
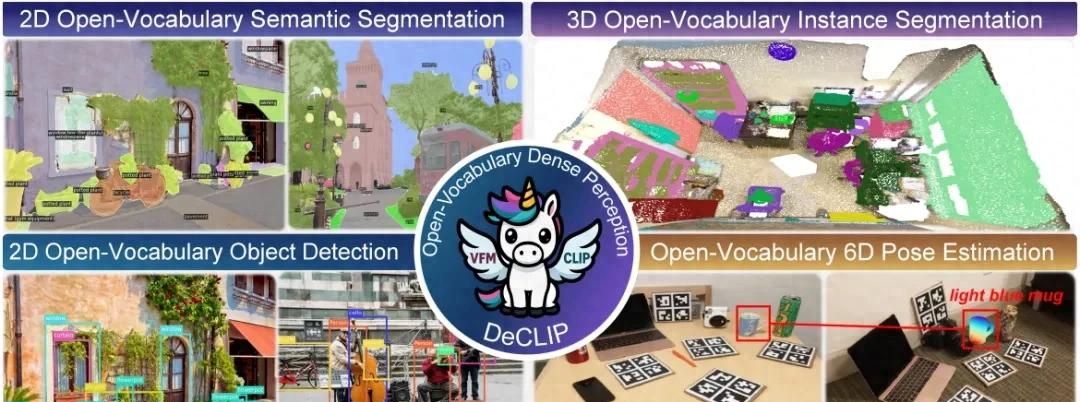
面向2D检测、3D分割、6D姿态估计的通用基础模型
基础模型已经改变了计算机视觉领域:CLIP 首次将图像与文本连接起来,DINO 擅长捕捉语义结构,SAM 提供准确的分割掩码。
视觉领域需求更广泛的任务是稠密视觉预测,如 2D 检测和分割、3D 实例分割、视频实例分割和 6D 物体姿态估计等。同时为了应对现实场景中视觉概念无界的挑战,以语言-图像预训练的CLIP,成为开放词汇场景的最优解决方案。
但之前的文章也提到过,CLIP虽在图像分类任务上的泛化能力好,但是在稠密预测任务中效果不好。那是什么阻碍了CLIP在稠密感知中的表现?
一、解密CLIP在稠密感知任务为何表现差!
这个思路也是我们去排查模型问题的常见手段:从网络各层的注意力图去排查分析!CLIP 使用 [CLS] token 来表征整幅图像的总体特征,并据此执行图像-文本对比学习,接下来我们看看CLIP的各层发生了什么。

从浅层可以看到 [CLS] token 会全面关注所有图像 token,以获得全局视图,从而提升图像分类效果。
出乎意料的是,从第 7 层开始,[CLS] token 不再聚焦于图像中的主要目标,而是将注意力转向背景中的若干图像 token,如上图的第一行所示。这些特定的背景 token 在随后的编码层中持续获得 [CLS] token 的显著关注。
我们再来看下第二行图像 token 的注意力图,第一随机选取位于图像主要目标上的图像 token 作为锚点 token,在第 1–6 层的注意力主要分布在所属目标区域。不过,从第 7 层开始(即 [CLS] token 将注意力转向背景中特定 token 的同一时刻),锚点 token 也开始高度关注这些特定 token。
同样的现象发生在其他 token 中,这表明该现象并非局限于某一特定图像 token,而是在 CLIP 的所有图像 token 中普遍存在。
上述发现揭示了 CLIP 在稠密预测任务中表现不佳的缘由:其图像 token 无法聚合空间或语义相关区域的信息,导致稠密特征缺乏局部判别力和空间一致性。
二、面向开放词汇稠密感知的解耦学习
直接在 COCO 数据集上使用 CLIP 特征进行开放词汇区域分类和语义分割,性能相对较差。
一个直观的解决方案是通过微调增强 CLIP 的局部表征,现有工作主要思考通过低成本策略建立区域–文本对齐:一个是以整幅图像作为伪区域,但是会丢失细节;另一个是在图像块上进行自蒸馏,虽能获得更细粒度的信息,但仍无法应用于像素级图像分割。
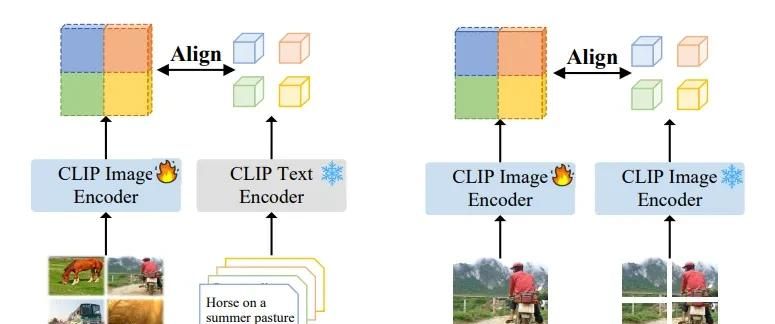
在统一架构内同时优化局部特征空间相关性和视觉–语言语义对齐两者存在冲突。那么,是否可以在统一架构内解耦 CLIP 特征,并施加不同的引导约束以获得多样化特征?
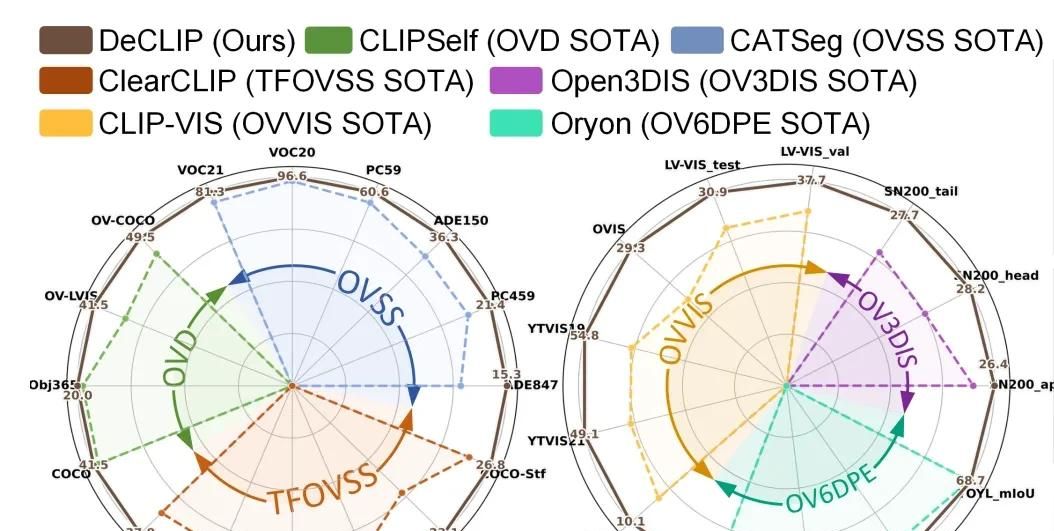
CVPR2025上哈工大及中科大提出 DeCLIP 在多个开放词汇稠密预测任务(包括目标检测和语义分割)上显著优于其他方法。
具体的,是一种简单有效的无监督微调框架,通过解耦自注意力模块分别获取“内容”和“上下文”特征的新框架。“内容”特征与图像裁剪表征对齐,以提升局部判别力;“上下文”特征则在视觉基础模型(如 DINO)指导下学习保留空间相关性。

选取位于图像主要目标上的图像 token 作为锚点 token,各种不同模型的特征注意力图效果如上。
开放词汇稠密预测旨在利用文本描述对新颖类别进行目标检测与分割,超越模型在基础类别上的训练范围。特征解耦后再分别蒸馏,让CLIP可适配到稠密预测任务。详细内容请查看论文及源码:
# 论文
https://arxiv.org/pdf/2505.04410
# 代码
https://github.com/xiaomoguhz/DeCLIP最后,关注视觉大模型与多模态大模型的小伙伴们可留言区回复‘加群’进入大模型交流群、视觉应用落地交流群!
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...






