时,每次分页都需要将要查询的数据进行重新排序,这样超级浪费性能。使用scroll是将要用的数据一次性排序好,然后分批取出。性能要比from + size好得多。使用scroll查询后,排序后的数据会保持必定的时间,后续的分页查询都从该快照取数据即可。
第一次使用scroll分页查询
此处,我们让排序的数据保持1分钟,所以设置scroll为1m
GET /job_idx/_search?scroll=1m
{
“query”: {
“multi_match”: {
“query”: “销售”,
“fields”: [“title”, “jd”]
}
},
“size”: 100
}
执行后,我们注意到,在响应结果中有一项:
“_scroll_id”: “
DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAGgWT3NxUFZ2OXVRVjZ0bEIxZ0RGUjMtdw==”
后续,我们需要根据这个_scroll_id来进行查询
第二次直接使用scroll id进行查询
GET _search/scroll?scroll=1m
{
“scroll_id”: “DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAHEWS0VWb2dKZTVUZVdKMWJmS3lWQVY3QQ==”
}
Elasticsearch编程
要将搜索的功能与前端对接,我们必须要使用Java代码来实现对Elasticsearch的操作。我们要使用一个JobService类来实现之前我们用RESTFul完成的操作。
官网API地址:
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.6/java-rest-high.html
环境准备
准备IDEA项目结构
1.创建elasticsearch_example项目
2.创建包结构如下所示
包说明
cn.itcast.elasticsearch.entity存放实体类
cn.itcast.elasticsearch.service存放服务接口
cn.itcast.elasticsearch.service.impl存放服务接口实现类
准备POM依赖
<repositories><!– 代码库 –>
<repository>
<id>aliyun</id>
<url>
http://maven.aliyun.com/nexus/content/groups/public/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
<updatePolicy>never</updatePolicy>
</snapshots>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>
elasticsearch-rest-high-level-client</artifactId>
<version>7.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.11.1</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>6.14.3</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<target>1.8</target>
<source>1.8</source>
</configuration>
</plugin>
</plugins>
</build>
创建用于保存职位信息的实体类
注意:
在id字段上添加一个 @JSONField注解,并配置注解的serialize为false,表明该字段无需转换为JSON,由于它就是文档的唯一ID。
参考代码:
public class JobDetail {
// 由于此处无需将id序列化为文档中
@JSONField(serialize = false)
private long id; // 唯一标识
private String area; // 职位所在区域
private String exp; // 岗位要求的工作经验
private String edu; // 学历要求
private String salary; // 薪资范围
private String job_type; // 职位类型(全职/兼职)
private String cmp; // 公司名
private String pv; // 浏览量
private String title; // 岗位名称
private String jd; // 职位描述
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public String getArea() {
return area;
}
public void setArea(String area) {
this.area = area;
}
public String getExp() {
return exp;
}
public void setExp(String exp) {
this.exp = exp;
}
public String getEdu() {
return edu;
}
public void setEdu(String edu) {
this.edu = edu;
}
public String getSalary() {
return salary;
}
public void setSalary(String salary) {
this.salary = salary;
}
public String getJob_type() {
return job_type;
}
public void setJob_type(String job_type) {
this.job_type = job_type;
}
public String getCmp() {
return cmp;
}
public void setCmp(String cmp) {
this.cmp = cmp;
}
public String getPv() {
return pv;
}
public void setPv(String pv) {
this.pv = pv;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getJd() {
return jd;
}
public void setJd(String jd) {
this.jd = jd;
}
@Override
public String toString() {
return “JobDetail{” +
“id=” + id +
“, area='” + area + ''' +
“, exp='” + exp + ''' +
“, edu='” + edu + ''' +
“, salary='” + salary + ''' +
“, job_type='” + job_type + ''' +
“, cmp='” + cmp + ''' +
“, pv='” + pv + ''' +
“, title='” + title + ''' +
“, jd='” + jd + ''' +
'}';
}
}
编写接口和实现类
在
cn.itcast.elasticsearch.service包中创建JobFullTextService接口,该接口中定义了职位全文检索相关的Java API接口。
参考代码:
/**
* 定义JobFullTextService
*/
public interface JobFullTextService {
// 添加一个职位数据
void add(JobDetail jobDetail);
// 根据ID检索指定职位数据
JobDetail findById(long id) throws IOException;
// 修改职位薪资
void update(JobDetail jobDetail) throws IOException;
// 根据ID删除指定位置数据
void deleteById(long id) throws IOException;
// 根据关键字检索数据
List<JobDetail> searchByKeywords(String keywords) throws IOException;
// 分页检索
Map<String, Object> searchByPage(String keywords, int pageNum, int pageSize) throws IOException;
// scroll分页解决深分页问题
Map<String, Object> searchByScrollPage(String keywords, String scrollId, int pageSize) throws IOException;
// 关闭ES连接
void close() throws IOException;
;
}
创建实现类
在
cn.itcast.elasticsearch.service.impl包下创建一个实现类:JobFullTextServiceImpl,并实现上面的接口。
参考代码:
public class JobFullTextServiceImpl implements JobFullTextService {
@Override
public void add(JobDetail jobDetail) {
}
@Override
public void update(JobDetail jobDetail) {
}
@Override
public JobDetail findById(long id) {
return null;
}
@Override
public boolean deleteById(long id) {
return false;
}
@Override
public List<JobDetail> searchByKeywords(String keywords) {
return null;
}
@Override
public Map<String, Object> searchByPage(String keywords, int pageNum, int pageSize) {
return null;
}
@Override
public Map<String, Object> searchByScrollPage(String keywords, String scrollId, int pageSize) {
return null;
}
}
添加职位数据
初始化客户端连接
1.使用RestHighLevelClient构建客户端连接。
2.基于RestClient.builder方法来构建RestClientBuilder
3.用HttpHost来添加ES的节点
参考代码:
private RestHighLevelClient restHighLevelClient;
private static final String JOB_IDX_NAME = “job_idx”;
public JobFullTextServiceImpl() {
restHighLevelClient = new RestHighLevelClient(RestClient.builder(
new HttpHost(“node1.itcast.cn”, 9200, “http”)
, new HttpHost(“node2.itcast.cn”, 9200, “http”)
, new HttpHost(“node3.itcast.cn”, 9200, “http”)
));
}
实现关闭客户端连接
@Override
public void close() {
try {
restHighLevelClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
编写代码实现新增职位数据
实现步骤:
1.构建IndexRequest对象,用来描述ES发起请求的数据。
2.设置文档ID。
3.使用FastJSON将实体类对象转换为JSON。
4.使用IndexRequest.source方法设置文档数据,并设置请求的数据为JSON格式。
5.使用ES High level client调用index方法发起请求,将一个文档添加到索引中。
参考代码:
@Override
public void add(JobDetail jobDetail) {
// 1. 构建IndexRequest对象,用来描述ES发起请求的数据。
IndexRequest indexRequest = new IndexRequest(JOB_IDX_NAME);
// 2. 设置文档ID。
indexRequest.id(jobDetail.getId() + “”);
// 3. 构建一个实体类对象,并使用FastJSON将实体类对象转换为JSON。
String json = JSON.toJSONString(jobDetail);
// 4. 使用IndexRequest.source方法设置请求数据。
indexRequest.source(json);
try {
// 5. 使用ES High level client调用index方法发起请求
restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
e.printStackTrace();
}
System.out.println(“索引创建成功!”);
}
常见错误:
java.lang.IllegalArgumentException: The number of object passed must be even but was [1]
at org.elasticsearch.action.index.IndexRequest.source(IndexRequest.java:474)
at org.elasticsearch.action.index.IndexRequest.source(IndexRequest.java:461)
缘由:IndexRequest.source要求传递偶数个的参数,但只传递了1个
编写测试用例测试添加方法
1.在 test/java 目录中创建一个
cn.itcast.elasticsearch.service 包。
2.在
cn.itcast.elasticsearch.service 包下创建一个JobFullTextServiceTest类。
3.在@BeforeTest中构建JobFullTextService对象,@AfterTest中调用close方法关闭连接。
4.编写测试用例,构建一个测试用的实体类,测试add方法。
参考代码:
public class JobFullTextServiceTest {
private JobFullTextService jobFullTextService;
@BeforeTest
public void beforeTest() {
jobFullTextService = new JobFullTextServiceImpl();
}
@Test
public void addTest() {
// 1. 测试新增索引文档
jobFullTextService = new JobFullTextServiceImpl();
JobDetail jobDetail = new JobDetail();
jobDetail.setId(1);
jobDetail.setArea(“江苏省-南京市”);
jobDetail.setCmp(“Elasticsearch大学”);
jobDetail.setEdu(“本科及以上”);
jobDetail.setExp(“一年工作经验”);
jobDetail.setTitle(“大数据工程师”);
jobDetail.setJob_type(“全职”);
jobDetail.setPv(“1700次浏览”);
jobDetail.setJd(“会Hadoop就行”);
jobDetail.setSalary(“5-9千/月”);
jobFullTextService.add(jobDetail);
}
@AfterTest
public void afterTest() {
jobFullTextService.close();
}
}
根据ID检索指定职位数据
实现步骤
1.构建GetRequest请求。
2.使用RestHighLevelClient.get发送GetRequest请求,并获取到ES服务器的响应。
3.将ES响应的数据转换为JSON字符串
4.并使用FastJSON将JSON字符串转换为JobDetail类对象
5.记得:单独设置ID
参考代码:
@Override
public JobDetail findById(long id) throws IOException {
// 1. 构建GetRequest请求。
GetRequest getRequest = new GetRequest(JOB_IDX_NAME, id + “”);
// 2. 使用RestHighLevelClient.get发送GetRequest请求,并获取到ES服务器的响应。
GetResponse response = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT);
// 3. 将ES响应的数据转换为JSON字符串
String json =
response.getSourceAsString();
// 4. 并使用FastJSON将JSON字符串转换为JobDetail类对象
JobDetail jobDetail = JSONObject.parseObject(json, JobDetail.class);
// 5. 设置ID字段
jobDetail.setId(id);
return jobDetail;
}
编写测试用例
参考代码:
@Test
public void findByIdTest() throws IOException {
JobDetail jobDetail = jobFullTextService.findById(1);
System.out.println(jobDetail);
}
修改职位
实现步骤
- 判断对应ID的文档是否存在
- 构建GetRequest执行client的exists方法,发起请求,判断是否存在
- 构建UpdateRequest请求
- 设置UpdateRequest的文档,并配置为JSON格式
- 执行client发起update请求
参考代码:
@Override
public void update(JobDetail jobDetail) throws IOException {
// 1. 判断对应ID的文档是否存在
// a) 构建GetRequest
GetRequest getRequest = new GetRequest(JOB_IDX_NAME, jobDetail.getId() + “”);
// b) 执行client的exists方法,发起请求,判断是否存在
boolean exists =
restHighLevelClient.exists(getRequest, RequestOptions.DEFAULT);
if(!exists) return;
// 2. 构建UpdateRequest请求
UpdateRequest updateRequest = new UpdateRequest(JOB_IDX_NAME, jobDetail.getId() + “”);
// 3. 设置UpdateRequest的文档,并配置为JSON格式
updateRequest.doc(JSON.toJSONString(jobDetail), XContentType.JSON);
// 4. 执行client发起update请求
restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT);
}
编写测试用例
1.将ID为1的职位信息查询出来
2.将职位的名称设置为:”大数据开发工程师”
3.执行更新操作
4.再打印查看职位的名称是否成功更新
参考代码:
@Test
public void updateTest() throws IOException {
JobDetail jobDetail =
jobFullTextService.findById(1);
jobDetail.setTitle(“大数据开发工程师”);
jobFullTextService.update(jobDetail);
System.out.println(
jobFullTextService.findById(1));
}
根据文档ID删除职位
实现步骤
1.构建delete请求
2.使用RestHighLevelClient执行delete请求
参考代码:
@Override
public void deleteById(long id) throws IOException {
// 1. 构建delete请求
DeleteRequest deleteRequest = new DeleteRequest(JOB_IDX_NAME, id + “”);
// 2. 使用client执行delete请求
restHighLevelClient.delete(deleteRequest, RequestOptions.DEFAULT);
}
编写测试用例
1.在测试用例中执行根据ID删除文档操作
2.使用VSCode发送请求,查看指定ID的文档是否已经被删除
参考代码:
@Test
public void deleteByIdTest() throws IOException {
jobFullTextService.deleteById(1);
}
根据关键字检索数据
实现步骤
- 构建SearchRequest检索请求
- 创建一个SearchSourceBuilder专门用于构建查询条件
- 使用QueryBuilders.multiMatchQuery构建一个查询条件(搜索title、jd),并配置到SearchSourceBuilder
- 调用SearchRequest.source将查询条件设置到检索请求
- 执行RestHighLevelClient.search发起请求
- 遍历结果
- 获取命中的结果将JSON字符串转换为对象使用SearchHit.getId设置文档ID
参考代码:
@Override
public List<JobDetail> searchByKeywords(String keywords) throws IOException {
// 1. 构建SearchRequest检索请求
SearchRequest searchRequest = new SearchRequest(JOB_IDX_NAME);
// 2. 创建一个SearchSourceBuilder专门用于构建查询条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 3. 使用
QueryBuilders.multiMatchQuery构建一个查询条件,并配置到SearchSourceBuilder
MultiMatchQueryBuilder queryBuilder =
QueryBuilders.multiMatchQuery(keywords, “jd”, “title”);
searchSourceBuilder.query(queryBuilder);
// 4. 调用SearchRequest.source将查询条件设置到检索请求
searchRequest.source(searchSourceBuilder);
// 5. 执行
RestHighLevelClient.search发起请求
SearchResponse searchResponse =
restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 6. 遍历结果
SearchHits hits = searchResponse.getHits();
List<JobDetail> jobDetailList = new ArrayList<>();
for (SearchHit hit : hits) {
// 1) 获取命中的结果
String json = hit.getSourceAsString();
// 2) 将JSON字符串转换为对象
JobDetail jobDetail = JSON.parseObject(json, JobDetail.class);
// 3) 使用SearchHit.getId设置文档ID
jobDetail.setId(Long.parseLong(hit.getId()));
jobDetailList.add(jobDetail);
}
return jobDetailList;
}
编写测试用例
搜索标题、职位描述中包含销售的职位。
@Test
public void searchByKeywordsTest() throws IOException {
List<JobDetail> jobDetailList =
jobFullTextService.searchByKeywords(“销售”);
for (JobDetail jobDetail : jobDetailList) {
System.out.println(jobDetail);
}
}
分页检索
实现步骤
步骤和之前的关键字搜索类似,只不过构建查询条件的时候,需要加上分页的设置。
- 构建SearchRequest检索请求
- 创建一个SearchSourceBuilder专门用于构建查询条件
- 使用QueryBuilders.multiMatchQuery构建一个查询条件,并配置到SearchSourceBuilder
- 设置SearchSourceBuilder的from和size参数,构建分页
- 调用SearchRequest.source将查询条件设置到检索请求
- 执行RestHighLevelClient.search发起请求
- 遍历结果
- 获取命中的结果将JSON字符串转换为对象使用SearchHit.getId设置文档ID
- 将结果封装到Map结构中(带有分页信息)
- total -> 使用SearchHits.getTotalHits().value获取到所有的记录数content -> 当前分页中的数据
@Override
public Map<String, Object> searchByPage(String keywords, int pageNum, int pageSize) throws IOException {
// 1. 构建SearchRequest检索请求
SearchRequest searchRequest = new SearchRequest(JOB_IDX_NAME);
// 2. 创建一个SearchSourceBuilder专门用于构建查询条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 3. 使用
QueryBuilders.multiMatchQuery构建一个查询条件,并配置到SearchSourceBuilder
MultiMatchQueryBuilder queryBuilder =
QueryBuilders.multiMatchQuery(keywords, “jd”, “title”);
searchSourceBuilder.query(queryBuilder);
// 4. 设置SearchSourceBuilder的from和size参数,构建分页
searchSourceBuilder.from((pageNum – 1) * pageSize);
searchSourceBuilder.size(pageSize);
// 4. 调用SearchRequest.source将查询条件设置到检索请求
searchRequest.source(searchSourceBuilder);
// 5. 执行
RestHighLevelClient.search发起请求
SearchResponse searchResponse =
restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 6. 遍历结果
SearchHits hits = searchResponse.getHits();
List<JobDetail> jobDetailList = new ArrayList<>();
for (SearchHit hit : hits) {
// 1) 获取命中的结果
String json = hit.getSourceAsString();
// 2) 将JSON字符串转换为对象
JobDetail jobDetail = JSON.parseObject(json, JobDetail.class);
// 3) 使用SearchHit.getId设置文档ID
jobDetail.setId(Long.parseLong(hit.getId()));
jobDetailList.add(jobDetail);
}
// 8. 将结果封装到Map结构中(带有分页信息)
// a) total -> 使用SearchHits.getTotalHits().value获取到所有的记录数
// b) content -> 当前分页中的数据
Map<String, Object> result = new HashMap<>();
result.put(“total”, hits.getTotalHits().value);
result.put(“content”, jobDetailList);
return result;
}
编写测试用例
1.搜索关键字为“销售”,查询第0页,每页显示10条数据
2.打印搜索结果总记录数、对应分页的记录
参考代码:
@Test
public void searchByPageTest() throws IOException {
Map<String, Object> resultMap =
jobFullTextService.searchByPage(“销售”, 0, 10);
System.out.println(“总共:” + resultMap.get(“total”));
List<JobDetail> jobDetailList = (List<JobDetail>)resultMap.get(“content”);
for (JobDetail jobDetail : jobDetailList) {
System.out.println(jobDetail);
}
}
scroll分页检索
实现步骤
判断scrollId是否为空
- 如果为空,那么首次查询要发起scroll查询,设置滚动快照的有效时间
- 如果不为空,就表明之前应发起了scroll,直接执行scroll查询就可以
步骤和之前的关键字搜索类似,只不过构建查询条件的时候,需要加上分页的设置。
scrollId为空:
- 构建SearchRequest检索请求
- 创建一个SearchSourceBuilder专门用于构建查询条件
- 使用QueryBuilders.multiMatchQuery构建一个查询条件,并配置到SearchSourceBuilder
- 调用SearchRequest.source将查询条件设置到检索请求
- 设置每页多少条记录,调用SearchRequest.scroll设置滚动快照有效时间
- 执行RestHighLevelClient.search发起请求
- 遍历结果
- 获取命中的结果将JSON字符串转换为对象使用SearchHit.getId设置文档ID
- 将结果封装到Map结构中(带有分页信息)
- scroll_id -> 从SearchResponse中调用getScrollId()方法获取scrollIdcontent -> 当前分页中的数据
scollId不为空:
- 用之前查询出来的scrollId,构建SearchScrollRequest请求
- 设置scroll查询结果的有效时间
- 使用RestHighLevelClient执行scroll请求
@Override
public Map<String, Object> searchByScrollPage(String keywords, String scrollId, int pageSize) {
Map<String, Object> result = new HashMap<>();
List<JobDetail> jobList = new ArrayList<>();
try {
SearchResponse searchResponse = null;
if(scrollId == null) {
// 1. 创建搜索请求
SearchRequest searchRequest = new SearchRequest(“job_idx”);
// 2. 构建查询条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(
QueryBuilders.multiMatchQuery(keywords, “title”, “jd”));
// 3. 设置分页大小
searchSourceBuilder.size(pageSize);
// 4. 设置查询条件、并设置滚动快照有效时间
searchRequest.source(searchSourceBuilder);
searchRequest.scroll(
TimeValue.timeValueMinutes(1));
// 5. 发起请求
searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
}
else {
SearchScrollRequest searchScrollRequest = new SearchScrollRequest(scrollId);
searchScrollRequest.scroll(
TimeValue.timeValueMinutes(1));
searchResponse = client.scroll(searchScrollRequest, RequestOptions.DEFAULT);
}
// 6. 迭代响应结果
SearchHits hits = searchResponse.getHits();
for (SearchHit hit : hits) {
JobDetail jobDetail = JSONObject.parseObject(hit.getSourceAsString(), JobDetail.class);
jobDetail.setId(Long.parseLong(hit.getId()));
jobList.add(jobDetail);
}
result.put(“content”, jobList);
result.put(“scroll_id”,
searchResponse.getScrollId());
}
catch (IOException e) {
e.printStackTrace();
}
return result;
}
编写测试用例
1.编写第一个测试用例,不带scrollId查询
2.编写第二个测试用例,使用scrollId查询
@Test
public void searchByScrollPageTest1() throws IOException {
Map<String, Object> result =
jobFullTextService.searchByScrollPage(“销售”, null, 10);
System.out.println(“scrollId: ” + result.get(“scrollId”));
List<JobDetail> content = (List<JobDetail>)result.get(“content”);
for (JobDetail jobDetail : content) {
System.out.println(jobDetail);
}
}
@Test
public void searchByScrollPageTest2() throws IOException {
Map<String, Object> result =
jobFullTextService.searchByScrollPage(“销售”, “
DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAA0WRG4zZFVwODJSU2Uxd1BOWkQ4cFdCQQ==”, 10);
System.out.println(“scrollId: ” + result.get(“scrollId”));
List<JobDetail> content = (List<JobDetail>)result.get(“content”);
for (JobDetail jobDetail : content) {
System.out.println(jobDetail);
}
}
高亮查询
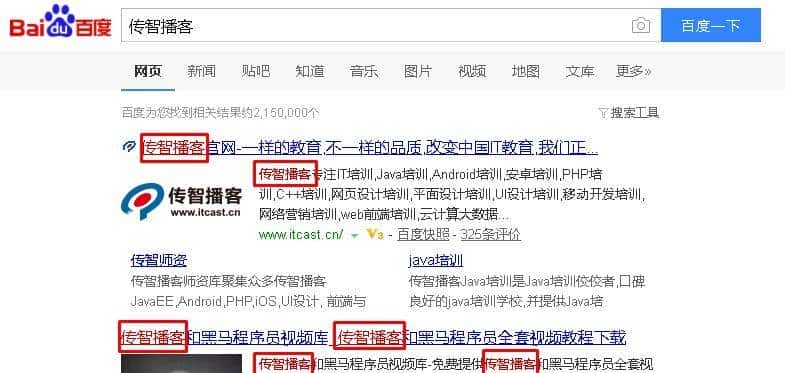
高亮查询简介
在进行关键字搜索时,搜索出的内容中的关键字会显示不同的颜色,称之为高亮。百度搜索关键字”传智播客”
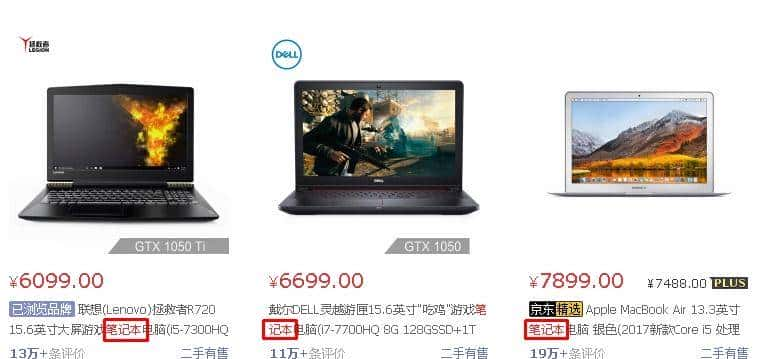
京东商城搜索”笔记本”
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...







