
论文链接:https://arxiv.org/abs/2312.03818
作者: Zeyi Sun, Ye Fang, Tong Wu, Pan Zhang, Yuhang Zang, Shu Kong, Yuanjun Xiong, Dahua Lin, Jiaqi Wang
单位:上海交通大学, 复旦大学, 香港中文大学, 上海人工智能实验室, 澳门大学, MThreads, Inc.
github地址:https://aleafy.github.io/alpha-clip
背景:
CLIP模型因其强劲的图像-文本对齐能力而被广泛应用,但其局限性在于对图像中目标的区域级别关注不足。传统方法多通过裁剪、后处理(如ROI Pooling)提取区域特征,容易丢失上下文信息或导致特征不够精细。Alpha-CLIP通过引入Alpha通道,增强了CLIP在区域级别任务中的表现。Alpha-CLIP: A CLIP Model Focusing on Wherever You Want” 提出了一种新的图像理解框架,能够在各种任务中准确地聚焦于用户指定的区域。
一句话:在CLIP模型的基础上附加的Alpha 通道使其能够对特定图像区域进行精准关注,并在多个下游任务中表现出显著的性能提升。
这是通过构建数百万的RGBA区域-文本对来实现的,其中RGBA代表了红、绿、蓝和alpha通道,alpha通道用于指示图像中的透明区域,即模型需要关注的区域。
模型
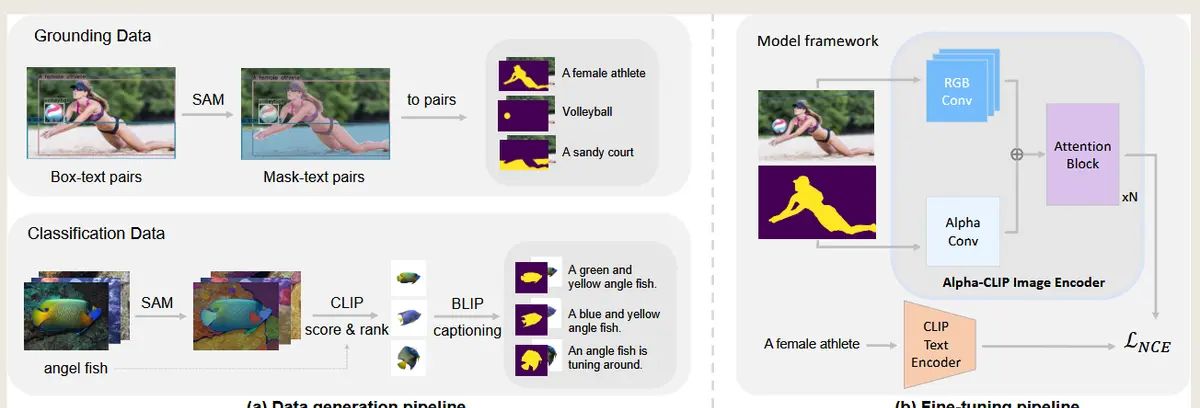
如何构建数据集的?
Alpha-CLIP的数据生成策略依赖于现有工具(如SAM和BLIP),通过构造RGBA区域-文本对数据来增强模型的区域感知能力。
(1) Grounding Data(区域定位数据)
这部分自然图像来自 GRIT 数据集 [36],该数据集采用GLIP 和 CLIP 自动提取框区域-文本对的标签。
在 GRIT 的基础上,我们进一步生成掩模区域-文本对。具体来说,我们使用 SAM [19] 为每个box region自动生成高质量的伪掩模。
(2) Classification data pipeline(分类数据)
该分支用于生成区域文本对,其中前景对象被突出显示,而原始背景被移除。
使用ImageNet [6] 数据集。第一,我们使用 SAM 为 ImageNet 中的每张图像自动生成多个masks。随后,我们裁剪每个mask的前景对象,将其居中并放大。
后使用 CLIP 计算每个掩模所属图像的相应类标签的分数。接下来,我们根据分数按类别对面具进行排序,并选择分数最高的排名靠前的面具。
然后我们使用 BLIP-2 [25] 用captions来注释这些masks。
如何进行模型训练的?Model framework

Alpha-CLIP在传统的CLIP图像编码器(基于ViT结构)的基础上,引入了一个并行的Alpha卷积层(Alpha Conv),以支持Alpha通道的输入。
(a) Alpha卷积层(Alpha Conv Layer)
并行设计:
在CLIP图像编码器的第一层(RGB卷积层)中,增加了一个专门用于处理Alpha通道的卷积层,称为Alpha Conv。
这个Alpha Conv层与RGB Conv层是并行的,两者分别处理图像的RGB通道和Alpha通道。
Alpha通道的输入范围:
Alpha通道的输入值范围为[0,1]:
值为1表明前景(Foreground),模型需要重点关注的区域。
值为0表明背景(Background),权重较低的区域。
Alpha Conv的初始化:
为了保留CLIP模型的先验知识,Alpha Conv的权重初始值被设置为全零。
这种初始化确保了模型在初始状态下完全忽略Alpha通道的输入,仅依赖RGB通道的特征提取。
(b) Transformer结构的调整
后续处理:
RGB Conv和Alpha Conv生成的特征会在后续的Transformer层中进行融合,通过注意力机制(Attention Block)学习RGB和Alpha特征的交互关系。
这种设计使模型能够同时关注全局图像信息和局部区域信息。
学习率控制:
在训练过程中,为了避免对CLIP原有的全局特征提取能力造成破坏:
第一层Alpha卷积层使用较高的学习率。
Transformer层使用较低的学习率,以微调全局特征融合。
实验结果
(a) 数据来源
GRIT-20M:用于生成RGBA区域-文本对数据,主要用于ImageNet的零样本分类任务。
ImageNet:结合ImageNet生成了46万对RGBA区域-文本对,用于分类任务。
(b) 数据生成方法
通过SAM自动生成目标区域的分割掩码,并结合BLIP生成区域的文本描述。
数据类型包括:
全图特征数据:RGB图像设置Alpha值为全1,用于全局特征的学习。
区域特征数据:RGBA区域-文本对,专注于目标区域的感知
主要是对图像识别,大模型,图像变化,3D对象生成这三个部分进行了实验分析,详细结果看论文吧。
直接替换原始的CLIP为alpha-Clip就可以.
Alpha-CLIP in Image Recognition
Alpha-CLIP in MLLM
Alpha-CLIP in image variation
Alpha-CLIP in 3D Object Generation
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...





