
要使用spaCy处理中文文本,您需要使用适用于中文的spaCy模型。spaCy默认提供了一些预训练的语言模型,但中文一般需要使用其他第三方模型。以下是如何在spaCy中处理中文文本的步骤:
1、安装spaCy: 如果您尚未安装spaCy,请使用以下命令进行安装:
pip install spacy2、安装中文语言模型: spaCy本身并没有提供中文语言模型,您需要安装第三方中文模型。常用的中文模型之一是”Fudan”的中文语言模型,可以使用以下命令进行安装:
pip install zh_core_web_sm3、导入库和加载语言模型: 导入spaCy库并加载已安装的中文语言模型。
import spacy
# 加载中文语言模型
nlp = spacy.load("zh_core_web_sm")4、使用spaCy进行词语分割: 目前,您可以使用spaCy对中文文本进行词语分割。将文本传递给nlp对象,然后使用迭代方式遍历文档中的词语。
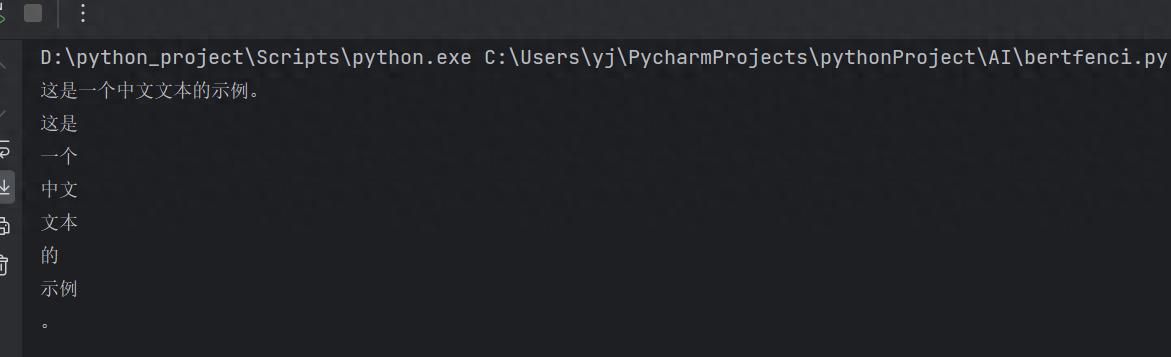
text = "这是一个中文文本的示例。"
# 使用spaCy进行词语分割
doc = nlp(text)
# 遍历文档中的词语
for token in doc:
print(token.text)以上代码会将中文文本分割成词语,并输出每个词语。如果对英文进行分词,只需要将zh_core_web_sm改为en_core_web_sm即可。
请注意,虽然spaCy可以用于中文文本的分词,但其它一些NLP任务,如命名实体识别和句法分析,可能需要更复杂的模型和训练数据。此外,您还可以思考使用其他专门针对中文的NLP工具库,如jieba分词等,以满足特定的任务需求。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


您必须登录才能参与评论!
立即登录








收藏了,感谢分享
和jieba的差异在哪
我们一般用结巴