简介
在数据驱动的时代,企业对实时数据处理的需求日益增长,传统批处理模式已难以满足快速决策的要求。实时计算平台能够高效处理流式数据,实现秒级分析、告警与响应,支撑风控、监控、用户行为分析等核心业务。一个完善的实时计算平台不仅提升数据处理能力,还能降低运维成本,优化资源利用,助力企业在激烈竞争中保持灵敏与领先。
Dinky是一款开箱即用、易扩展的一站式实时计算平台,基于 Apache Flink 构建,支持连接OLAP、数据湖、数据仓库等多个框架。它致力于解决流批一体化和湖仓一体化的建设与实践难题,简化Flink任务开发,提升Flink任务运维能力,降低Flink入门成本,提供一站式的Flink任务开发、运维、监控、报警、调度、数据管理等功能,为企业提供实时高效的数据处理能力,协助实时分析、决策和优化业务流程。

核心特点
1、实时计算 IDE:提供轻量级的实时计算 IDE 开发模式,支持代码提示补全、查询调试、逻辑检查、计划查看、血缘分析、全局变量、环境复用、整库同步、版本控制、元数据查询等能力,致力于解决作业数量大、开发成本高、调试门槛高等问题,让作业开发更简单高效。

2、实时运维管理:持 Apache Flink 所有的部署模式运维,运维中心提供作业运行信息、集群日志、血缘分析、CheckPoint和 SavePoint状态查看与恢复、版本信息、告警规则配置、Metrics可视化分析等。

3、开箱即用:屏蔽技术细节,实现 Flink 所有作业部署模式,自动托管作业状态,实时监控报警
4、语法增强:扩展 FlinkSQL 语法,如全局变量、环境复用、整库同步、打印表、执行 Jar 任务等
5、易于扩展:多种设计模式支持快速扩展新功能,如数据源、报警方式、整库同步、自定义语法等
6、无侵入性:Spring Boot 轻应用快速部署,不需要在 Flink 集群修改源码或添加额外插件,即装即用
7、成熟社区:已有百家企业在生产环境中使用,进行实时数据开发与作业托管,大量用户实践保障项目日渐成熟
功能展示
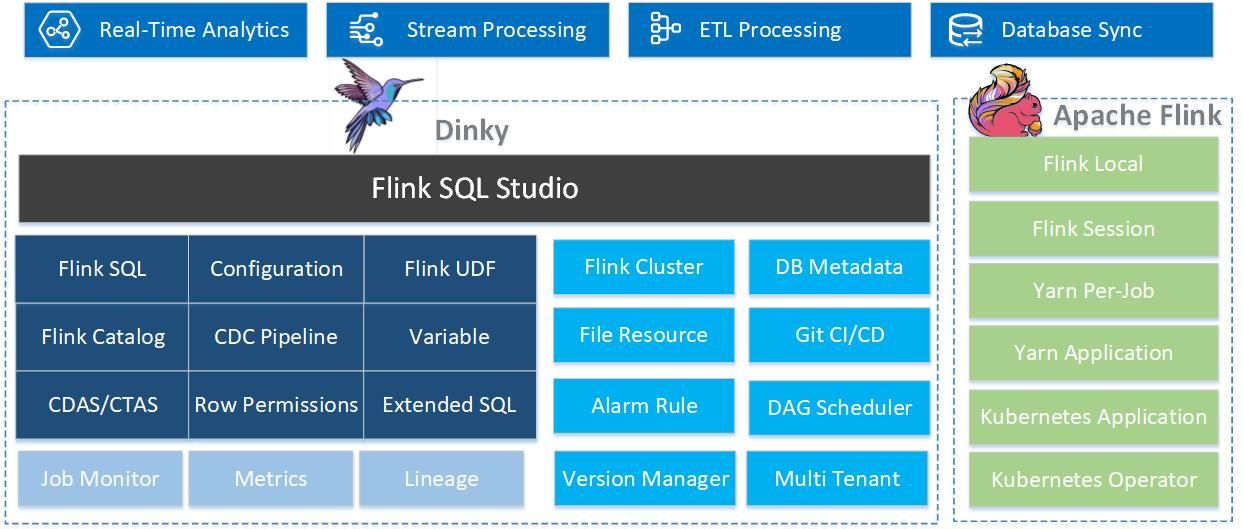




功能列表
- 沉浸式 FlinkSQL 数据开发 提供自动提示补全、语法高亮、语句美化、在线调试、语法校验、执行计划、Catalog 支持、血缘分析等功能,提升开发效率。
- Flink SQL 语法增强 支持 CDC 任务、JAR 任务、实时打印表数据、实时数据预览、全局变量增强、语句合并、整库同步等功能,满足多样化需求。
- 多种执行模式适配 支持 FlinkSQL 的多种执行模式:Local、Standalone、Yarn/Kubernetes Session、Yarn Per-Job、Yarn/Kubernetes Application,灵活适应不同环境。
- Flink 生态拓展增强 支持 Connector、FlinkCDC、Table Store 等,增强平台的生态扩展能力。
- FlinkCDC 支持 提供整库实时入仓入湖、多库输出、自动建表和模式演变等功能,简化数据集成过程。
- UDF 开发支持 支持 Flink Java/Scala/Python UDF 开发与自动提交,灵活扩展计算能力。
- 多种 SQL 作业开发支持 支持多种数据库和数据仓库,如 ClickHouse、Doris、Hive、Mysql、Oracle、Phoenix、PostgreSQL、Presto、SqlServer、StarRocks 等,满足各类场景需求。
- 实时在线调试与预览 提供实时在线调试功能,支持 Table、ChangeLog、统计图和 UDF 的实时预览与调试。
- Flink Catalog 与 Dinky 内置 Catalog 增强 支持 Flink Catalog,提供数据源元数据的在线查询与管理,提升数据管理效率。
- SavePoint/CheckPoint 支持 提供自动托管的 SavePoint/CheckPoint 恢复机制,支持最近一次、最早一次、指定一次等恢复方式,确保任务稳定。
- 实时任务运维 支持作业信息、集群信息、作业快照、异常信息、历史版本、报警记录等,协助实时监控与管理。
- 多版本 FlinkSQL Server 和 OpenApi 提供多版本 FlinkSQL Server 支持,具备 OpenApi 能力,便于系统集成与扩展。
- 实时作业报警及报警组 支持多种报警方式(钉钉、微信企业号、飞书、邮箱等),确保及时处理异常。
- 资源管理功能 提供集群实例、集群配置、数据源、报警组、报警实例、文档、系统配置等的管理功能,确保资源高效利用。
- 企业级管理功能 支持多租户、用户、角色、命名空间等管理功能,适应企业规模化需求。
快速开始
1、基于Docker一键快速安装
# 拉取镜像
docker pull dinkydocker/dinky-standalone-server:1.1.0-flink1.17
# 运行程序
docker run -p 8888:8888
--name dinky dinkydocker/dinky-standalone-server:1.1.0-flink1.17
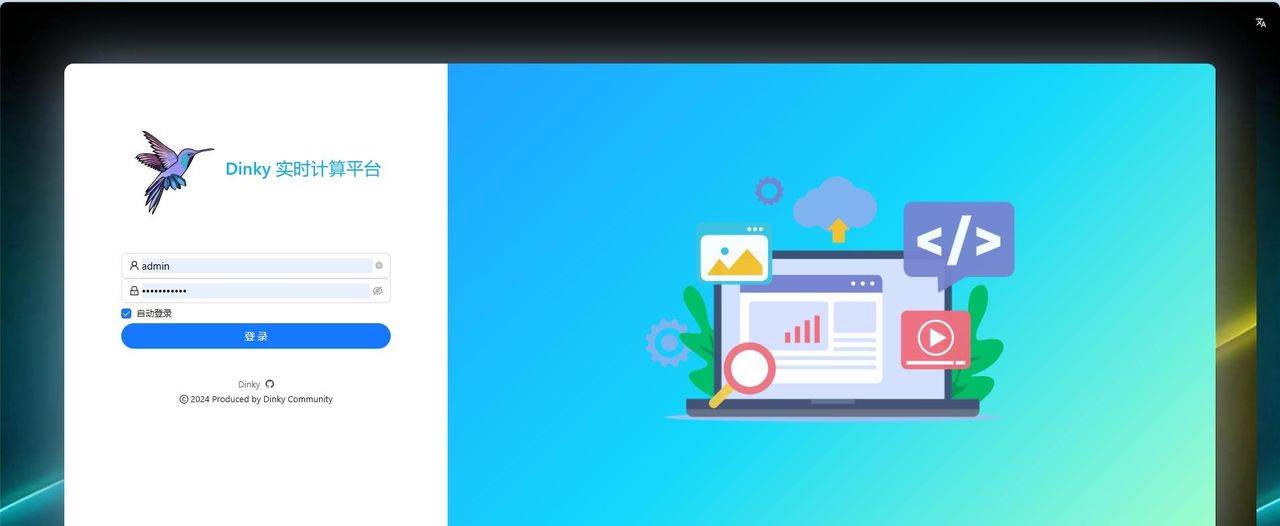
2、Docker启动成功后,在浏览器里输入地址http://ip:8888,看到以下界面,说明Dinky启动成功。
初始账户
用户名: admin
密码 :dinky123!@#
3、创建Flink任务:Dinky支持多种任务开发,示例基于Local模式快速创建一个FlinkSQL任务
4、创建作业:
- 登录Dinky后,进入数据开发页面,点击目录,右键新建作业,选择FlinkSQL作业类型,填写作业名称,点击确定。
- 右侧作业配置页面,执行模式选择Local模式,并行度选择1。
- 输入以下Flink语句:
CREATE TABLE Orders (
order_number BIGINT,
price DECIMAL(32,2),
buyer ROW<first_name STRING, last_name STRING>,
order_time TIMESTAMP(3)
) WITH (
'connector' = 'datagen',
'rows-per-second' = '1',
'number-of-rows' = '50'
);
select order_number,price,first_name,last_name,order_time from Orders

5、预览查询结果
- 点击右上角 预览按钮,会启动local集群并执行任务,下方控制台会实时显示运行日志,提交成功后会切换到结果选项卡,点击 获取最新数据 ,即可查看 Select 语句的执行结果。

6、任务提交:预览功能仅适用于debug,方便开发时查看数据,对于线上作业,我们需要使用执行按钮提交任务到集群。
- 修改FlinkSql语句,点击提交按钮,即可提交任务到集群
--创建源表datagen_source
CREATE TABLE datagen_source(
id BIGINT,
name STRING
) WITH (
'connector' = 'datagen'
);
--创建结果表blackhole_sink
CREATE TABLE blackhole_sink(
id BIGINT,
name STRING
) WITH (
'connector' = 'blackhole'
);
--将源表数据插入到结果表
INSERT INTO blackhole_sink
SELECT
id ,
name
from datagen_source;
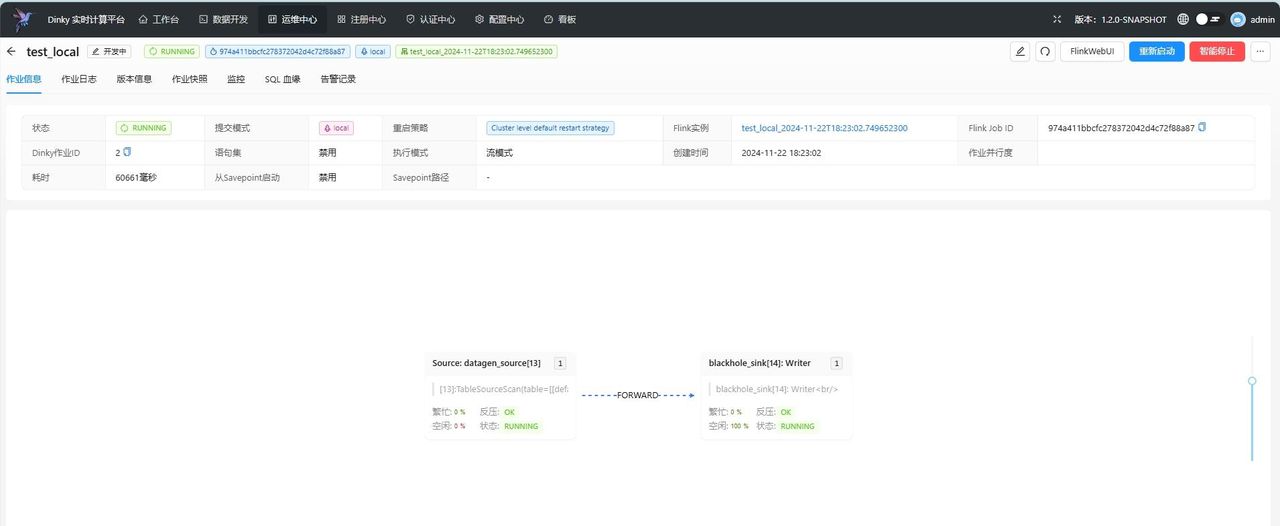
7、作业运维:任务提交成功后,可以进入运维中心页面,找到之前创建的作业,点击详情按钮,即可查看作业的运行状态,日志,监控等信息。

软件&源码获取
关注后 到个人主页置顶的 微头条 获取!
写在最后
1000+优质开源项目更新进度:160/1000。如需更多类型优质项目推荐,请在文章后留言。

如果这篇文章对您有协助, “彦祖们” 必定帮我点个 “关注” 和 “点赞” ,这对我超级重大。我将会继续推荐更多优质项目和新闻
#开源项目精选#
#实时计算#
#程序#
#项目#
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


您必须登录才能参与评论!
立即登录










收藏了,感谢分享