前言
考虑到大家期末课程作业或毕业设计等需要数据作为支撑,或者需要提交代码编程作业。本系列分别用三篇文章:京东、淘宝、拼多多数据爬取来讲述数据爬取过程,即便是python入门级小白也能掌握。本篇文章为拼多多爬取教程。(ps:拼多多爬取的坑在于拼多多把数据藏在html文件里面,得用正则匹配和处理数据)
一、安装&导入依赖库
(1)安装库
%pip install DrissionPage pandas openpyxl(2)导入依赖
# 爬虫库,使用谷歌模拟器
from DrissionPage import ChromiumPage
import re # 正则表达式库
import json # JSON解析库
import pandas as pd # 办公操作库
from datetime import datetime # 时间库说明:
DrissionPage
re
json
pandas
datetime
二、初始化浏览器并访问拼多多
创建浏览器实例并访问拼多多搜索页

driver = ChromiumPage()
driver.get('https://mobile.pinduoduo.com/relative_goods.html?__rp_name=search_view&source=index&options=3&shade_words=%E7%BA%B8%E5%B7%BE%E6%8A%BD%E7%BA%B8&ssr_histories=%5B%22%E9%AB%98%E6%A1%A3%E6%AD%A3%E5%93%81%E8%BD%BB%E8%96%84%E7%BE%BD%E7%BB%92%E6%9C%8D%22%5D&refer_page_name=index&refer_page_id=10002_1761990623118_tf6j8y73ut&refer_page_sn=10002')关键点:
实例化浏览器对象:创建
ChromiumPage
为什么访问移动版?
移动版页面结构更清晰数据加载方式更直接反爬机制相对较弱
三、启动网络请求监听
启动监听器
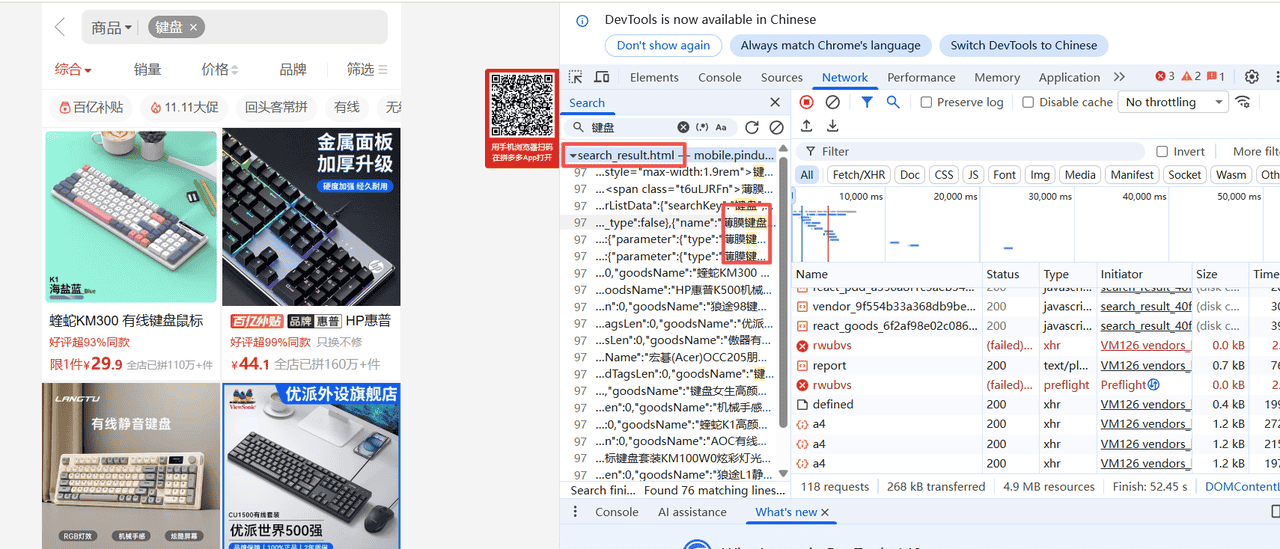
# 启动监听
driver.listen.start('search_result.html')监听原理:
拼多多在搜索时会请求
search_result.html
与淘宝监听的区别:
淘宝:监听JSON接口(
mtop.relationrecommend
search_result.html
四、模拟用户搜索操作
4.1 输入搜索关键词
driver.ele('css:form input[type="search"]').input('键盘')使用CSS选择器定位搜索框:
form input[type="search"]
4.2 点击搜索按钮
driver.ele('css:.RuSDrtii').click()使用CSS选择器定位搜索按钮(class名为
RuSDrtii
4.3 等待页面加载
driver.wait(3)等待3秒,确保搜索结果页面完全加载。
五、提取页面中的数据(核心技术)
5.1 初始化数据存储变量
# 定义变量来存储提取的数据
store_data = None
raw_data = None
product_list = []创建三个变量用于存储不同层级的数据:
raw_data
store_data
product_list
5.2 监听并获取HTML响应
for i, resp in enumerate(driver.listen.steps(count=1, timeout=15)):
if resp and resp.response.body:
html_content = resp.response.body
count=1
timeout=15
resp.response.body
5.3 使用正则表达式提取 window.rawData(关键步骤)
# 使用正则表达式提取window.rawData
pattern = r'window.rawDatas*=s*({.*?});'
match = re.search(pattern, html_content, re.DOTALL)这是拼多多爬虫的核心技术!
为什么需要正则表达式?
拼多多将数据嵌入在HTML页面的JavaScript代码中数据存储在
window.rawData
正则表达式详解:
window.rawData
.
s*=s*
({.*?})
{.*?}
()
re.DOTALL
.
5.4 解析JSON数据
if match:
raw_data_str = match.group(1)
try:
# 解析JSON数据并存储到raw_data变量
raw_data = json.loads(raw_data_str)
print("成功提取window.rawData并存储到raw_data变量")
match.group(1)
json.loads()
try-except
5.5 提取商品数据
# 提取stores.data中的数据并存储到store_data变量
if 'stores' in raw_data and 'store' in raw_data['stores']:
store_data = raw_data['stores']['store'].get('data', {})
print("成功提取data字段并存储到store_data变量")
# 打印store_data的内容
print("store_data内容:")
print(json.dumps(store_data, ensure_ascii=False, indent=2))
```
**数据结构层级:**
```
raw_data
└── stores
└── store
└── data (store_data)
└── ssrListData
└── items (product_list)逐层访问数据结构
json.dumps()
ensure_ascii=False
indent=2
5.6 提取商品列表
# 如果有商品列表,提取并存储到product_list变量
if 'ssrListData' in store_data and 'items' in store_data['ssrListData']:
product_list = store_data['ssrListData']['items']
print(f"成功提取商品列表,共{len(product_list)}个商品,存储到product_list变量")从
store_data
六、数据验证与输出
6.1 输出变量类型和内容摘要
# 现在您可以使用这些变量了
print("
=== 变量内容总结 ===")
print(f"raw_data类型: {type(raw_data)}")
print(f"store_data类型: {type(store_data)}")
print(f"product_list长度: {len(product_list)}")验证数据是否成功提取。
6.2 使用 store_data 变量
# 使用store_data变量
if store_data:
search_key = store_data.get('searchKey', '')
list_id = store_data.get('listID', '')
print(f"搜索关键词: {search_key}")
print(f"列表ID: {list_id}")获取搜索相关的元数据。
6.3 预览前几个商品
# 使用product_list变量
if product_list:
print("
前3个商品信息:")
for i, product in enumerate(product_list[:3]):
print(f"商品{i+1}: {product.get('goodsName', '未知商品')} - 价格: {product.get('groupPrice', '未知价格')}")快速预览数据,确认爬取成功。
七、解析商品详细信息
7.1 获取商品列表
goods_list = store_data['ssrListData']['list']
print(goods_list)从
store_data
list
items
7.2 提取所需字段
# 提取所需字段
extracted_data = []
for item in goods_list:
extracted_item = {
'商品名称': item.get('goodsName', ''),
'价格(分)': item.get('price', ''), # 原始价格,单位可能是分
'价格(元)': float(item.get('price', 0)) / 100 if item.get('price') else 0, # 转换为元
'显示价格': item.get('priceInfo', ''), # 格式化后的价格字符串
'销量提示': item.get('salesTip', ''),
'商品ID': item.get('goodsID', ''),
'推荐标题': item.get('recTitle', '')
}
extracted_data.append(extracted_item)字段说明:
商品名称
价格(分)
价格(元)
显示价格
销量提示
商品ID
推荐标题
价格处理技巧:
float(item.get('price', 0)) / 100 if item.get('price') else 0拼多多返回的价格是以分为单位的整数(如 9990 表示 99.90元)需要除以100转换为元使用三元表达式处理空值情况
八、导出为 Excel 文件
8.1 创建 DataFrame
# 创建DataFrame
df = pd.DataFrame(extracted_data)将数据列表转换为 pandas DataFrame。
8.2 生成带时间戳的文件名
# 保存为Excel文件
current_time = datetime.now().strftime("%Y%m%d_%H%M%S")
filename = f'pinduoduo_goods_data_{current_time}.xlsx'生成唯一文件名,格式如:
pinduoduo_goods_data_20241102_143025.xlsx
8.3 保存 Excel 文件
# 保存Excel文件
df.to_excel(filename, index=False, engine='openpyxl')
print(f"成功提取 {len(extracted_data)} 个商品信息")
print(f"已保存到文件: {filename}")
print("
数据预览:")
print(df)
index=False
engine='openpyxl'
最后:完整源码
封装函数
from DrissionPage import ChromiumPage
import re
import json
import pandas as pd
from datetime import datetime
def pinduoduo_crawler(keyword, max_products=20):
"""
拼多多商品爬虫函数
参数:
keyword: 搜索关键词
max_products: 最大爬取商品数量,默认20个
返回:
导出的Excel文件名
"""
# 实例化浏览器对象
driver = ChromiumPage()
try:
# 访问拼多多移动端页面
driver.get('https://mobile.pinduoduo.com/relative_goods.html?__rp_name=search_view&source=index&options=3&shade_words=%E7%BA%B8%E5%B7%BE%E6%8A%BD%E7%BA%B8&ssr_histories=%5B%22%E9%AB%98%E6%A1%A3%E6%AD%A3%E5%93%81%E8%BD%BB%E8%96%84%E7%BE%BD%E7%BB%92%E6%9C%8D%22%5D&refer_page_name=index&refer_page_id=10002_1761990623118_tf6j8y73ut&refer_page_sn=10002')
# 启动监听
driver.listen.start('search_result.html')
# 输入搜索关键词
search_input = driver.ele('css:form input[type="search"]')
if search_input:
search_input.input(keyword)
else:
print("未找到搜索框")
return None
# 点击搜索按钮
search_btn = driver.ele('css:.RuSDrtii')
if search_btn:
search_btn.click()
else:
print("未找到搜索按钮")
return None
driver.wait(3)
# 定义变量来存储提取的数据
store_data = None
raw_data = None
product_list = []
for i, resp in enumerate(driver.listen.steps(count=1, timeout=15)):
if resp and resp.response.body:
html_content = resp.response.body
# 使用正则表达式提取window.rawData
pattern = r'window.rawDatas*=s*({.*?});'
match = re.search(pattern, html_content, re.DOTALL)
if match:
raw_data_str = match.group(1)
try:
# 解析JSON数据并存储到raw_data变量
raw_data = json.loads(raw_data_str)
print("成功提取window.rawData")
# 提取stores.data中的数据并存储到store_data变量
if 'stores' in raw_data and 'store' in raw_data['stores']:
store_data = raw_data['stores']['store'].get('data', {})
print("成功提取data字段")
# 如果有商品列表,提取并存储到product_list变量
if 'ssrListData' in store_data and 'items' in store_data['ssrListData']:
product_list = store_data['ssrListData']['items']
print(f"成功提取商品列表,共{len(product_list)}个商品")
except json.JSONDecodeError as e:
print(f"JSON解析错误: {e}")
else:
print("未找到window.rawData")
# 提取商品数据
if store_data and 'ssrListData' in store_data and 'list' in store_data['ssrListData']:
goods_list = store_data['ssrListData']['list'][:max_products]
# 提取所需字段
extracted_data = []
for i, item in enumerate(goods_list, 1):
try:
extracted_item = {
'序号': i,
'商品名称': item.get('goodsName', ''),
'价格(分)': item.get('price', ''), # 原始价格,单位可能是分
'价格(元)': float(item.get('price', 0)) / 100 if item.get('price') else 0, # 转换为元
'显示价格': item.get('priceInfo', ''), # 格式化后的价格字符串
'销量提示': item.get('salesTip', ''),
'商品ID': item.get('goodsID', ''),
'推荐标题': item.get('recTitle', '')
}
extracted_data.append(extracted_item)
# 打印商品信息
print(f"{i}. {extracted_item['商品名称']}")
print(f" 价格: {extracted_item['价格(元)']}元 | 销量: {extracted_item['销量提示']}")
print("-" * 80)
except Exception as e:
print(f"处理第 {i} 个商品时出错: {e}")
continue
# 创建DataFrame并导出为Excel
if extracted_data:
df = pd.DataFrame(extracted_data)
# 生成文件名(包含关键词和时间戳)
current_time = datetime.now().strftime("%Y%m%d_%H%M%S")
filename = f'拼多多_{keyword}_商品数据_{current_time}.xlsx'
# 保存Excel文件
df.to_excel(filename, index=False, engine='openpyxl')
print(f"成功提取 {len(extracted_data)} 个商品信息")
print(f"已保存到文件: {filename}")
return filename
else:
print("未提取到任何商品数据")
return None
else:
print("未找到商品列表数据")
return None
except Exception as e:
print(f"爬取过程中出错: {e}")
return None
finally:
# 关闭浏览器
try:
driver.quit()
except:
pass
# 使用示例
if __name__ == "__main__":
# 只需输入关键词即可爬取
keyword = input("请输入要搜索的商品关键词: ")
result_file = pinduoduo_crawler(keyword)
if result_file:
print(f"爬取完成,数据已保存到: {result_file}")
else:
print("爬取失败,请检查网络连接或关键词是否正确")使用方法(注意:需要在打开的浏览器先手动登录)
# 爬取"键盘"相关的商品
result_file = pinduoduo_crawler("键盘")
# 爬取"手机"相关的商品,最多30个
result_file = pinduoduo_crawler("手机", max_products=30)输出数据效果

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...