小伙伴们!今天可不得了啊,阿里发布了全新的全模态大模型——“Qwen2.5-Omni-7B”。它能做各种各样的事情,不管是文字处理,图像生成还是语音交互,都能轻松搞定。
这标志着人工智能又向前迈进了一大步啊,以7B小尺寸实现端到端全模态交互能力,简直是AI界的“六边形战士”!
Qwen2.5-Omni是什么?
Qwen2.5-Omni是全球首个端到端开源全模态大模型,支持文本、图像、音频、视频的实时输入与输出,实现“看听说写”一体化交互。其核心能力包括:

划重点:传统多模态方案需串联ASR(语音识别)、TTS(语音合成)等独立模型,而Qwen2.5-Omni通过统一架构直接原生处理多模态数据,效率提升显著。
二、如何快速部署?
开发者三步上手:
下载渠道:开源平台:Hugging Face、魔搭社区(ModelScope)、GitHub同步开源。
本地部署:手机端:7B小参数适配移动设备,手机等终端智能硬件也可轻松部署运行。另外,用户也可在Qwen Chat上直接体验。
三、技术优势解析
Qwen2.5-Omni的三大杀手锏:
- Thinker-Talker双核架构:
- Thinker(大脑):整合多模态信息,生成高级语义表征(如解析视频中的画面、对话、背景音乐)。
- Talker(发声器):流式生成语音token,实现“边思考边说话”。
- TMRoPE位置编码:
创新性地将视频与音频时间戳对齐,解决多模态时序同步难题,提升音画一致性。 - 性能碾压闭源模型:多模态基准测试:OmniBench、MMMU、MVBench等任务超越Google Gemini-1.5-Pro。
- 语音生成:主观评测分数4.51(满分5分),接近人类水平。
四、体验与未来展望
目前,Qwen2.5-Omni已在教育、客服、智能硬件等领域展现潜力。例如:
- 实时翻译会议视频:直接输出多语言语音摘要。
- 盲人辅助工具:通过语音描述实时解析环境画面。
立即体验:
- 在线Demo:https://modelscope.cn/studios/Qwen/Qwen2.5-Omni-Demo
- 开源代码:https://github.com/QwenLM/Qwen2.5-Omni
行业评价:“这才是真正的Open AI!”。阿里通过开源全模态技术,或将推动AI应用进入“类人交互”新时代!
Qwen Chat免费体验:
https://chat.qwenlm.ai
百炼平台模型调用:
https://help.aliyun.com/zh/model-studio/user-guide/qwen-omni
Demo体验:
https://modelscope.cn/studios/Qwen/Qwen2.5-Omni-Demo
开源地址:
https://huggingface.co/Qwen/Qwen2.5-Omni-7B
https://modelscope.cn/models/Qwen/Qwen2.5-Omni-7B
https://github.com/QwenLM/Qwen2.5-Omni

官方介绍介绍
Qwen2.5-Omni 是一个端到端的多模态模型,旨在感知各种模态,包括文本、图像、音频和视频,同时以流式方式生成文本和自然语音响应。
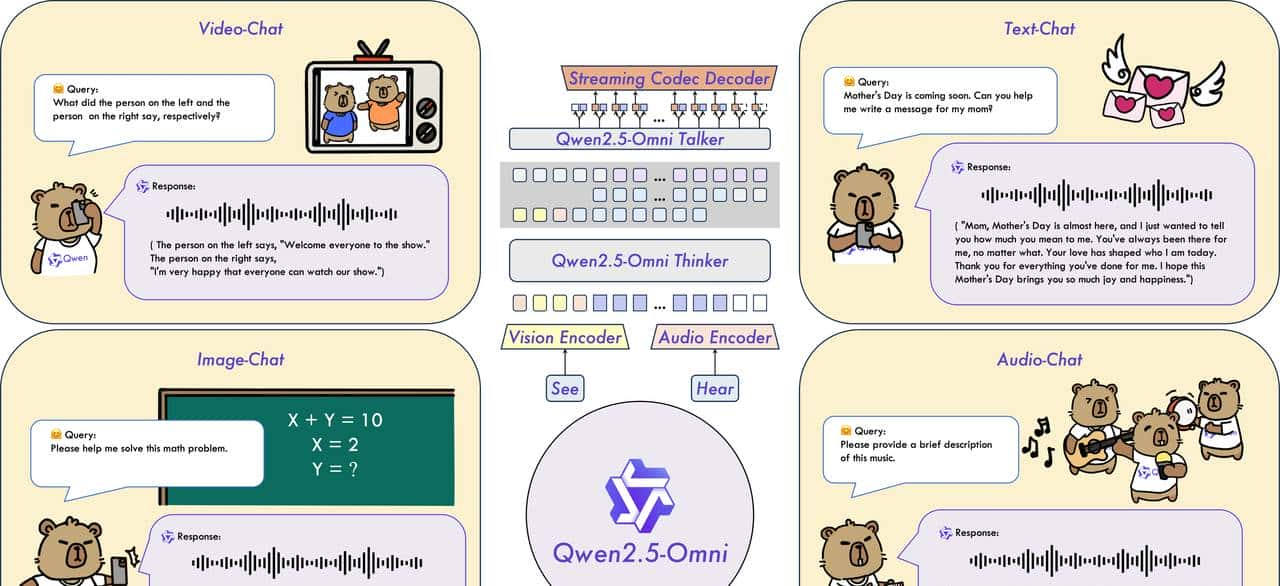
主要特点
- Omni 和 Novel Architecture:提出了 Thinker-Talker 架构,这是一种端到端的多模态模型,旨在感知不同的模态,包括文本、图像、音频和视频,同时以流式方式生成文本和自然语音响应。我们提出了一种名为 TMRoPE (Time-aligned Multimodal RoPE) 的新型位置嵌入,以将视频输入的时间戳与音频同步。
- 实时语音和视频聊天:架构专为完全实时交互而设计,支持分块输入和即时输出。
- 自不过稳健的语音生成:超越许多现有的流媒体和非流媒体替代方案,在语音生成方面表现出卓越的稳健性和自然性。
- 跨模态的强劲性能:与类似大小的单模态模型进行基准测试时,在所有模态中都表现出卓越的性能。Qwen2.5-Omni 在音频功能方面优于类似尺寸的 Qwen2-Audio,并实现了与 Qwen2.5-VL-7B 相当的性能。
- 出色的端到端语音教学如下: Qwen2.5-Omni 在端到端语音教学跟踪方面的性能可与文本输入的有效性相媲美,MMLU 和 GSM8K 等基准测试证明了这一点。
模型架构
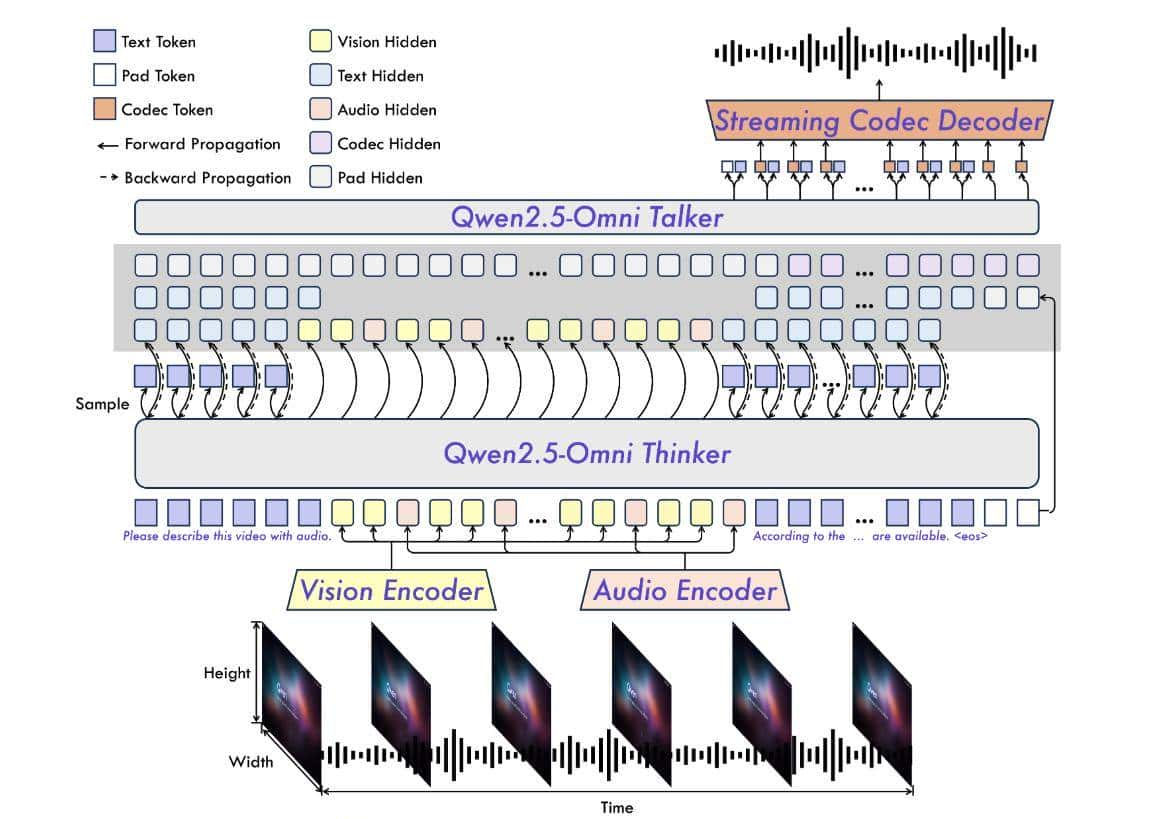
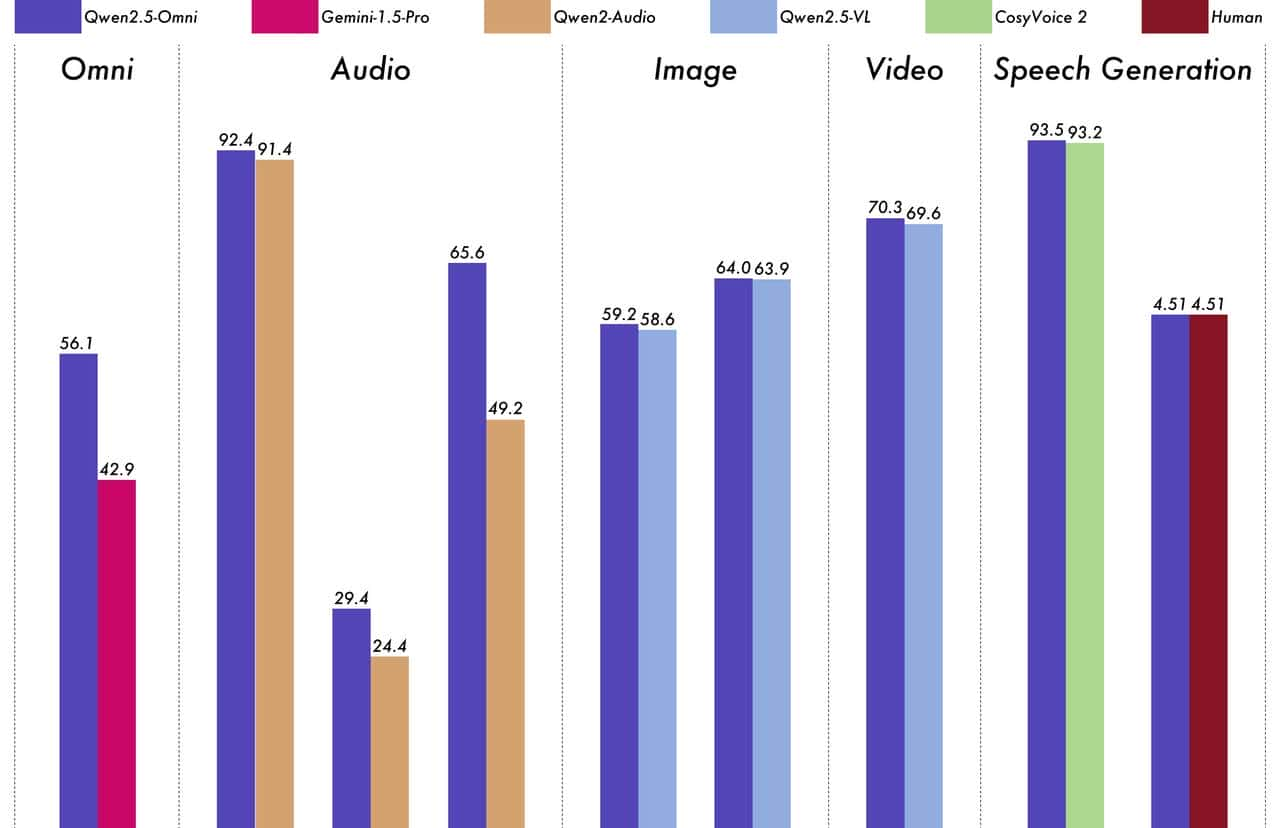
性能
Qwen2.5-Omni 与类似大小的单模态模型和闭源模型(如 Qwen2.5-VL-7B、Qwen2-Audio 和 Gemini-1.5-pro)相比,它在所有模态中都表现出强劲的性能。此外,在单模态任务中,它在语音识别 (Common Voice)、翻译 (CoVoST2)、音频理解 (MMAU)、图像推理 (MMMU、MMStar)、视频理解 (MVBench) 和语音生成 (Seed-tts-eval 和 Subjective naturalness) 等领域表现出色。
使用 vLLM 进行部署
提议使用 vLLM 进行快速 Qwen2.5-Omni 部署和推理。您需要从github下载源代码进行安装,以获得对 Qwen2.5-Omni 的 vLLM 支持,或使用的官方 docker 镜像。还可以查看 vLLM 官方文档,了解有关在线服务和离线推理的更多详细信息。
安装
pip install git+https://github.com/huggingface/transformers@1d04f0d44251be5e236484f8c8a00e1c7aa69022
pip install accelerate
pip install qwen-omni-utils
git clone -b qwen2_omni_public_v1 https://github.com/fyabc/vllm.git
cd vllm
pip install .本地推理
你可以使用 vLLM 在本地推理 Qwen2.5-Omni,目前只支持 vllm 中的 thinker 部分,因此 model 的输出只能是文本。我们将在不久的将来支持模型的其他部分实现音频输出。
import os
import torch
from transformers import Qwen2_5OmniProcessor
from vllm import LLM, SamplingParams
from qwen_omni_utils import process_mm_info
# vLLM engine v1 not supported yet
os.environ['VLLM_USE_V1'] = '0'
MODEL_PATH = "Qwen/Qwen2.5-Omni-7B"
llm = LLM(
model=MODEL_PATH, trust_remote_code=True, gpu_memory_utilization=0.9,
tensor_parallel_size=torch.cuda.device_count(),
limit_mm_per_prompt={'image': 1, 'video': 1, 'audio': 1},
seed=1234,
)
sampling_params = SamplingParams(
temperature=1e-6,
max_tokens=512,
)
processor = Qwen2_5OmniProcessor.from_pretrained(MODEL_PATH)
messages = [
{
"role": "system",
"content": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech.",
},
{
"role": "user",
"content": [
{"type": "video", "video": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-Omni/draw.mp4"},
],
},
]
text = processor.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
audios, images, videos = process_mm_info(messages, use_audio_in_video=True)
inputs = {
'prompt': text[0],
'multi_modal_data': {},
"mm_processor_kwargs": {
"use_audio_in_video": True,
},
}
if images is not None:
inputs['multi_modal_data']['image'] = images
if videos is not None:
inputs['multi_modal_data']['video'] = videos
if audios is not None:
inputs['multi_modal_data']['audio'] = audios
outputs = llm.generate(inputs, sampling_params=sampling_params)
print(outputs[0].outputs[0].text)官方还在 vLLM 存储库中提供了一些示例:
# vLLM engine v1 not supported yet
export VLLM_USE_V1=0
cd vllm
python examples/offline_inference/audio_language.py --model-type qwen2_5_omni
python examples/offline_inference/vision_language.py --modality image --model-type qwen2_5_omni
python examples/offline_inference/vision_language.py --modality video --model-type qwen2_5_omni码头工人
为了简化部署过程,官方提供了带有预构建环境的 docker 镜像:qwenllm/qwen-omni。您只需安装驱动并下载模型文件即可启动 Demo。
docker run --gpus all --ipc=host --network=host --rm --name qwen2.5-omni -it qwenllm/qwen-omni:2.5-cu121 bash您还可以通过以下方式启动 Web 演示:
bash docker/docker_web_demo.sh --checkpoint /path/to/Qwen2.5-Omni-7B要启用 FlashAttention-2,请使用以下命令:
bash docker/docker_web_demo.sh --checkpoint /path/to/Qwen2.5-Omni-7B --flash-attn2© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


您必须登录才能参与评论!
立即登录






4090显卡,跑了下,巨慢无比,而且还开了flashattention,同样是7b,qwen2.5-audio比他快多了
可以识别声音里面的特征吗,比如特定的噪声
只用cpu可以跑吗?
手机到底怎么部署?不能光吹不练啊!
收藏了,感谢分享