
一、多模态通用架构

二、多模态模型是如何工作的
尽管多模态模型的架构各不一样,但大多数框架都包含几个标准组件。一个典型的架构一般由编码器(encoder)、融合机制(fusion mechanism)和解码器(decoder)组成。
其中,“encoder”(编码器)的作用是对单一模态数据(如图像、文本)进行处理,提取关键特征;“fusion mechanism”(融合机制)对应之前提到的 “connector” 核心功能,负责将不同模态的特征对齐并整合;“decoder”(解码器)则根据融合后的特征,生成目标输出(如文字描述、图像等)。

1. Encoders
编码器会将原始多模态数据转换为机器可读取的特征向量或嵌入(embeddings),这些向量或嵌入会作为模型的输入,协助模型理解数据所包含的内容。
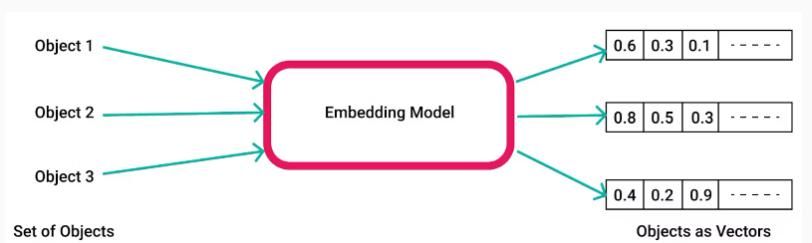
多模态模型一般为图像、文本和音频这三种数据类型,分别配备对应的编码器。
- 图像编码器(Image Encoders):卷积神经网络(Convolutional neural networks, CNNs)是图像编码器的常用选择。它能将图像像素转换为特征向量,协助模型理解图像的关键属性。
- 文本编码器(Text Encoders):文本编码器会将文本描述转换为嵌入(embeddings),供模型进行后续处理。这类编码器常采用 Transformer 模型,例如生成式预训练 Transformer(Generative Pre-Trained Transformer, GPT)框架中的相关模型。
- 音频编码器(Audio Encoders):音频编码器可将原始音频文件转换为可用的特征向量,捕捉音频的关键模式,包括节奏、音调与语境。Wav2Vec2 是用于学习音频表明的热门选择。
2. 融合机制策略
编码器将多种模态转换为嵌入后,下一步是将它们组合起来,以便模型理解所有数据类型所反映的更广泛语境。开发者可根据具体用例采用不同的融合策略。
以下列出了主要的融合策略:
- 早期融合(Early Fusion):将所有模态组合后,再传入模型进行处理。
- 中间融合(Intermediate Fusion):将每种模态映射到潜在空间,然后融合这些潜在表明以进行后续处理。
- 晚期融合(Late Fusion):对所有模态的原始形式进行处理,再融合各自的输出。
- 混合融合(Hybrid Fusion):在模型不同处理阶段,结合早期、中间和晚期融合策略。
3. 基于注意力的方法(Attention-based Methods)
基于注意力的方法采用 Transformer 架构,将多种模态的嵌入转换为查询 – 键 – 值(query-key-value)结构。该技术源自 2017 年发表的开创性论文《Attention is All You Need》(《注意力就是一切》)。
研究人员最初将该方法用于改善语言模型,由于注意力网络能让这些模型拥有更长的上下文窗口。如今,开发者已将其应用于其他领域,包括计算机视觉(CV)和生成式人工智能(generative AI)。
注意力网络可协助模型理解嵌入之间的关系,实现上下文感知处理。跨模态注意力框架会根据每种数据类型之间的相互关系,在多模态语境中融合不同模态。
例如,注意力过滤器能让模型识别文本提示的哪些部分与图像的视觉嵌入相关,从而生成更高效的融合输出。
4. 拼接(Concatenation)
拼接是一种简单直接的融合技术,可将多个嵌入合并为单一特征表明。
例如,该方法会将文本嵌入与视觉特征向量拼接,生成统一的多模态特征。
在中间融合策略中,该方法通过合并每种模态的潜在表明发挥作用。
5. 点积(Dot-Product)
点积方法是对不同模态的特征向量进行按元素乘法运算。它有助于捕捉模态间的交互作用与相关性,协助模型理解不同数据类型之间的共性。
但该方法仅在特征向量无高维问题时有效。对高维向量进行点积运算可能需要大量计算资源,且生成的特征仅能捕捉模态间的共同模式,而忽略关键差异。
6. 解码器(Decoders)
最后一个组件是解码器网络,它会处理来自不同模态的特征向量,以生成所需输出。
解码器可包含跨模态注意力网络,聚焦于输入数据的不同部分并生成相关输出。例如,翻译模型常采用跨注意力技术,同时理解不同语言句子的含义。
循环神经网络(RNN)、卷积神经网络(CNN)和生成对抗网络(GAN)框架是构建解码器的常用选择,可用于执行涉及序列、视觉或生成过程的任务。
三、模型介绍
1. CLIP
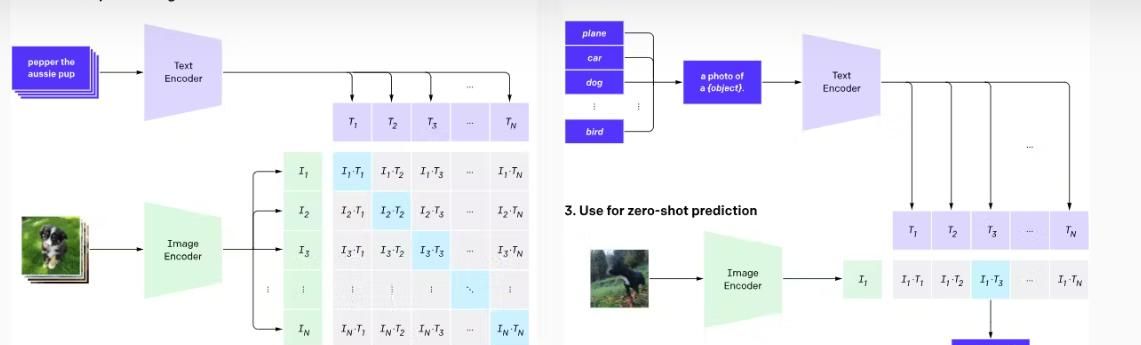
对比语言 – 图像预训练模型(Contrastive Language-Image Pre-training, CLIP)是 OpenAI 开发的一款多模态视觉 – 语言模型,主要用于执行图像分类任务。它会将文本数据聚焦的描述与对应的图像进行配对,进而生成相关的图像标签。
1.1 核心特点
- 对比框架(Contrastive Framework):CLIP 采用对比损失函数(contrastive loss function)优化其学习目标。该方法通过将相关文本描述与关联图像进行匹配,最小化距离函数,协助模型判断哪种文本最能描述图像内容。
- 文本与图像编码器(Text and Image Encoders):该架构使用基于 Transformer 的文本编码器,并将视觉 Transformer(Vision Transformer, ViT)用作图像编码器。
- 零样本能力(Zero-shot Capability):CLIP 在学会将文本与图像关联后,无需针对特定任务进行微调,就能快速泛化到新数据,并为未见过的新图像生成相关描述。
1.2 应用场景
凭借 CLIP 的多功能性,它可协助用户完成多项任务,例如用于创建训练数据的图像标注、用于基于人工智能的搜索系统的图像检索,以及根据图像提示生成文本描述。
2. DALL-E
DALL-E 是 OpenAI 开发的一款生成式模型,它采用与 GPT-3 类似的框架,能根据文本提示生成图像。该模型可将不相关的概念结合起来,生成包含物体、动物和文字的独特图像。

2.1 核心特点
- 基于 CLIP 的架构(CLIP-based architecture):DALL-E 将 CLIP 模型用作先验(prior),以建立文本描述与视觉语义的关联。该方法能协助 DALL-E 将文本提示编码为潜在空间中对应的视觉表明。
- 扩散解码器(A Diffusion Decoder):DALL-E 中的解码器模块采用扩散机制(diffusion mechanism),以文本描述为条件生成图像。
- 更大的上下文窗口(Larger Context Window):DALL-E 是一个拥有 120 亿参数的模型,可处理包含多达 1280 个令牌(tokens)的文本和图像数据流。这一能力使其既能从零开始生成图像,也能对现有图像进行编辑。
2.2 应用场景
DALL-E 可协助生成抽象图像,并对现有图像进行修改。这一功能既能让企业将新产品构想可视化,也能协助学生理解复杂的视觉概念。
3. LLaVA
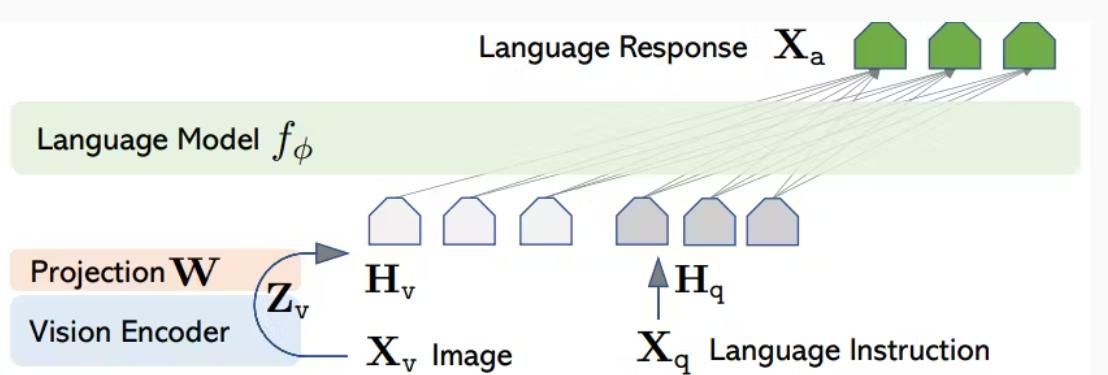
大型语言视觉助手(Large Language and Vision Assistant, LLaVA)是一款开源的大型多模态模型,它结合了 Vicuna 模型与 CLIP 模型,能够处理包含图像和文本的查询并给出回答。该模型在对话相关任务中实现了当前最优(SOTA)性能,在 Science QA 数据集上的准确率达到 92.53%。
3.1 核心特点
- 多模态指令遵循数据(Multimodal Instruction-following Data):该模型使用由 ChatGPT/GPT-4 生成的指令遵循文本数据来训练 LLaVA。这些数据包含关于视觉内容的问题,以及以对话、描述和复杂推理形式呈现的回答。
- 语言解码器(Language Decoder):LLaVA 将 Vicuna 作为语言解码器,与 CLIP 相结合,在指令遵循数据集上对模型进行微调。
- 可训练投影矩阵(Trainable Project Matrix):该模型采用一个可训练的投影矩阵,将视觉表明映射到语言嵌入空间中。
3.2 应用场景
LLaVA 是一款功能强劲的视觉助手,可协助用户为多个领域创建高级聊天机器人。例如,LLaVA 能助力开发电商网站的聊天机器人,用户可上传某件商品的图片,然后让该机器人在整个网站中搜索类似商品。
4. CogVLM
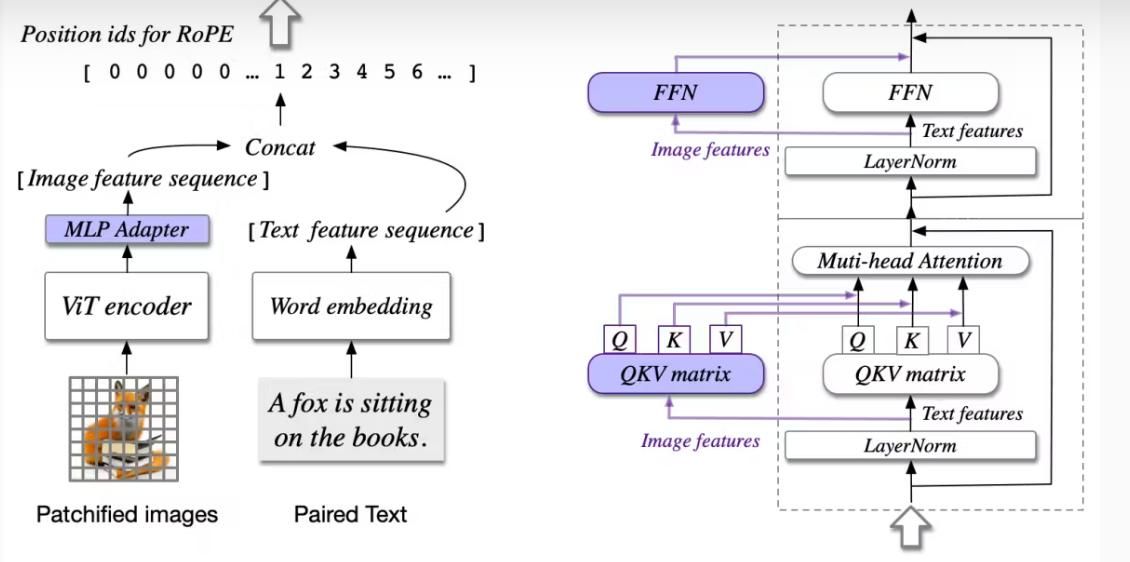
认知视觉语言模型(Cognitive Visual Language Model, CogVLM)是一款开源视觉语言基础模型,它采用深度融合技术,以实现更出色的视觉与语言理解能力。该模型在 17 个跨模态基准测试(包括图像描述生成和视觉问答(VQA)数据集)中均取得了当前最优(SOTA)性能。
4.1 核心特点
- 基于注意力的融合(Attention-based Fusion):该模型采用包含注意力层的视觉专家模块(visual expert module),对文本与图像嵌入进行融合。此技术通过冻结大语言模型(LLM)的层,来保留其性能。
- 视觉 Transformer(ViT)编码器:它使用 EVA2-CLIP-E 作为视觉编码器,并借助多层感知器(multi-layer perceptron, MLP)适配器,将视觉特征映射到与文本特征一样的空间中。
- 预训练大语言模型(Pre-trained Large Language Model, LLM):CogVLM 17B 版本采用 Vicuna 1.5-7B 作为大语言模型,用于将文本特征转换为词嵌入(word embeddings)。
4.1 应用场景
与 LLaVA 类似,CogVLM 可协助用户执行视觉问答(VQA)任务,并根据视觉线索生成详细的文本描述。它还能辅助视觉定位任务 —— 这类任务需要根据自然语言查询,识别图像中最相关的物体。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...






