你是不是也觉得,系统一出问题,第一反应就是去查日志?

查完一堆指标,还是不知道到底哪出了岔子。

别骗自己了,光靠看图、设告警,早就不够用了。
去年我负责的系统在大促前夜突然抖动,Prometheus的内存直接爆了——不是数据多,是指标太细,每秒上万的延迟采样,像在用显微镜看整个宇宙。
后来升级到v2.40的NativeHistograms,内存直接砍掉九成,那感觉,像从扛沙袋变成了开卡车。
你以为这是技术升级?
不,这是生存方式的切换。
目前谁还敢靠人工盯屏?
OpenTelemetry成了默认配置,不是由于它多牛,而是由于你没得选。
Jaeger、SkyWalking全接进去了,链路一拉,从用户点击到数据库慢查询,全在一张图上,连中间哪个微服务偷偷多睡了0.3秒都看得清。
以前是“出了事再找人”,目前是“还没出事,系统已经知道谁该背锅”。
阿里云的Sentinel2.0,自动调限流阈值,误杀率从15%降到3%,听起来像算法奇迹。

可你知道吗?
那12%的误杀,曾经是客服电话被打爆的根源。
客户说“你们系统卡”,实则不是卡,是系统怕崩,自己先把自己掐死了。
目前它懂了:流量不是敌人,恐惧才是。
微软的Resilience4j 2.0,解决了熔断器集群状态不一致的坑。
这事儿有多致命?
你一个服务在A区熔断了,B区还在狂冲,结果整个集群被拖垮。
以前靠人工同步,目前自动同步,像两个打架的人,突然被拉开了,还给每人配了翻译。
华为的DTS3.0,敢在同一个事务里混用TCC和SAGA,听着像技术炫技,实则是现实妥协。
你不可能让所有老系统重写,也不可能让新系统全用最优雅的方案。
它不告知你该怎么做,它只是说:你有烂摊子,我帮你兜住。
最狠的是腾讯的混沌工程平台,能模拟10万QPS突袭微信支付。
你以为你在测试系统?
不,你在测试人性。
多少团队把“容灾演练”当表演,演完就收工。
可当真实流量像海啸一样砸下来,你才知道,预案写得再美丽,不如一次真刀真枪的“被揍”。
我们总说要“预防式运维”,可真正落地的,不是AI预测准确率89%,而是有人敢在凌晨三点,主动把系统搞崩一次。
不是为了证明自己牛,是为了确认:如果明天真崩了,我们是不是还来得及。
Seata 2.0把事务恢复从分钟级缩到秒级,听起来是优化,实则是尊严。
没人想在客户投诉时,对着屏幕说“我们在排查”。
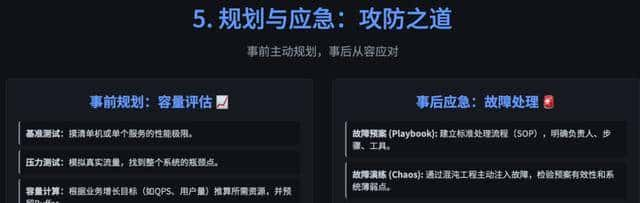
你得让系统自己把伤口缝好,再轻声告知你:没事了。
AIOps不是取代人,是把人从重复的“找茬”里解放出来。
你不需要再半夜爬起来看图,你只需要判断:这个告警,是系统在报警,还是它在撒谎。
技术越先进,越要有人味。
不是所有问题都能被算法解决,但所有问题,都值得被理解。
你不是在维护系统,你是在和一群沉默的程序,共同维持着千万人的信任。
而这份信任,从来不是靠工具堆出来的。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...