
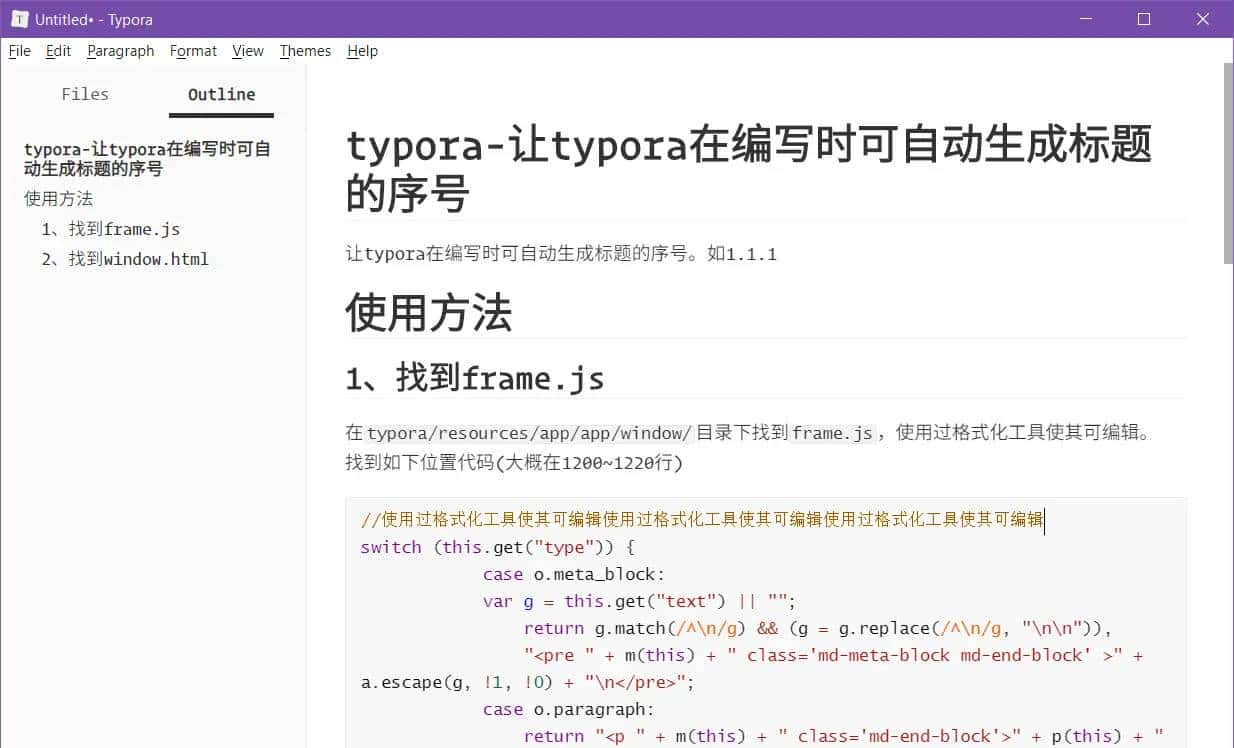
引言
Java 集合是开发中高频使用的核心工具,它替代了数组的局限性,提供了动态存储、高效操作的数据结构解决方案。无论是日常业务开发中的数据处理,还是框架底层的性能优化,掌握集合的原理与用法都是 Java 开发者的必备技能。本文将从集合体系架构出发,拆解核心组件的实现逻辑,结合实战代码示例讲解用法,并附上避坑指南,帮你彻底吃透 Java 集合。
一、Java 集合体系架构(附 SVG 图谱)
Java 集合框架主要分为Collection和Map两大体系,前者存储单个元素的集合,后者存储键值对映射关系。两者均继承自Iterable接口(支持迭代),核心架构如下:

java集合框架体系图
关键说明:
- Iterable:顶层接口,定义迭代器方法iterator(),支持增强 for 循环;
- Collection:存储单个元素的根接口,定义增删改查、遍历等核心方法;
- Map:存储键值对(key-value)的根接口,key 唯一,value 可重复,JDK8 后支持 lambda 遍历。
二、核心组件详解与实战用法
(一)List:有序可重复的元素集合
List 接口的核心特性是元素有序(插入顺序)、可重复、支持索引访问,常用实现类为ArrayList和LinkedList。
1. ArrayList:数组实现的动态列表
- 底层原理:基于 Object 数组实现,初始容量为 10,扩容时默认增长至原容量的 1.5 倍(JDK8);
- 优势:随机访问效率高(get (int index) 时间复杂度 O (1));
- 劣势:插入 / 删除中间元素效率低(需复制数组,O (n));
- 实战用法:
public class ArrayListDemo {
public static void main(String[] args) {
// 1. 初始化(推荐指定初始容量,避免频繁扩容)
List<String> arrayList = new ArrayList<>(20);
// 2. 增删改查
arrayList.add("Java");
arrayList.add("Python");
arrayList.add(1, "Golang"); // 指定索引插入
System.out.println(arrayList.get(0)); // 查:O(1),输出Java
arrayList.set(2, "C++"); // 改
arrayList.remove(1); // 删:删除索引1的元素,后续元素前移
// 3. 遍历(三种方式)
// 方式1:增强for(推荐,简洁)
for (String lang : arrayList) {
System.out.print(lang + " ");
}
// 方式2:迭代器(支持边遍历边删除)
Iterator<String> iterator = arrayList.iterator();
while (iterator.hasNext()) {
String lang = iterator.next();
if ("C++".equals(lang)) {
iterator.remove(); // 安全删除,避免ConcurrentModificationException
}
}
// 方式3:索引遍历(适合需要索引的场景)
for (int i = 0; i < arrayList.size(); i++) {
System.out.println(arrayList.get(i));
}
}
}
2. LinkedList:双向链表实现的列表
- 底层原理:基于双向链表,每个节点存储 prev、next 指针和元素;
- 优势:插入 / 删除首尾元素效率高(O (1)),适合队列 / 栈场景;
- 劣势:随机访问效率低(需从头 / 尾遍历,O (n));
- 实战用法:
public class LinkedListDemo {
public static void main(String[] args) {
LinkedList<String> linkedList = new LinkedList<>();
// 1. 队列操作(先进先出)
linkedList.offer("A");
linkedList.offer("B");
System.out.println(linkedList.poll()); // 出队:A
// 2. 栈操作(后进先出)
linkedList.push("C");
linkedList.push("D");
System.out.println(linkedList.pop()); // 出栈:D
// 3. 首尾访问
System.out.println(linkedList.getFirst()); // 首元素:C
System.out.println(linkedList.getLast()); // 尾元素:B
}
}
(二)Set:无序不可重复的元素集合
Set 接口的核心特性是元素无序、不可重复,通过equals()和hashCode()保证唯一性,常用实现类为HashSet和TreeSet。
1. HashSet:哈希表实现的 Set
- 底层原理:基于 HashMap 实现(存元素到 HashMap 的 key,value 为固定对象),依赖哈希算法;
- 优势:增删查效率高(O (1),哈希冲突少时);
- 注意:元素需重写equals()和hashCode(),否则无法保证唯一性;
- 实战用法:
public class HashSetDemo {
public static void main(String[] args) {
// 存储自定义对象,必须重写equals和hashCode
Set<User> userSet = new HashSet<>();
userSet.add(new User("张三", 20));
userSet.add(new User("张三", 20)); // 重复元素,不会插入
userSet.add(new User("李四", 22));
System.out.println(userSet.size()); // 输出2
// 遍历(无索引,支持增强for和迭代器)
for (User user : userSet) {
System.out.println(user.getName() + ":" + user.getAge());
}
}
static class User {
private String name;
private int age;
// 构造器、getter省略
// 重写equals和hashCode(IDEA自动生成)
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
User user = (User) o;
return age == user.age && Objects.equals(name, user.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}
}
2. TreeSet:有序 Set(可排序)
- 底层原理:基于 TreeMap 实现,依赖红黑树(平衡二叉搜索树);
- 特性:元素自动按自然顺序或自定义比较器排序;
- 实战用法:
public class TreeSetDemo {
public static void main(String[] args) {
// 1. 自然排序(String默认按字典序)
Set<String> treeSet1 = new TreeSet<>();
treeSet1.add("banana");
treeSet1.add("apple");
treeSet1.add("cherry");
System.out.println(treeSet1); // 输出[apple, banana, cherry]
// 2. 自定义排序(按年龄升序)
Set<User> treeSet2 = new TreeSet<>(Comparator.comparingInt(User::getAge));
treeSet2.add(new User("张三", 25));
treeSet2.add(new User("李四", 20));
treeSet2.add(new User("王五", 22));
for (User user : treeSet2) {
System.out.println(user.getName() + ":" + user.getAge());
// 输出:李四:20 王五:22 张三:25
}
}
}
(三)Map:键值对映射集合
Map 接口存储key-value 映射,key 唯一(重复会覆盖),value 可重复,常用实现类为HashMap和TreeMap。
1. HashMap:哈希表实现的 Map(JDK8 核心优化)
- 底层原理:JDK8 前为 “数组 + 链表”,JDK8 后为 “数组 + 链表 + 红黑树”(链表长度≥8 时转红黑树,≤6 时退化为链表);
- 关键参数: 初始容量:16(必须是 2 的幂); 负载因子:0.75(容量达到 16*0.75=12 时扩容为 32);
- 实战用法:
public class HashMapDemo {
public static void main(String[] args) {
// 1. 初始化(指定初始容量和负载因子,优化性能)
Map<String, Integer> hashMap = new HashMap<>(16, 0.75f);
// 2. 增删改查
hashMap.put("Java", 100);
hashMap.put("Python", 95);
hashMap.put("Java", 98); // 覆盖原value
System.out.println(hashMap.get("Python")); // 查:95
hashMap.remove("Python"); // 删
// 3. 遍历(四种方式,推荐前两种)
// 方式1:遍历key-value(最常用)
for (Map.Entry<String, Integer> entry : hashMap.entrySet()) {
System.out.println(entry.getKey() + ":" + entry.getValue());
}
// 方式2:lambda遍历(JDK8+)
hashMap.forEach((key, value) -> System.out.println(key + ":" + value));
// 方式3:遍历key
for (String key : hashMap.keySet()) {
System.out.println(key);
}
// 方式4:遍历value
for (Integer value : hashMap.values()) {
System.out.println(value);
}
}
}
2. TreeMap:有序 Map
- 底层原理:基于红黑树实现,key 按自然顺序或自定义比较器排序;
- 适用场景:需要按 key 排序的场景(如排行榜);
- 实战用法:
public class TreeMapDemo {
public static void main(String[] args) {
// 自定义比较器:按key长度降序
Map<String, Integer> treeMap = new TreeMap<>((k1, k2) -> k2.length() - k1.length());
treeMap.put("Java", 100);
treeMap.put("Python", 95);
treeMap.put("C", 90);
// 遍历:按key长度降序输出
treeMap.forEach((key, value) -> System.out.println(key + ":" + value));
// 输出:Python:95 Java:100 C:90
}
}
三、实战避坑指南与性能优化
(一)常见坑点
- ConcurrentModificationException 异常:
- 缘由:遍历集合时直接调用remove()(增强 for 循环中不允许);
- 解决方案:用迭代器iterator.remove()或 JDK8 + 的removeIf()。
- HashMap 线程不安全:
- 问题:多线程下 put 可能导致死循环(JDK7)或数据丢失(JDK8);
- 替代方案:用ConcurrentHashMap(高效并发)或Hashtable(全锁,低效)。
- 集合判空用 isEmpty () 而非 size ()==0:
- 理由:isEmpty()直接返回布尔值,size()可能需计算(部分集合),效率更高。
(二)性能优化技巧
- 初始化时指定容量:
- ArrayList、HashMap 等集合,若能预估大小,初始化时指定容量(如new ArrayList<>(100)),避免频繁扩容。
- 优先用 ArrayList 而非 Vector:
- Vector 是线程安全的,但每个方法都加锁,性能差;需并发时用CopyOnWriteArrayList。
- HashMap key 选择不可变对象:
- 如 String、Integer,避免 key 的 hashCode 变化导致无法找到 value。
- 大数据量查询用 LinkedHashMap:
- 需保持插入顺序或实现 LRU 缓存时,用 LinkedHashMap(比 HashMap 多维护双向链表,性能略低但满足顺序需求)。
四、总结与拓展
Java 集合框架是数据处理的核心工具,选择合适的集合需遵循 “按需匹配” 原则:
- 需有序可重复、随机访问 → ArrayList;
- 需频繁插入删除首尾 → LinkedList;
- 需去重、高效查询 → HashSet;
- 需排序的集合 → TreeSet/TreeMap;
- 需键值对、高效并发 → ConcurrentHashMap。
拓展学习:
- JDK8 新增集合:Stream API(集合流式处理)、Optional(避免空指针);
- 高性能集合:Google Guava 的ImmutableList(不可变集合)、Multimap(多值 Map)。
掌握集合的原理与用法,能大幅提升代码效率与可读性。提议结合源码深入学习(如 HashMap 的 put 流程、TreeSet 的红黑树实现),真正做到知其然且知其所以然。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...





